Apache Iceberg Tablesを活用してストリームデータを格納する
投稿日: 2025/03/12
はじめに
こんにちは、稲守です。
「大量のIoTデータやログをリアルタイムで取り込みつつ、高速クエリや柔軟なデータ管理も実現したい」
このような課題をお持ちではありませんか?Apache Icebergは注目を集めていますが、具体的な実装方法や実用的なユースケースは情報が限られています。
本記事では、Amazon Data FirehoseとApache Icebergを組み合わせた実践的なストリームデータ管理パイプラインを構築します。IoTデバイスのログデータを例に、シンプルでありながら拡張性の高いアーキテクチャを実装する方法を、ステップバイステップで解説します。
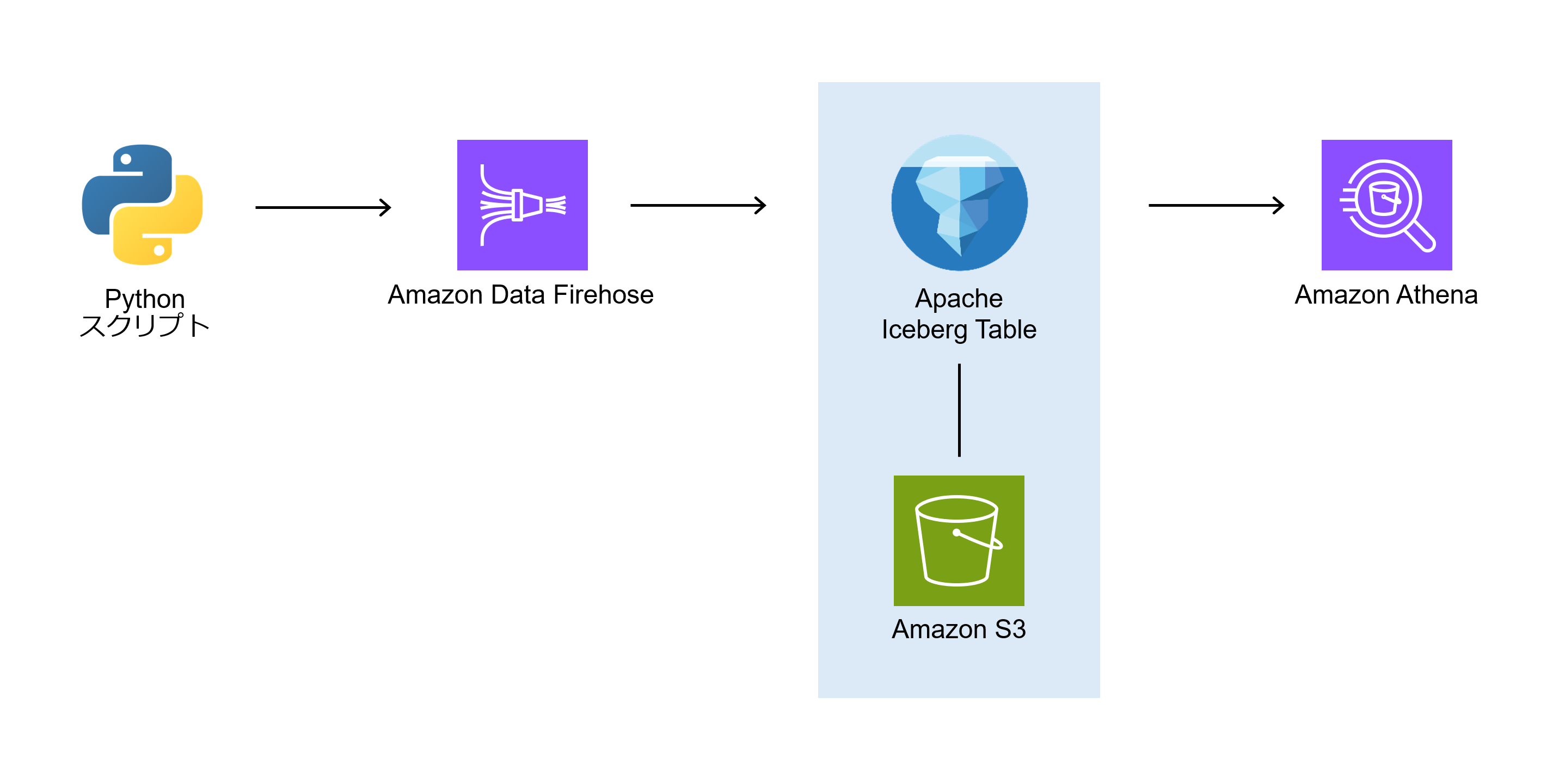
今回の構成
Pythonスクリプトでログを生成 → Amazon Data Firehose → Apache Iceberg → Athenaで検索 という構成で紹介します。
STEP 1: 日付パーティション対応のIceberg Tableを設計する
AthenaでIcebergテーブルを作成します。(デバイスの移動ログデータを受信する想定のテーブルです) パーティションは、day(ts)のパーティション変換関数をevent_timeカラムに適用して、日付単位のパーティションを指定します。パーティション用のカラムを作成しなくてもよいのがIcebergテーブルの利点です。
day(), hour(), month(), year()など)を使用すると、既存カラムから自動的にパーティション値が生成され、データ効率とクエリパフォーマンスが向上します。
CREATE TABLE iceberg_database.device_activity_logs (
event_id STRING,
event_time TIMESTAMP,
device_id STRING,
latitude DOUBLE,
longitude DOUBLE,
user_id STRING
)
PARTITIONED BY (
day(event_time)
)
LOCATION 's3://amzn-s3-demo-bucket/iceberg_database/device_activity_logs/'
TBLPROPERTIES (
'table_type' = 'ICEBERG',
'optimize_rewrite_delete_file_threshold' = '10'
)
STEP 2: データ取り込みパイプラインを構築する
Amazon Data Firehoseのストリームを作成しましょう。
事前準備として、配信に失敗したときのためのバックアップ配信バケットとストリームが使用するロールを作成しておきます。
バケットの作成
バックアップ配信バケット: amzn-s3-buckup-bucketを作成します。
ロールの作成
次に公式ドキュメント(https://docs.aws.amazon.com/firehose/latest/dev/controlling-access.html#using-iam-iceberg)のポリシー設定から今回は使用しないKMSとLambdaの許可を外して、簡易的なポリシーを作成します。
信頼関係
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "firehose.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシー
{
"Version": "2012-10-17",
"Statement":
[
{
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:GetDatabase",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:<region>:<aws-account-id>:catalog",
"arn:aws:glue:<region>:<aws-account-id>:database/*",
"arn:aws:glue:<region>:<aws-account-id>:table/*/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::amzn-s3-demo-bucket",
"arn:aws:s3:::amzn-s3-demo-bucket/*"
]
},
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards"
],
"Resource": "arn:aws:kinesis:<region>:<aws-account-id>:stream/*"
},
{
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:<region>:<aws-account-id>:log-group:*:log-stream:*"
]
},
]
}
ストリーム作成
ではAmazon Data Firehoseのコンソールからストリームを作成していきましょう。
ソースと送信先を選択
ソースに、Direct PUTを指定します。 送信先は、Apache Iceberg テーブルを使用します。

Firehose ストリーム名
Firehose ストリーム名はput-device-activity-logsとします。

レコードを変換
レコード変換オプションは指定しません。

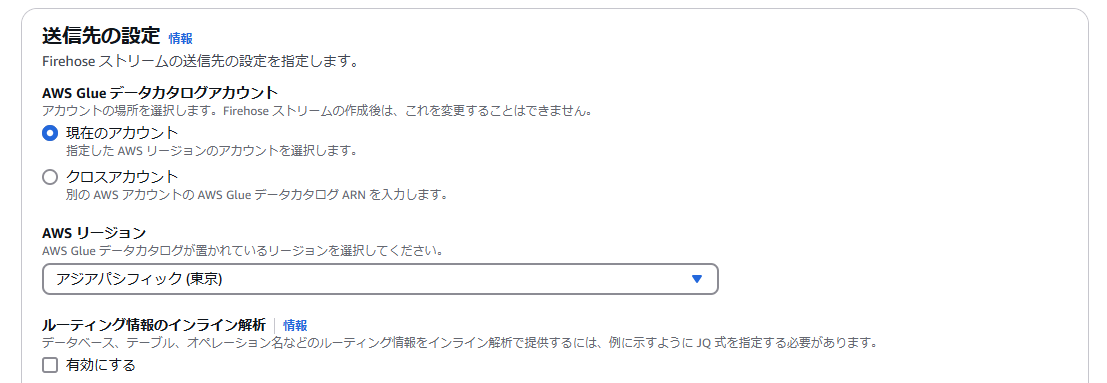
送信先の設定
AWS Glue データカタログアカウント 現在のアカウントを指定します。
AWSリージョンは任意のリージョンを指定します。
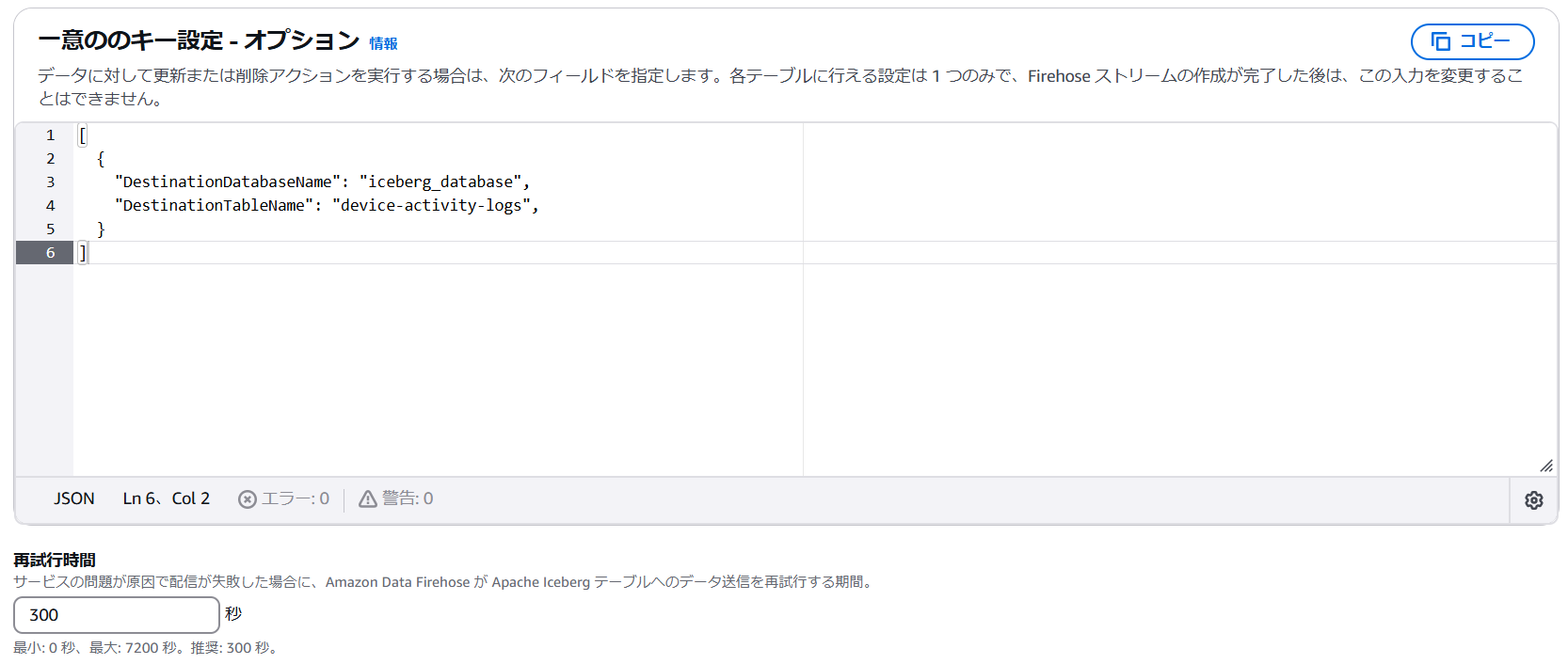
一意のキー設定
今回はログをINSERTするだけの想定のため、ユニークキーの指定はしません。
[
{
"DestinationDatabaseName": "iceberg_database",
"DestinationTableName": "device-activity-logs",
}
]
再試行時間はデフォルトのままとします。
再試行時間およびバッファのヒント
デフォルトのままにします。
バックアップの設定
Amazon S3のソースレコードのバックアップはデフォルトのままとします。 S3バックアップバケットで事前準備で作成したバケットを指定します。

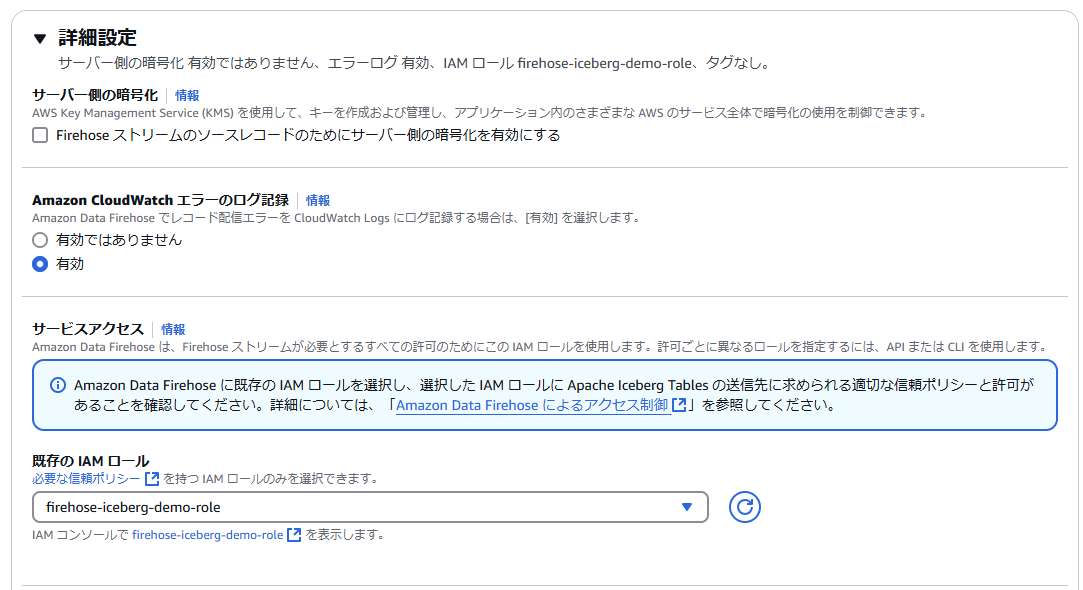
詳細設定
既存のIAMロールに事前準備で作成したIAMロールを指定します。 その他はデフォルトのままとします。
Firehose ストリームを作成
Firehose ストリームを作成ボタンをストリームを押して作成します。
STEP 3: デバイスログデータの生成とリアルタイム取り込みを実装する
ストリームに書き込むPythonプログラムの作成
Firehose ストリームが出来たのでストリームにデータをPUTするPythonプログラムを作成します。 ユーザーが共有で利用するデバイスの緯度経度のデータをFirehoseのput_record_batchを使用して1秒間に1000レコードを送信します。
# put-device-activity-logs.py
import boto3
import uuid
import random
import json
import time
import datetime
# Firehose クライアントの設定
firehose = boto3.client(
'firehose',
region_name='ap-northeast-1' # 東京リージョン
)
# 設定パラメータ
DELIVERY_STREAM_NAME = 'put-device-activity-logs' # Firehose ストリーム名
DEVICE_COUNT = 1000 # デバイスの数
USER_COUNT = 5000 # ユーザーの数
RECORDS_PER_SECOND = 1000 # 1秒あたりのレコード数
BATCH_SIZE = 500 # 一度に送信するバッチサイズ
# 東京周辺の緯度経度の範囲
TOKYO_LAT_MIN, TOKYO_LAT_MAX = 35.50, 35.80
TOKYO_LON_MIN, TOKYO_LON_MAX = 139.50, 139.90
# デバイスIDを事前生成
device_ids = [str(uuid.uuid4()) for _ in range(DEVICE_COUNT)]
# user_idを「user_0」〜「user_4999」の形式で生成
user_ids = [f"user_{i}" for i in range(USER_COUNT)]
def main():
# 初期タイムスタンプ (現在時刻から開始)
base_timestamp = datetime.datetime.now()
total_records_sent = 0
batch_records = []
print("データ生成開始: 秒間1000レコードの送信")
# 無限ループでデータを生成し続ける(Ctrl+Cで終了)
while True:
# デバイスごとに30秒間隔でデータを生成
for device_index, device_id in enumerate(device_ids):
# 現在の時間枠(30秒単位)を計算
time_frame = total_records_sent // DEVICE_COUNT
timestamp = base_timestamp + datetime.timedelta(seconds=30 * time_frame)
# イベント生成
event = {
'event_id': str(uuid.uuid4()),
'event_time': timestamp.isoformat(),
'device_id': device_id,
'latitude': random.uniform(TOKYO_LAT_MIN, TOKYO_LAT_MAX),
'longitude': random.uniform(TOKYO_LON_MIN, TOKYO_LON_MAX),
'user_id': random.choice(user_ids)
}
batch_records.append(event)
total_records_sent += 1
# バッチサイズに達したらデータを送信
if len(batch_records) >= BATCH_SIZE:
encoded_records = [{'Data': json.dumps(record)} for record in batch_records]
firehose.put_record_batch(
DeliveryStreamName=DELIVERY_STREAM_NAME,
Records=encoded_records
)
print(f"送信完了: {len(batch_records)}レコード, 合計: {total_records_sent}レコード")
batch_records = []
# レート制御(秒間500レコードを維持)
time.sleep(len(encoded_records) / RECORDS_PER_SECOND)
if __name__ == "__main__":
main()
コードのポイント解説
BATCH_SIZE = 500: Firehoseのput_record_batch APIは1回の呼び出しで最大500レコードまで対応しています。これを最大化することでAPIコール数を減らし、スループットを向上させています。
RECORDS_PER_SECOND = 1000: レート制御により、Firehoseの制限内でデータを安定して送信します。
Firehose ストリームへデータを送信
さてローカルPCから実行してみます。
$ python put-device-activity-logs.py
データ生成開始: 秒間1000レコードの送信
送信完了: 500レコード, 合計: 500レコード
送信完了: 500レコード, 合計: 1000レコード
送信完了: 500レコード, 合計: 1500レコード
送信完了: 500レコード, 合計: 2000レコード
送信完了: 500レコード, 合計: 2500レコード
送信完了: 500レコード, 合計: 3000レコード
送信完了: 500レコード, 合計: 3500レコード
...
送信できています。
Athenaから登録されたデータを確認
Athenaのクエリエディタからログが参照できるか確認してみましょう。 Data Firehoseではデータがバッファリングされて出力されるので、ログを送信し始めてから5分程度待ってから確認します。
-- クエリエディタ
select * from iceberg_database.device_activity_logs
うまく行きました! Firehoseの設定が問題なければレコードが増えていくのが確認できると思います。
後片付け
pythonのプログラムが実行中なので、CTRL+Cで停止させます。
まとめと次のステップ
本記事では、Apache IcebergとAmazon Data Firehoseを組み合わせた、ストリームデータの効率的な取り込みと管理方法を実装しました。この構成により、以下のメリットが得られます:
- シームレスなデータ取り込み: コーディング作業を最小限に抑えた効率的なデータパイプライン
- スケーラブルな設計: 数百万レコード/秒まで対応可能なアーキテクチャ
- クエリ効率の最適化: パーティショニングによる高速な分析クエリの実現
- 拡張性: 将来的なデータスキーマの進化に柔軟に対応
次回:データガバナンスとコンプライアンス対応
次回は、今回のテーブル構成を元にしてユーザーIDベースのパーティショニングを追加することで、特定ユーザーのデータ削除を高速かつ効率的に実行する方法を解説します。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。
