著:クロスファンクショングループ プロダクトマーケティング室
インフラソリューション推進部 菅 博
ディスクの空き領域を確保するための別な方法は、データの圧縮やデータ間の冗長ブロックの排除を行うことです。圧縮の技術は古くからありましたが、アプリケーションから見て透過的な技術も出てきており、ブロックレベルでの重複除外による容量最適化は比較的新しい技術です。ここでは、圧縮と重複除外の技術について解説します。
データ圧縮
zip形式のデータ圧縮はかなり古くから存在しており、ユーザーが個人で使用できる領域を効率よく使うのに良く用いられています。しかし、圧縮したファイルをアプリケーションから利用する場合には、事前に圧縮ファイルを解凍する必要があり、圧縮データはアプリケーションから見て透過的ではありません。また、圧縮ファイル自身のサイズが大きい場合に、解凍するための一次領域が足りないという事も起こり得ます。
テープドライブのようにストリーム形式のデータであれば、テープドライブが書き込み時に圧縮、読み込み時に解凍を行うことで、データを読み出すアプリケーションやコマンドからは完全に透過的になっています。ファイル単位でのアクセスではこうした事が困難とされていましたが、最近になってファイル単位のアクセスでもアプリケーションに対して透過的な圧縮を行う装置なども出てきました。
このようなアプライアンスは、ファイルサーバとクライアントの間に介在して、ファイル単位のアクセスに対して透過的にデータの圧縮と伸張(解凍)を行います。NASの通信プロトコルであるCIFSやNFSの通信パケットのペイロード(データ部)にのみ圧縮と伸張を行うことによって、ファイルサイズだけを縮小して全体のファイルシステム構造には全く影響を与えません。また、圧縮と伸張の部分はアプライアンスが行うので、クライアントやファイルサーバのCPUには負荷をかけないのも特長です。
シングル・インスタンス
ストレージの中には、実は全く同じファイルが複数存在している場合が少なくありません。各個人が何らかの理由で手元にコピーしてきものや、メール配信などのように複数の人間に同一の内容が配信された結果、複数の人間が全く同じ物を所有しているなど、原因は様々です。すでに説明したSRMのソフトなどでストレージの解析を行うと、重複ファイルが実は非常に多いことがわかります(ファイルサーバの1割は重複ファイルと考えてもかまいません)。
全く同様のファイルを書き込む事になった場合に、ファイルとしては別個なものとして管理しますが、内容はすでに記憶している領域を参照することで容量を最適化する技術をシングル・インスタンスと呼びます。
少し前まで、シングル・インスタンスとか重複除外と言う場合にはファイル単位でしたが、近年になって重複の単位をストレージの管理ブロック単位にまで縮小することで、より効率的に重複除外を行う技術と製品も出てきました。ファイル単位の重複除外をシングル・インスタンスと呼び、ブロックレベルでの重複除外を「De-Dup(lication):ディデュープと発音」と呼ぶ場合があります。
重複除外
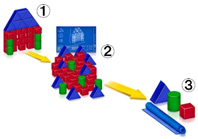
図1
左の図は重複除外の仕組みをイメージ化したものです。①はオリジナルのバックアップデータを表しています。それらがストレージに書き込まれる時になされる処理を②が示していますが、重複除外機能はそれらをブロック分割しながら全くユニークなブロックと重複ブロックとの判別を行います(基本的にハッシュ関数を使用)。これにより、今回の場合には実際のバックアップデータは三つのユニークなブロックしか含まれないことがわかったので、ユニークなブロックの実体とバックアップデータ全体を復元するのに必要な設計図のみを格納します(③)。
今後書き込まれるデータの中に、これら3つのブロックが含まれていれば、それらは冗長ブロックとして認識されて、ブロックの位置情報のみを記憶するにとどめます。このようにして、読み出し要求時には以前に書き込んだブロックを参照することにより、容量を最適化しながらも全てのデータを完全なイメージに復元して送信することが可能になっています。
コラム一覧のページに戻り、続きをお読み下さい。