Papermill環境でAmazon SageMaker Processing Jobを動かしてみた
投稿日: 2025/03/17
はじめに
こんにちは、伊藤忠テクノソリューションズ 阪本です。
データ処理やモデル評価の作業を実行するときに、本番環境を作成し、どのような挙動を示すか一連の流れを確認すると思います。ただ、まだ動作検証段階で本番環境を何度も作成するのは効率的ではありません。また、Jupyter Notebookはデータ分析や機械学習モデル開発のための主要ツールとして広く活用されています。これらのノートブックを、本番環境で定期的な実行やバッチ処理を行う際に、手動操作で実行することは現実的ではありません。
この問題を解決するのが、Amazon SageMaker Processing Jobとノートブック実行ツールのPapermillの組み合わせです。本記事では、この二つを活用してJupyter Notebookを自動的にバッチ処理する方法を、シンプルなコード例を交えながら解説します。
1.全体概要
今回のシナリオの全体概要は以下のようになっています。Papermillを使用できるコンテナイメージの環境でProcessing処理を行います。Processing処理の中では、notebook実行が内部で行われ、各処理結果がS3に保存されます。
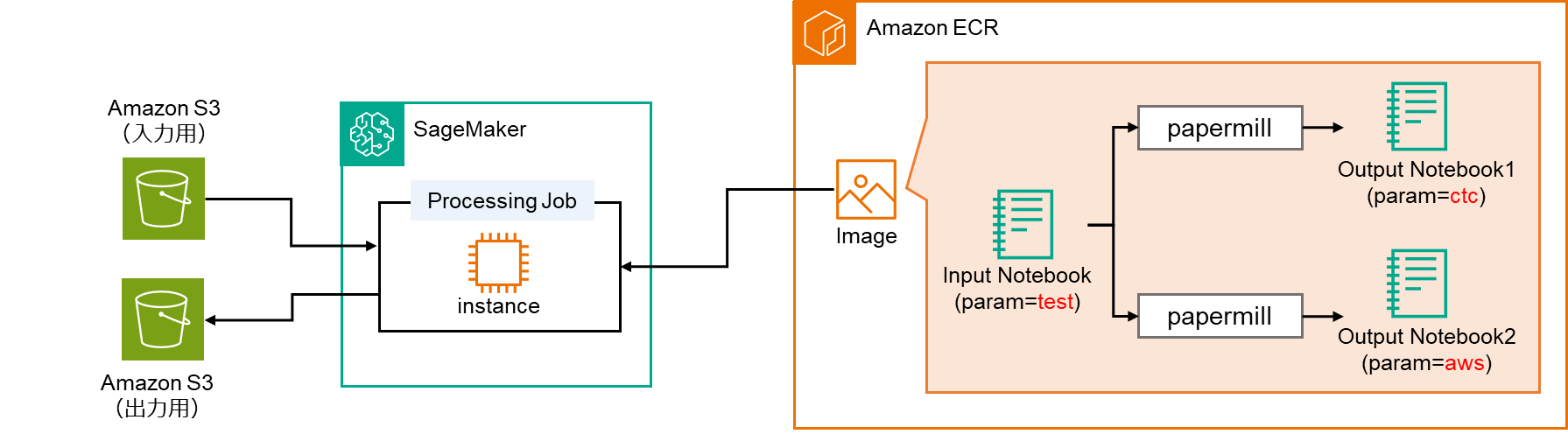
2.Amazon SageMaker Processing Job
SageMaker Processing Jobは、AWSもしくは独自のコンテナ上で処理を実行し、処理が完了するとインスタンスが自動で停止されるジョブサービスです。通常のSageMaker学習ジョブとは異なり、モデルの学習以外の様々なデータ処理タスクやLambdaで扱えない複雑な処理に適しています。
主な特徴としては、以下となります。
- 一時的な環境起動: ジョブ実行中のみリソースが起動され、終了後は自動的にシャットダウンします
- スケーラビリティ: データ量に応じてリソースを柔軟に調整できます
- コスト効率: 使用した分のみの課金で、常時環境を維持する必要がありません
- 環境の一貫性: 同じコンテナ環境を使用するため、再現性が高まります
Processing Jobは、指定されたコンテナイメージを使って処理環境を構築し、S3からデータを取得して処理を実行します。カスタムイメージを使用することで本番環境のコンテナや本番データを使って、動作検証が簡単に行えます。
処理が完了すると、結果をS3に保存し、環境を終了します。これにより、「データの取得」→「処理」→「結果の保存」という一連のワークフローを実現できます。
3.Papermill
Papermillは、Jupyter Notebookをパラメータ化して実行するPythonライブラリです。通常、Jupyter Notebookはインタラクティブに実行するものですが、Papermillを使うことで、コマンドラインやPythonプログラムからノートブックを実行できるようになります。下図はPapermillによるNotebook処理の例を示しています。

Papermillの主な機能として、以下のような機能があります。
- パラメータ変更: 外部からノートブックにパラメータを渡すことができます
- バッチ実行: ノートブックをバッチ単位で実行できます
- 出力保存: 実行結果を新しいノートブックとして保存します
※Papermillの詳細については以下をご参照ください。
https://papermill.readthedocs.io/en/latest/
4.コンテナイメージの作成
では、実際にProcessing Jobの挙動を見ていきましょう。今回は通常のPython環境に加え、Papermillを使用できる環境でProcessing処理を行うことを目指していきます。
まず準備として、Processing Jobの実行環境となるコンテナイメージを作成します。
SageMaker Studioをセットアップします。こちらの記事に従って、セットアップしてみてください。
次にSageMaker Processing Jobでノートブックを実行するために、Papermillを含むカスタムコンテナイメージが必要です。SageMaker Studioをセットアップ後、下記の記事を参考に、SageMaker内からコンテナイメージをECRに作成もしくは保存してください。
SageMakerによるカスタムイメージ構築とStudioへのコンテナ適用
今回、カスタムイメージ作成に必要なDockerfileは以下で定義しています。
FROM python:3.11-slim-buster
RUN python -m pip install --upgrade pip
RUN python -m pip install -U jupyter jupyter-client ipykernel
RUN python -m pip install -U 'papermill[all]'
5.Processing Jobの準備と実行
Papermill環境でのProcessing Job実行は主に次の4ステップで進めます:
0. IAMロール設定
1. Papermill用Notebookの作成
2. Papermill実行ファイルの作成
3. Processing Jobの実行
4. 実行結果の確認
前章でも述べたように、4.で作成済みのPapermill実行環境を活用し、Processing Jobでの処理を行う様子を解説します。これらのステップを順番に詳しく見ていきましょう。
⓪ IAMロール設定
Processing Jobを扱う上でSageMaker、ECR、S3に関するIAM権限が必要となります。今回はSageMakerのユーザプロファイルに付与されているIAMロールを使用します。別途IAMロール権限が必要な場合は以下をご参照ください。
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/build-and-manage-access.html
① Papermill実行用ファイルの作成
次に、Papermillで実行するためのNotebookファイルを作成します。本記事では例として、テキストファイルの作成処理をNotebookで行います。具体的には、任意のテキストファイル名とファイルに書き込む処理を行う形です。
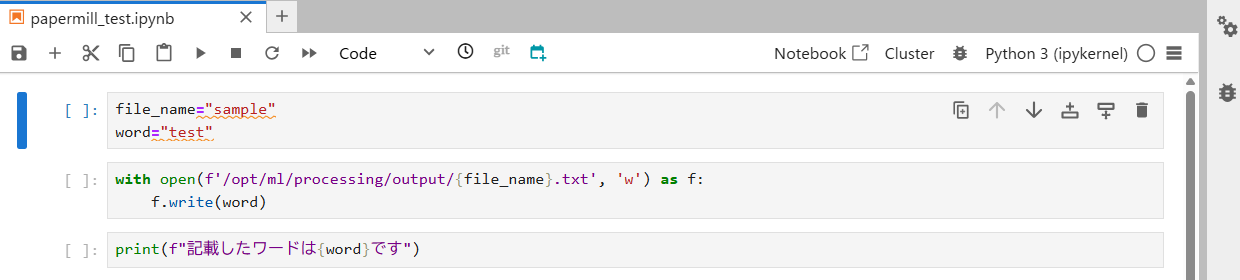
今回、Papermillにより変更されるパラメータ(変数)の対象は「file_name」と「word」になります。これをPapermill実行時に変更できるよう、タグ付けを行う必要があります。
まず、JupyterLabの右のメニューにある「Property Inspector(歯車マーク)」をクリックします。そして、Add Tagの中に「parameters」と記載し、+ボタンを選択します。
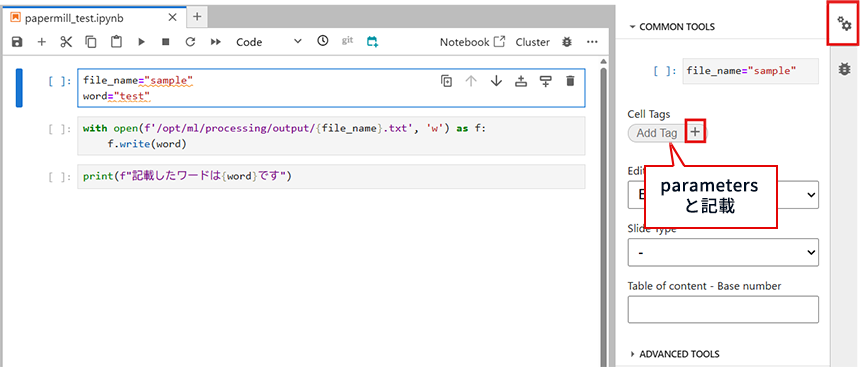
すると、parametersのタグが付与されるので、Notebookの保存をしましょう。これでまずNotebookの準備ができました。
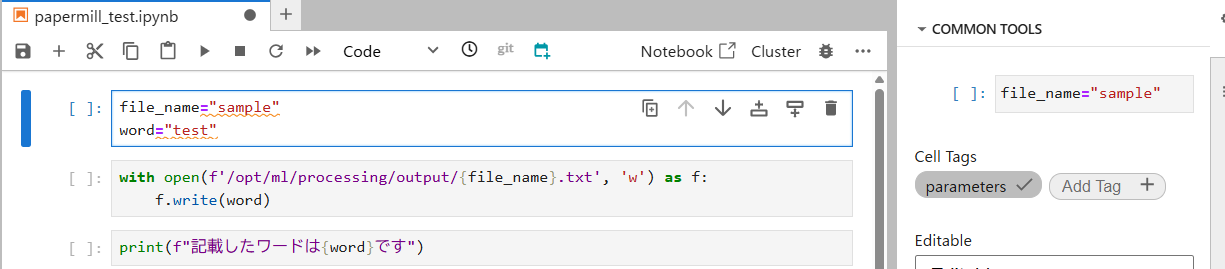
② Papermill実行ファイルの作成
次に、①で作成したNotebookをPapermillで実行するためにpythonファイルを作成しましょう。作成するpythonファイルは以下となります。
import papermill as pm
# papermillで実行(ファイル名に変換ctc_sample.txt)
pm.execute_notebook(
'/opt/ml/processing/input/papermill_test.ipynb',
'/opt/ml/processing/output/output1.ipynb',
parameters=dict(file_name='ctc_sample', word='ctc')
)
# papermillで実行(ファイル名に変換aws_sample.txt)
pm.execute_notebook(
'/opt/ml/processing/input/papermill_test.ipynb',
'/opt/ml/processing/output/output2.ipynb',
parameters=dict(file_name='aws_sample', word='aws')
)
今回は1.で作成したNotebookのファイル名と記載内容を変えて、同時に2つのNotebookを実行し、2つのテキストファイルとNotebookを出力させます。
※上記のコードでは、parametersで定義される変数が、Notebookでタグ付けした「parameters」と一致するように設定する必要があります。
③ Processing Jobの実行
ここで本題となるProcessing Jobを行います。今回はProcessing JobをSageMakerのJupyterLab内で実行していきます。
まず、①と②で作成したNotebookとpythonファイルをS3にアップロードします。新しくNotebookを作成し、以下コマンドを実行してください。
※バケットとプレフィックスは適宜入力をお願いします
# 格納するバケットとプレフィックスを定義
bucket = <your-bucket-name>
key_prefix = <your-prefix>
s3_prefix = f's3://{bucket}/{key_prefix}'
# S3にアップロード(Notebook名とpythonファイル名は任意)
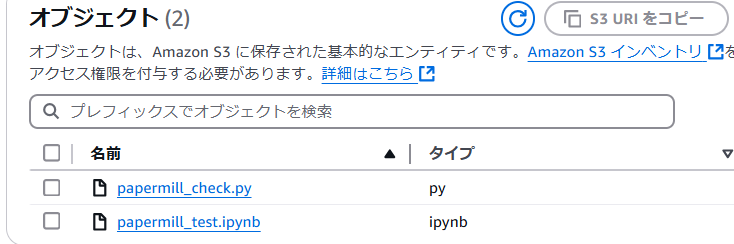
!aws s3 cp papermill_test.ipynb $s3_prefix/input/
!aws s3 cp papermill_check.py $s3_prefix/input/
すると、対象のS3のパスにファイルがアップロードされていることが確認できます。
作成した上記のNotebookにProcessing処理の実行コードを以下のように記入し、実行を行いましょう。
from sagemaker.processing import Processor, ProcessingOutput, ProcessingInput
from sagemaker import get_execution_role
import sagemaker
# ユーザプロファイルのロールを使用
role = get_execution_role()
# Processing Job定義
processor = Processor(
image_uri=processing_repository_uri,
entrypoint=["python3", "/opt/ml/processing/input/papermill_check.py"],
role=role,
instance_count=1,
instance_type="ml.m5.2xlarge", #指定のインスタンスは任意
)
# Processing Job実行
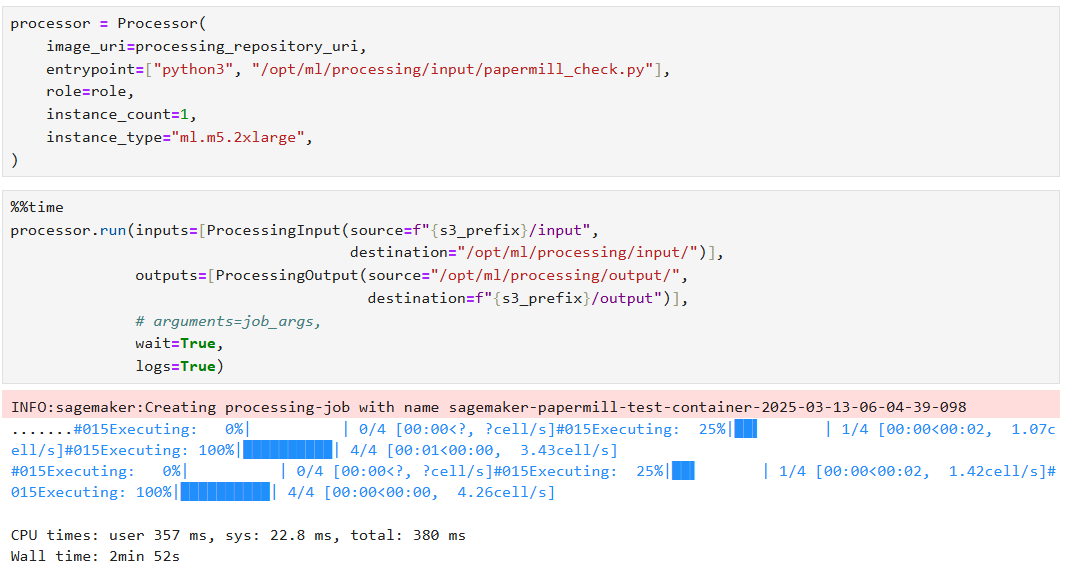
%%time
processor.run(inputs=[ProcessingInput(source=f"{s3_prefix}/input",
destination="/opt/ml/processing/input/")],
outputs=[ProcessingOutput(source="/opt/ml/processing/output/",
destination=f"{s3_prefix}/output")],
# arguments=job_args,
wait=True,
logs=True)
実際に実行した例の一部が以下となります。
④ 実行結果の確認
Notebookファイルの実行が完了した後、実際にProcessing処理が行われているか、確認を行いましょう。
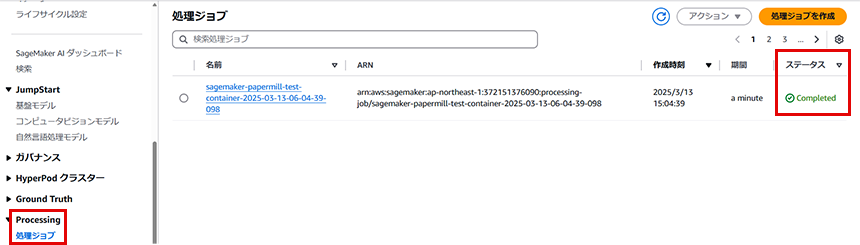
まずは、Processing処理自体の完了ステータスを見ていきます。SageMakerのコンソール画面に移動し、「Processing」が最新の処理ジョブを確認します。すると、ステータスが「Completed」となっていますので、Processing処理の完了が確認できます。
※CloudWatchでもProcessing Jobの実行結果が確認可能です。
次に、実際にファイルが作成できているかを確認します。出力先に指定したS3のパスに移動します。すると、Notebookで定義したパラメータとは異なるファイル名で2つのファイルが作成されていることが見て取れます。これは、Papermillにより②で定義した実行用pythonファイルの通りにパラメータの変換が行われているからです。また、notebookも2つS3に出力され、バッチ実行が行われていることも確認できます。
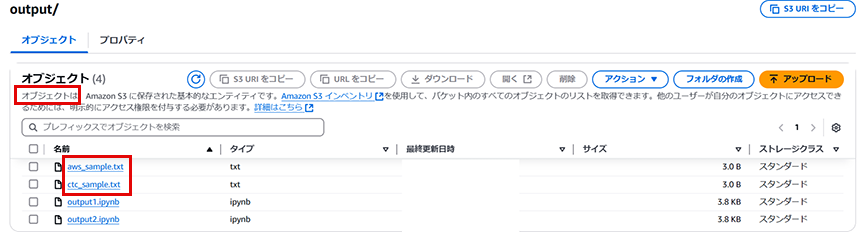
実際にテキストファイルをS3からダウンロードして、中身を見てみましょう。下記の図のように中身も変更されて入力できていることが確認できます。

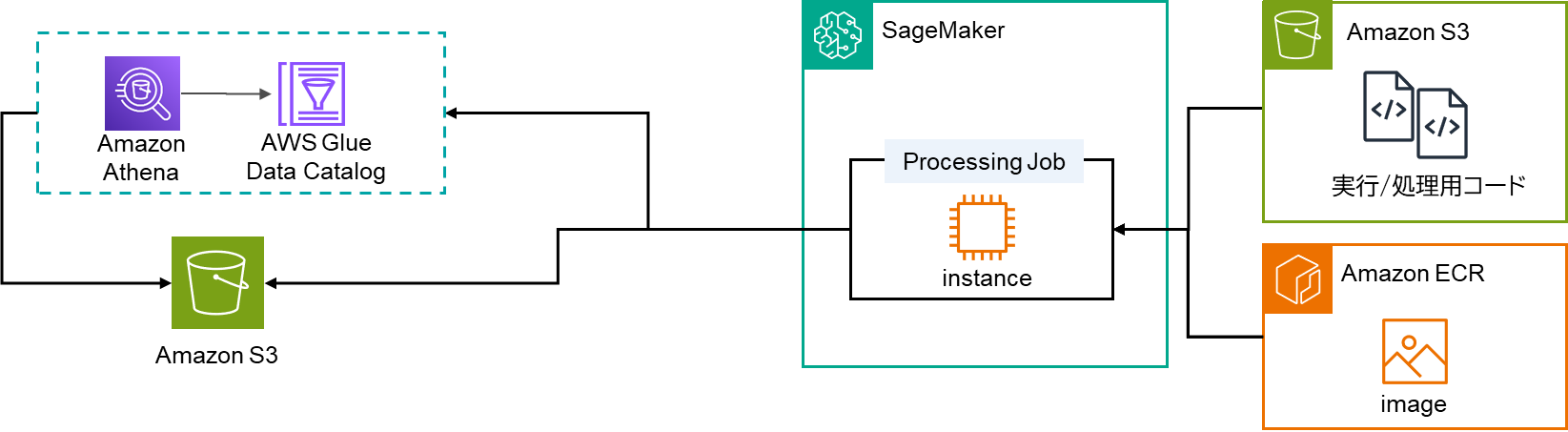
6.Processing Jobの応用例
今回ご紹介したProcessing JobはSageMaker内で実行を行いましたが、EventBridgeやLambdaと組み合わせることで、より効果が大きくなります。実装自体は非常に簡単で、以下のように設定が可能です。
- Lambda関数でProcessing Jobを起動するコードを実装
- EventBridgeでスケジュールルールを作成
- ルールのターゲットとしてLambda関数を設定
2.で示した図にLambdaとEventBridgeを加えたものが下図となります。
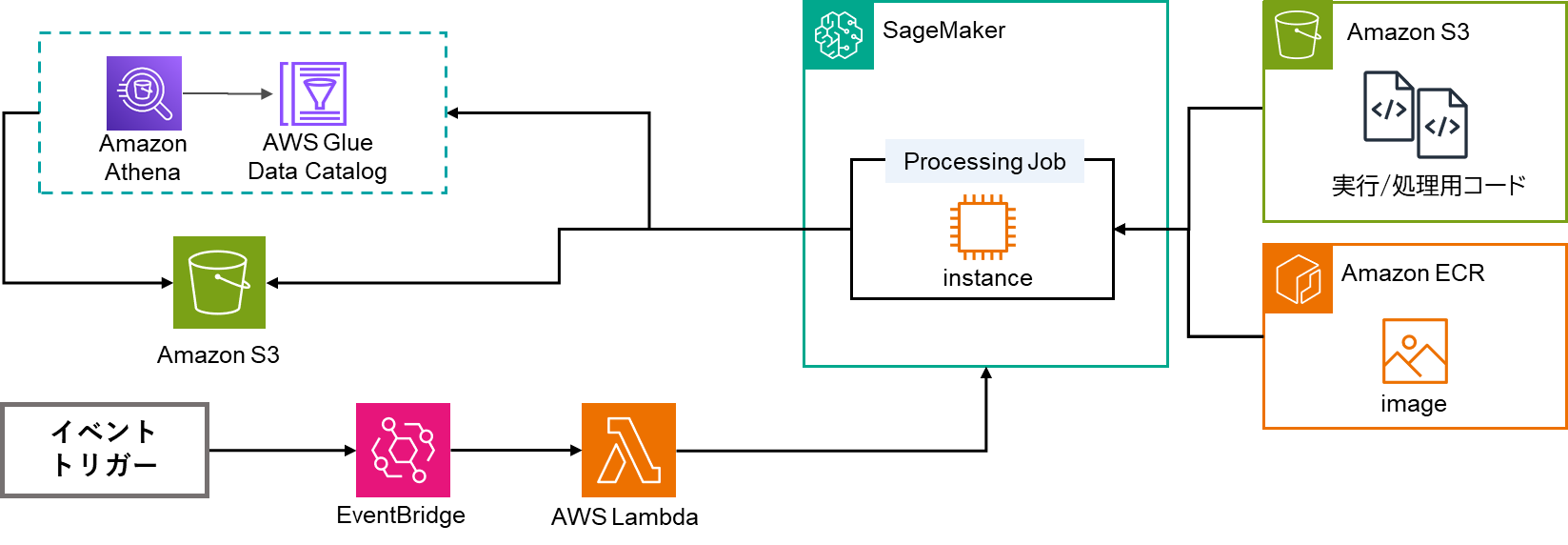
これにより、定期的もしくは各イベントで実行が可能となり、様々な処理に応用ができます。ユースケースの例として
- 定期的なデータ分析レポートの生成
- ETLプロセスの構築
- モデルモニタリングによるパフォーマンス評価
などが可能となり、常時稼働のサービスよりコストも最適化されます。
7.まとめ
いかがでしたでしょうか。今回、Papermill環境を作成し、その環境内でProcessing Jobによりファイル処理を行いました。Processing Jobのご紹介ということで、コンテナ内で行った処理自体は簡単なファイル処理でしたが、より複雑な処理や各AWSサービスを組み合わせることで業務効率化やコスト最適化が可能です。また、今回はProcessing Jobのみのご紹介でしたが、SageMakerではモデルの学習に用いられるTraining Jobなどもございます。もしご興味ございましたら、他のジョブ機能も試してみてください。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。

