[ANT335] How Disney used AWS Glue as a data integration and ETL framework(分析)
投稿日: 2022/12/09

ディズニーがAWS Glueをデータ統合サービスとして選択した理由と、AWS Glueで既存のHadoop、Sparkに代わって使用した方法のケース紹介セッションに参加しました。

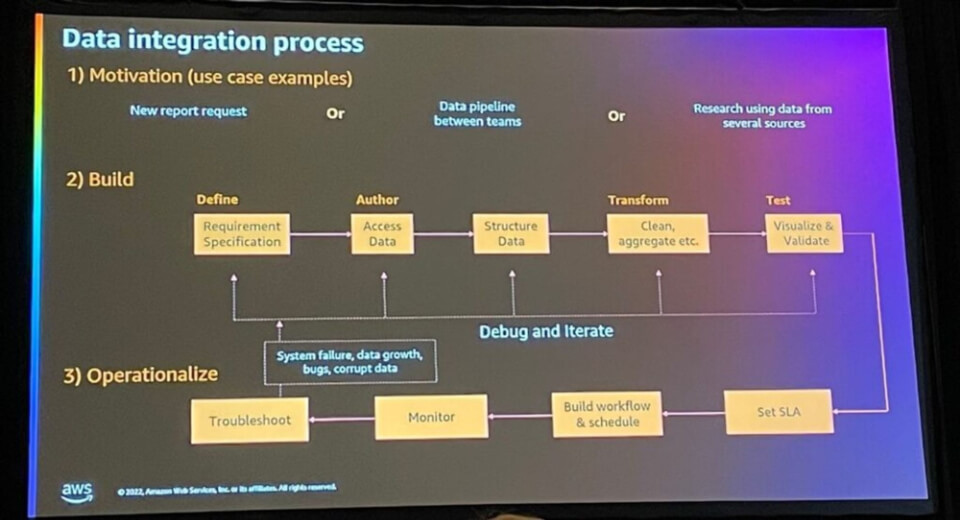
データ統合プロセスは、次のように3つの段階に分けられます。
- 1. Motivation(動機):新しいレポート要求/チーム間のデータパイプラインなどのデータ統合が必要な要件
- 2. Build(構築):要件を細分化して定義し、データにアクセスして構造をつかんで、洗練し、集計し、視覚化し検証するプロセスを通じてデータ統合を構築する
- 3. Operationalize(オペレーティング):SLAを設定し、ワークフローとスケジュールをかけて動作することを監視し、問題が発生した場合は再構築プロセスを経て反映

ただし、データ統合の過程で以下の問題が発生します。
- 指数関数的なデータ成長に比べて料金とデータ容量による制限
- 新しいデータソースが作成されたときに反映するのに時間がかかる
- 増加する多様性のため、変換に以前よりも多くの力を使用する必要があります
- 多くのアプリケーションで分析するため、セキュリティと信頼の維持が困難
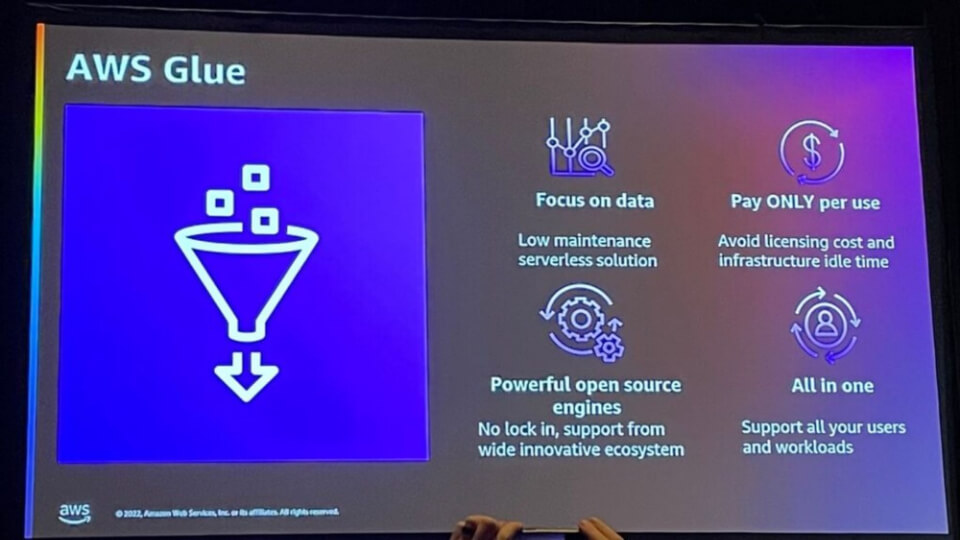
AWS Glue は、このようなデータの問題を解決するデータ統合のためのサービスです。
- サーバーレスソリューションでメンテナンスを必要とせずにデータに集中可能
- ライセンス料とインフラストラクチャ費用なしで使用料のみを支払う
- 大規模で革新的なエコシステムからサポート可能なオープンソースエンジンを使用
- すべてのユーザーとタスクをサポート
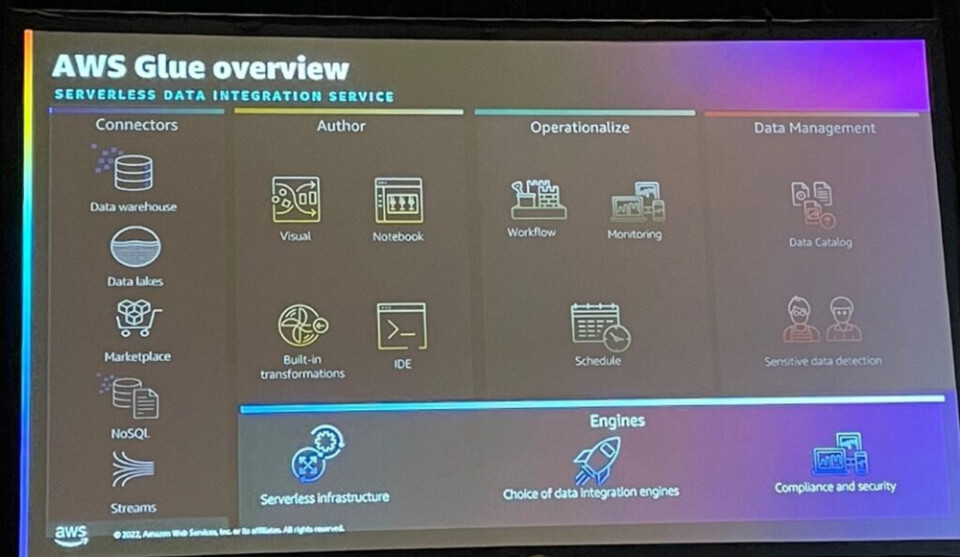
サーバーレスデータ統合サービスであるAWS Glueが提供する機能は、上記のように整理できます。
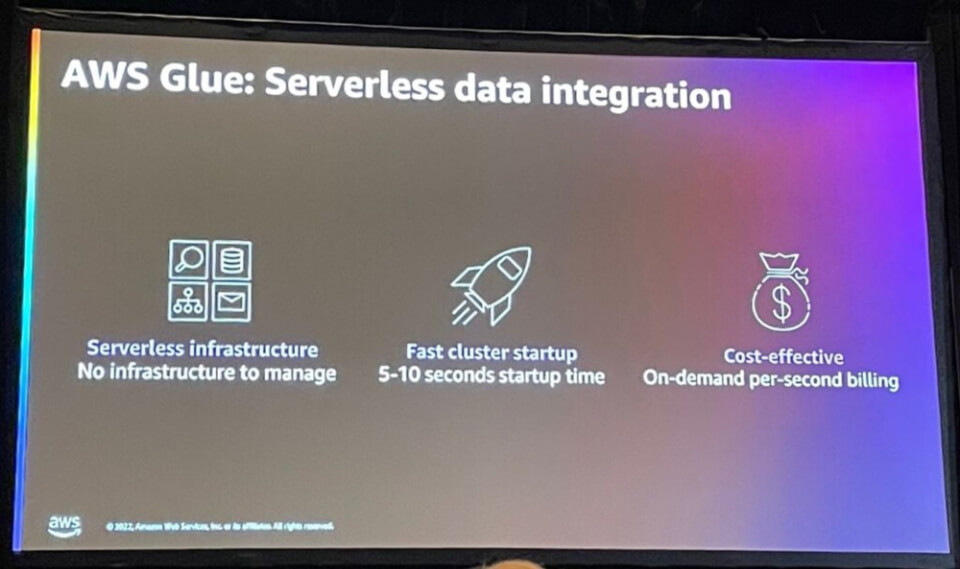
AWS Glueはサーバーレスでインフラストラクチャ管理を必要とせず、迅速にクラスターを起動でき、オンデマンドで料金が発生し、費用対効果の高い利点があります。

AWS Glue は Spark、Python Shell などさまざまなタスクを使用することができ、「Ray」という新規サービスもすぐにリリースされる予定だそうです。
Connectors
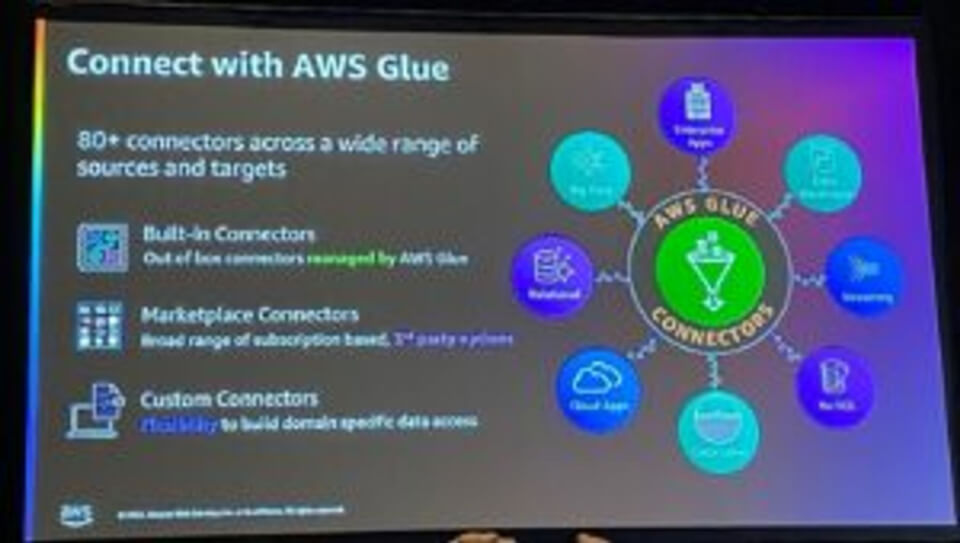
AWS Glueを使用すると、80以上のデータソースと接続でき、3つの異なる種類のコネクタを提供できます。
- Built-in コネクタ: AWS Glue が運用、提供するコネクタ
- Marketplace コネクタ: 3rd party データソースコネクタ
- カスタムコネクタ:ドメイン固有のデータ接続可能
Author
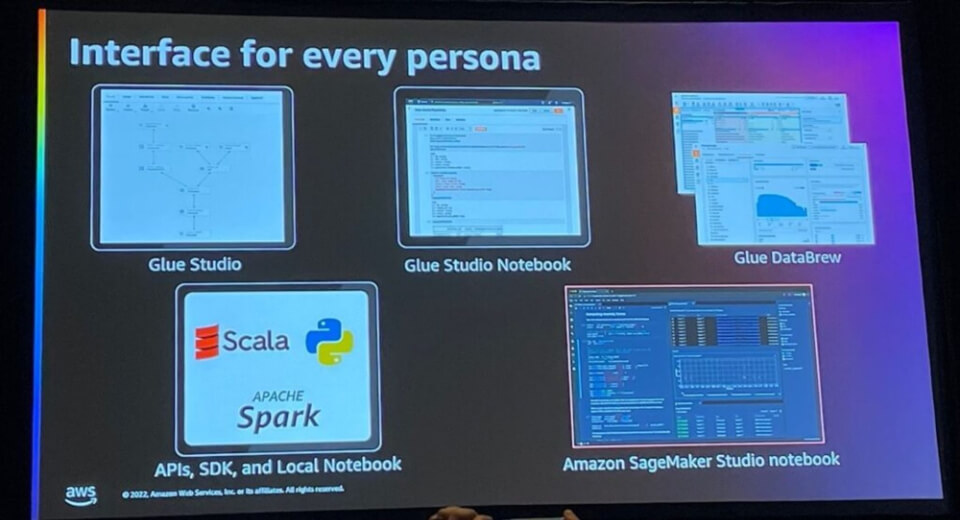
AWS Glueは、Glue Studio、Glue Studio Notebook、Glue DataBrew、APIS/SDK/Local Notebook、Sagemaker Studio notebookなど、さまざまな特性に合わせて必要なインターフェイスを提供します。
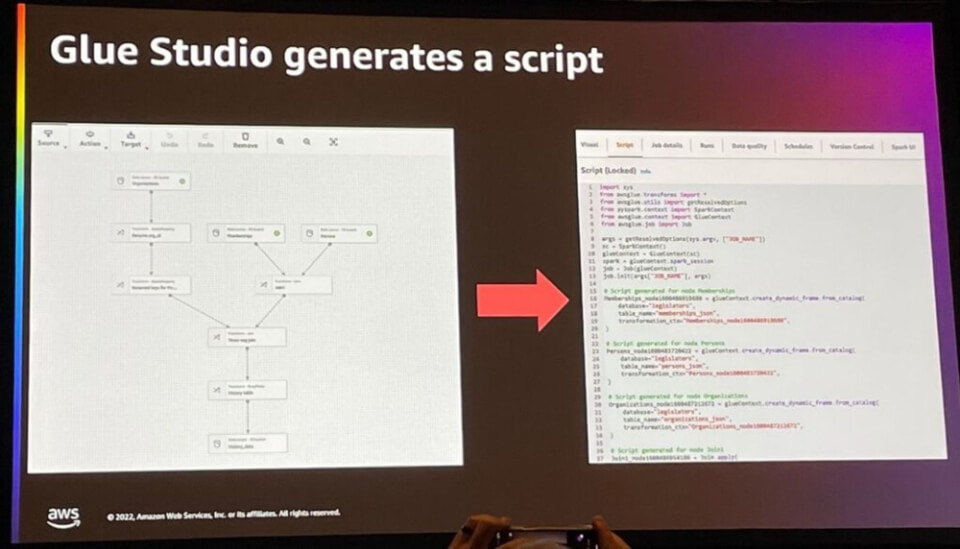
そのうち代表的なインターフェースにはGlue studioがあり、ユーザーが望むソースデータ、変換(機能)、ターゲットソースをUI上に設定すると自動的にスクリプトを生成します。
Operationalize
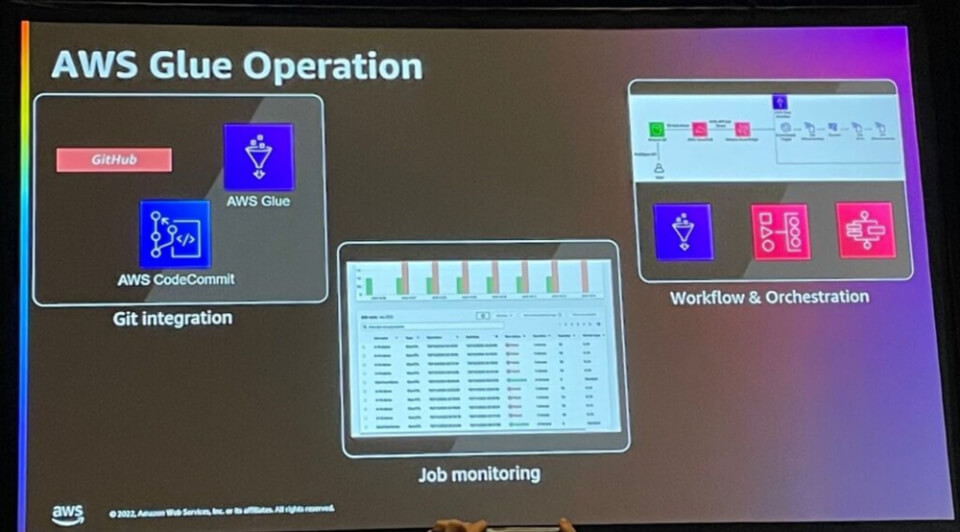
AWS Glueの運用には3つの機能があります。
- Git Intgegration:バージョン管理のためにAWS Glue、AWS CodeCommit、GitHubの接続が可能
- Job monitoring: AWS Glue が提供する UI を介してジョブモニタリングが可能
- Workflow & Orchestration:ワークフローとオーケストレーションを作成して自動化可能
データ管理

AWS Glueで利用可能なData Catalogを活用して、データレイクのメタデータを保存および管理できます。
Data Catalogでメタデータを保存および管理するには、次の利点があります。
- 高い安定性と可用性
- サーバーレスで費用対効果の高い
- メタデータにさまざまな方法でアクセス可能
- スキーマのレジストリとして利用可能

また、AWS Glue で機密情報の検出と処理が可能で、データを簡単に管理できます。
AWS Glue Use cases

ユーザーは以下の要件のためにAWS Glueを使用しています。
- 伝統的なETLによるMigration
- データレイク統合
- セルフサービスデータ統合
- Data WarehouseからETL/ELT
- サーバーレスでApache Sparkを使用する
- MLのためのData Prepration
How Disney Chose AWS Glue – ケース

コロナによる社会的距離を置くため、ディズニーパークでゲスト数を制御しなければならず、遊園地の使いやすさを最適化するために現在および将来の予約についての洞察を引き出す必要があります。
AWS Glue 以前は、Amazone EC2 にインストールされた Hadoop クラスターを使用し、上記のサービスを使用していました。

Hadoopを使用すると、クラスターのセキュリティ、容量、スケーリング困難などの問題が発生していました。

Hadoopに代わるサービスとしてAWS Glueを選択した理由は、Glueはサーバーレスで、市場に適応し、Sparkベースであり、費用対効果が高いためです。

AWS Glueへの移行では、ディズニーの動機と目標は次のとおりです。
- さまざまな段階の規制とデータを扱う標準化された方法が必要
- シンプルな使いやすさ
- データエンジニアが構造を詳しく理解することなく対処できるエンドツーエンドツールの提供
- PythonやSpark経験のないSQL開発者などのユーザーを検討する

内部Glue Internal Glue frameworkは以下のように構成されているそうです。
- Internal Glue framework: 新しい spark コードを書く必要がないように、AWS Glue job を実行してトラッキングする YAML ファイルを使用する 1 つの pyspark で書かれている
- Job runner: AWS Glue Job の開始点で、Spark session の準備とタスクの実行
- Job Tracker:正常に処理されたファイルのトラックを保存する
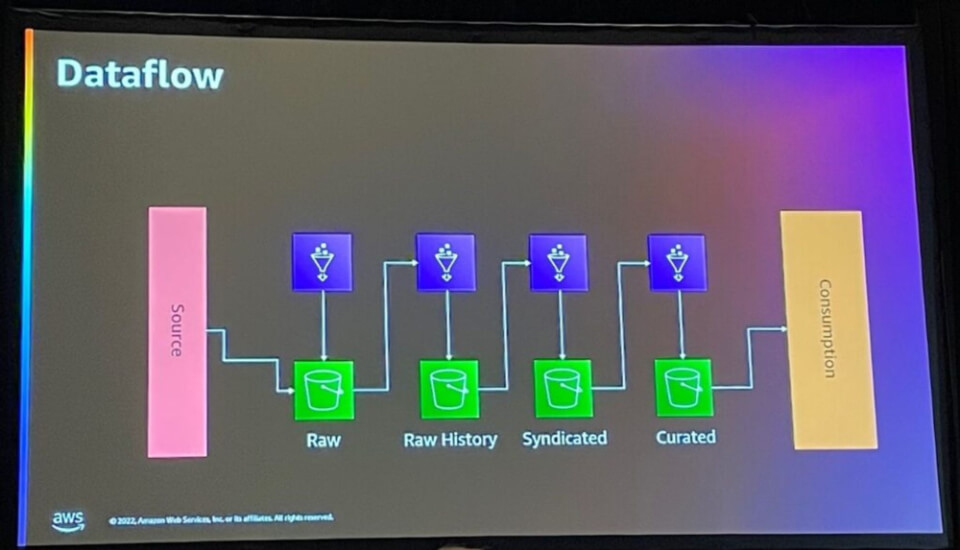
Dataflowは上記のように構成されており、ソースデータからRawデータ、Raw Historyデータ、Syndicatedデータを経て最終的にCuratedデータを生成し、データ消費者が使用できるようにしました。
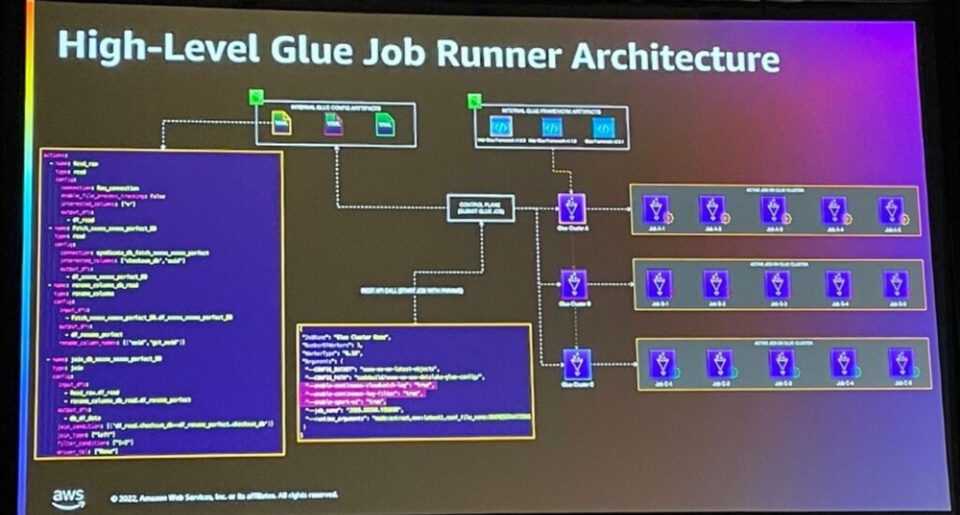
High Level Glue Job Runnerのアーキテクチャは上記のとおりです。
control planeにジョブを実行させ、trackingするyamlなどのconfigファイルが保存されており、control planeを通じてJob Runnerジョブを実行させると、各ジョブランナーは子ジョブを実行します。
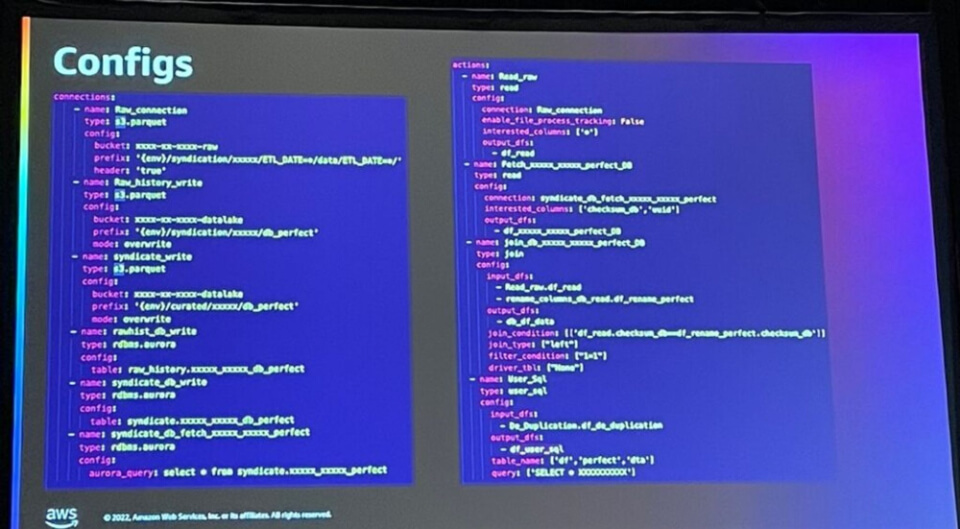
Config ファイルの参照画像です。
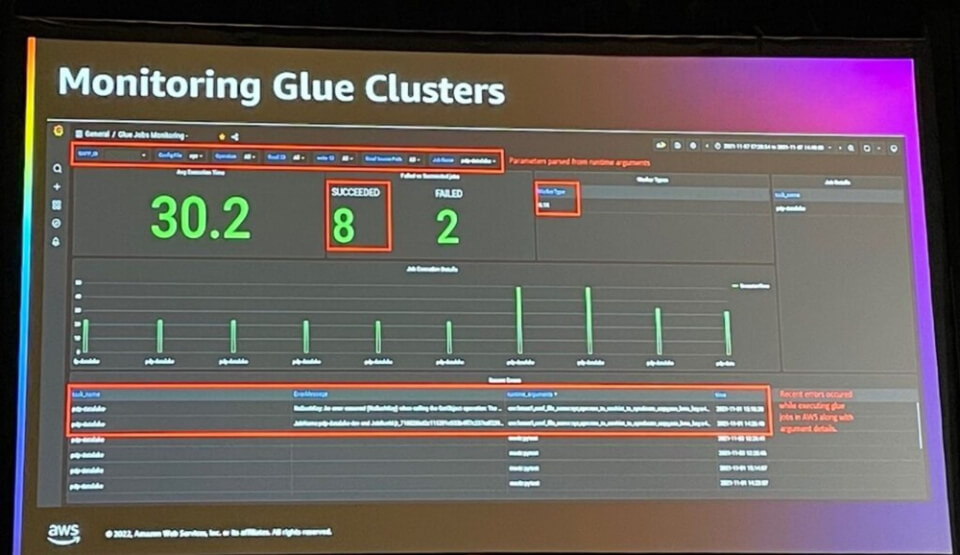
また、Glue Clusterの作業状況を簡単に監視できます。
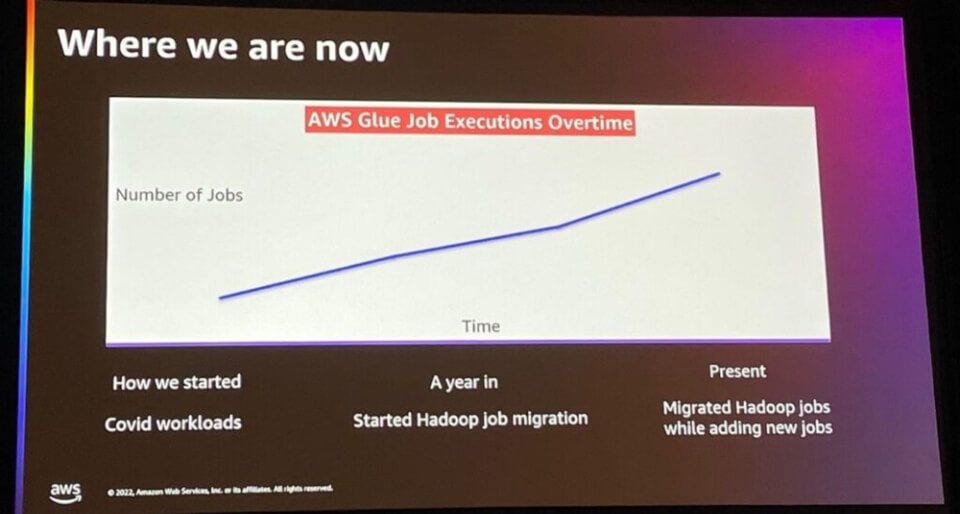
現在、ディズニーのAWS Glue Job Excutionの状況は次のとおりです。
- コロナ関連のワークロードでAWS Glue Jobの使用を開始
- 約1年後、Hadoop to Glue migration作業を開始
- 現在、Hadoop jobをGlueに移行し続け、同時にGlueに新しいジョブを作成し続ける

結論として、AWS Glue は我々のワークロードの規模拡大に貢献しました。AWS Glueを使用することで、エンジニアがHadoop clusterを維持することに気を使うのではなく新しいデータ操作に集中できるようになり、AWS Glueを使用して分析コンピュート環境を進化させることができました。
数ヶ月後にはディズニーランドパリにも適用を開始する予定だそうです。
実際、データ統合/変換などの作業が必要なほとんどのプロジェクトでは、AWS Glueを多く活用していますが、Glueのメリットを一度にまとめることができたセッションでした。
Glueのconnector、interface、monitoringなどの作業やワークフローに関連する機能に加えて、さまざまな機能を提供していることがわかりました。
Glueをよりよく活用できるようで、ディズニーランドで使用しているGlue Frameworkの方式は、典型的なGlueの使用方法とは異なりますが、うまく活用すれば効率的だと思うので、機会になったらフレームワークを参考にして実際に適用してみたいと思いました。
