Amazon AthenaでApache Icebergを使用してみた(その1)
投稿日: 2024/02/08
はじめに
こんにちは、稲守です。
データレイクのテーブルフォーマットとしてApache Icebergが取り上げられることが多くなってきました。AWSでもIcebergをサポートしているサービスとして、Amazon Athena、Amazon EMR、AWS Glueなどがあります。また、Amazon Redshiftでも読み取り専用アクセスですがプレビュー機能(2024年2月現在)として使用できるようになっています。
本稿ではApache Icebergについての説明し、次回のエントリでAthenaでの使用感について紹介します。
テーブルフォーマットとは、データベースやデータウェアハウスなどのデータ管理システムで、データをテーブルとして格納するための構造や形式を指します。テーブルフォーマットはデータの配置、格納方法、メタデータの管理方法などを定義します。
一般的には、以下のような要素で構成されています。
- 列(カラム)の定義
- データ格納方法
- データの圧縮・エンコーディング
- パーティショニング
Apache Icebergとは
Apache Icebergは2017年にNetflix社で開発が始まり、2018年11月にオープンソース化されてApache Software Foundationのプロジェクトになりました。IcebergプロジェクトのWebサイト(https://iceberg.apache.org/)から特徴を見てみます。
- ● Expressive SQL(表現力のある SQL)
- ● Full Schema Evolution(スキーマ進化)
- ● Hidden Partitioning(隠しパーティション)
- ● Time Travel and Rollback(タイムトラベルとロールバック)
- ● Data Compaction(データ圧縮)
ただIcebergはあくまでテーブルフォーマットのため、これらの機能がどこまで実装されているかは、エンジン次第となっています。そのため、Amazon Athenaで対応している機能、Amazon EMRで対応している機能、そのほかApache Spark、Trinoなど使用するエンジンのドキュメントを確認しつつ使用することとなります。
ではあらためて順番に特徴を見てみましょう。
① Expressive SQL(表現力のあるSQL)
従来のデータレイクでは、挿入、削除、更新などが難しく、手動でメタデータを更新する必要がありました。またACIDトランザクションが不足していたり、パーティション管理が複雑になったりという問題点がありました。これが、Icebergでは柔軟なSQLをサポートしており、MERGEやUPDATE、DELETEなどが自由に行えます。
それができるのは、なぜでしょうか。
Icebergのアーキテクチャをみてみます。Apache Icebergは、3 つのカテゴリのメタデータを通じてテーブルを定義しています。
- ① テーブルを定義する「メタデータファイル」
- ② テーブルのスナップショットを定義する「マニフェストリスト」
- ③ 1 つ以上のスナップショットの一部となるデータファイルのグループを定義する「マニフェストファイル」
クエリの最適化と Iceberg のすべての機能は、これら 3 つのメタデータ層のデータによって実現されています。
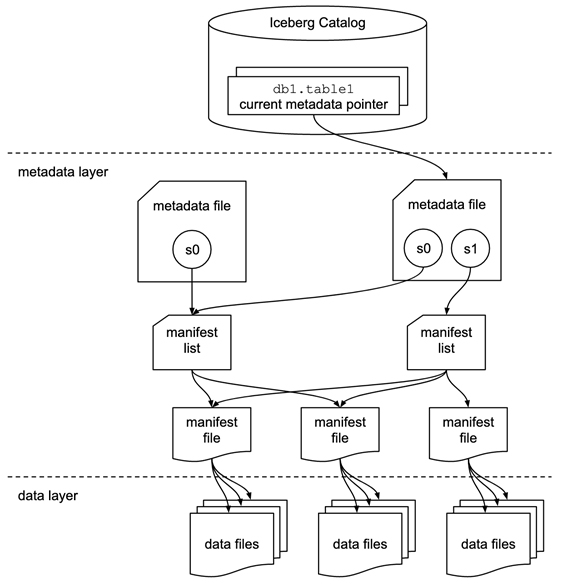
https://iceberg.apache.org/spec/#overview
メタデータツリーを通して、Icebergはスナップショットの分離とACIDサポートを提供しています。クエリが実行されると、Iceberg は基本的に最新のスナップショットを使用します。任意のテーブルへの書き込みは新しいスナップショットを作成しますが、これは並行クエリには影響しません。同時書き込みは楽観的並行処理(新しいスナップショットを最初に書き込んだ者が書き込みを行い、他の書き込みは再試行される)によって処理されます。
Apache Icebergでは、典型的な作成、挿入、結合の他に、行レベルの更新と削除も可能です。これらのトランザクションはすべてSQLコマンドで可能です。
② Full Schema Evolution(スキーマ進化)
テーブルのスキーマの進化をサポートしています。カラムを追加したり、削除したり、列名を変更したり、型を拡張したり、列の順序を変更したりすることができます。Icebergではスキーマの更新はメタデータの変更のため、データファイルを書き換える必要はありません。
③ Hidden Partitioning(隠しパーティション)
Hidden Partitioningとは、パーティションのために、特別にカラムを用意する必要がないということです。例えばevent_time(時間単位)のようなタイムスタンプ値がもともと存在していても、日付のパーティションにしたい場合は、event_date(日付単位)のようなカラムを作成してパーティションキーとする必要があったりします。この場合、正しくユーザが値を生成しないと誤ったパーティションに入ってしまいます。Icebergでは、日別のパーティションを作成したい場合は、partition by (date(event_time))とすれば、タイムスタンプのカラムをもとにしていても、日付によってパーティションが生成されます。
使用できるパーティション変換関数は次のようなものです。(Athenaの例)
| 機能 | 説明 | サポートされている型 |
|---|---|---|
| year(ts) | 年によるパーティション | date, timestamp |
| month(ts) | 月によるパーティション | date, timestamp |
| day(ts) | 日によるパーティション | date, timestamp |
| hour(ts) | 時間によるパーティション | Timestamp |
| bucket(N, col) | ハッシュ値 mod N のバケットによるパーティション | int, long, decimal, date, timestamp, string, binary |
| truncate(L, col) | L に切り捨てられた値によるパーティション | int, long, decimal, string |
また、パーティション分割も、既存のテーブルで更新することができます。パーティションを変更しても以前の設定で書き込まれた古いデータは変更されません。新しいデータは新しい設定のパーティションで書き込まれます。そしてパーティションバージョンのメタデータは個別に保持されます。
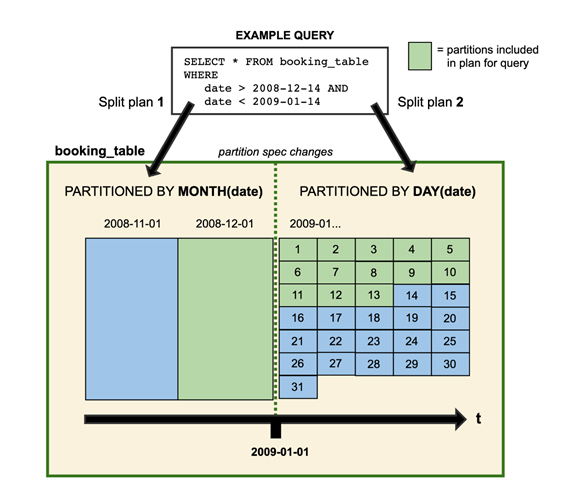
https://iceberg.apache.org/docs/latest/evolution/#partition-evolution
上記の例では2008年のデータは月ごとに分割されていて、2009年以降は日別にパーティション化されています。このように両方のパーティションレイアウトを同じテーブル内に共存できます。そして、Icebergでは高速化する為に特定のパーティションレイアウトに対するクエリを作成する必要はありません。Hidden Partitioningによって、クエリを実行すると、一致するデータを含まないファイルは自動的にスキャンの対象外になります。
④ Time Travel and Rollback(タイムトラベルとロールバック)
Icebergではデータのバージョニングをサポートしていて、タイムトラベル機能を使うことができます。そのため、ある時点の操作が誤っていたなどの問題がわかった場合はその時点までデータを戻すことが可能です。またデータサイエンスの利用シーンでも、ある断面の学習を再現する為に、データを戻したいケースがありますね。その場合にも有用な機能です。
SELECT * FROM iceberg_table FOR TIMESTAMP AS OF TIMESTAMP ’2024-02-01 12:00 Asia/Tokyo’
とすれば、2024年2月1日12時のスナップショットを確認できます。
⑤ Data Compaction(データ圧縮)
Iceberg テーブルにデータが蓄積するにつれて、ファイルを開くために必要な処理時間が長くなるため、クエリの効率が徐々に低下します。テーブルに delete files が含まれている場合は、追加の計算コストが発生します。Iceberg では、delete files には行レベルの削除が格納され、エンジンは削除した行をクエリ結果に適用する必要があります。
Iceberg テーブルでのクエリのパフォーマンスを最適化するために、圧縮によって、表の内容を変更することなく、テーブルの構造レイアウトを最適化することができます。
また、スナップショットの有効期限切れや、孤立ファイルの削除などをすることもできます。これによって、メタデータのサイズを小さくし、保持期間よりも古いファイルが削除されます。
これらのデータ圧縮について、手動で実行するだけでなく、メンテナンス処理が自動化する仕組みが用意されているエンジンもあります。Athenaでは手動で実行するコマンドも用意されていますが、AWS Glueデータカタログでは2023年11月に自動圧縮する機能が有効化されました。
次回について
今回は、オープンなテーブルフォーマットであるApache Icebergの概要について紹介しました。概念ばかりでピンと来なかったかもしれません。次回はAmazon Athena上でIcebergテーブルを操作して、どんな操作感なのか試して見ましょう。それではまた。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。
クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理
