[COM306-OF]_Bringing software engineering rigor to data(Data Lakes)
投稿日: 2022/12/09
Software Enigineeringの観点から見た、効率的なData Platformの構築と活用方法について紹介するセッションに参加しました。


効率的なデータプラットフォームの構築と活用方法については、以下のAgendaに進みます。
- 高速データ移動
- データのDORA metrics
- 成功のための戦略
- 成功したデータエンジニアリングのための推奨事項

DORAメトリクスとは、ソフトウェア開発チームのパフォーマンスを測定するために定義された4つの重要なmetricsで、DevOps Research and Assessmentの6年間のリサーチとして定義されています。このようなDORAメトリクスをData Engineeringに適用して、効率的なData Platformをどのように測定できるかについて説明します。

DORAメトリクスには、以下の4つのメトリックがあります。
- 1. Deployment frequency: 組織がどのくらいの頻度で正常にデプロイするか
- 2. Lead time for changes : 変化が production まで反映されるのにかかる時間
- 3. Change failure rate : デプロイしたときに失敗する割合
- 4. Time to restore service : production に障害が発生したときに必要な回復時間
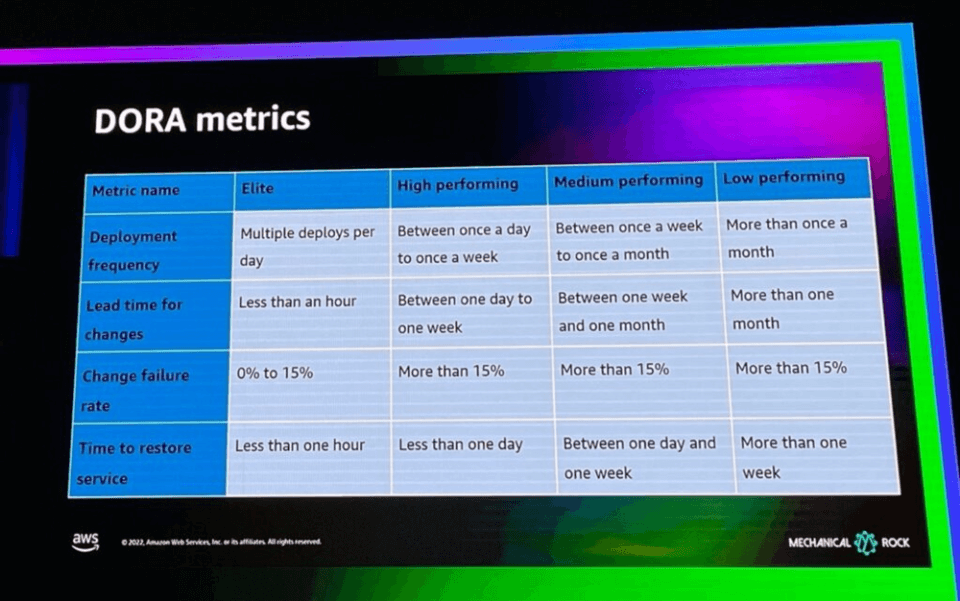
4つのDORAメトリクスを組み合わせて、上記のように組織のパフォーマンスを評価することも可能です。

組織でよく遭遇する最初の困難は、変化が遅いData Platformsです。
ほとんどのAnalytical Data Platfomは上記のような構造を持っています。
すべてのデータが1つのData Platformで処理されているため、データまたはプロセスに問題が発生したり、変更を必要とする場合、データプラットフォームで処理する速度が遅くなるしかありません。

すべてのデータが1つのデータプラットフォームに集まり、変化と活用が遅くなります。
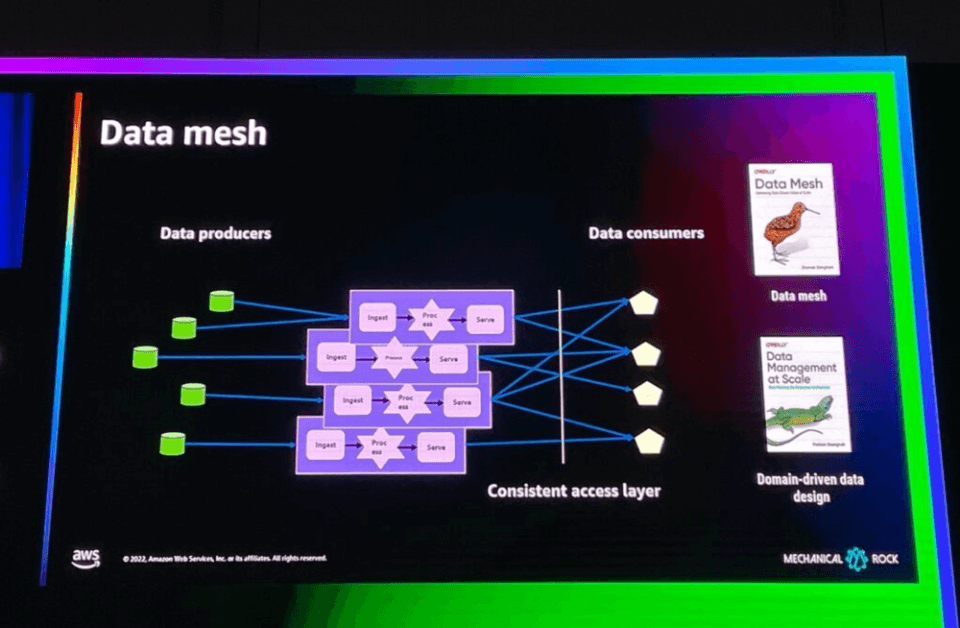
Data Engineering Teamを分散する構造のデータプラットフォーム構築アプローチをData Meshと呼びます。
Data Meshとは、各ドメインごとにデータを収集、処理、供給するプラットフォームを持ち、データ消費者が必要なデータプラットフォームでデータを活用するように構成されたデータプラットフォームです。各ドメイン(データコンストラクタ)ごとに、データエンジニアリングチームが存在するのと同じように見えます。
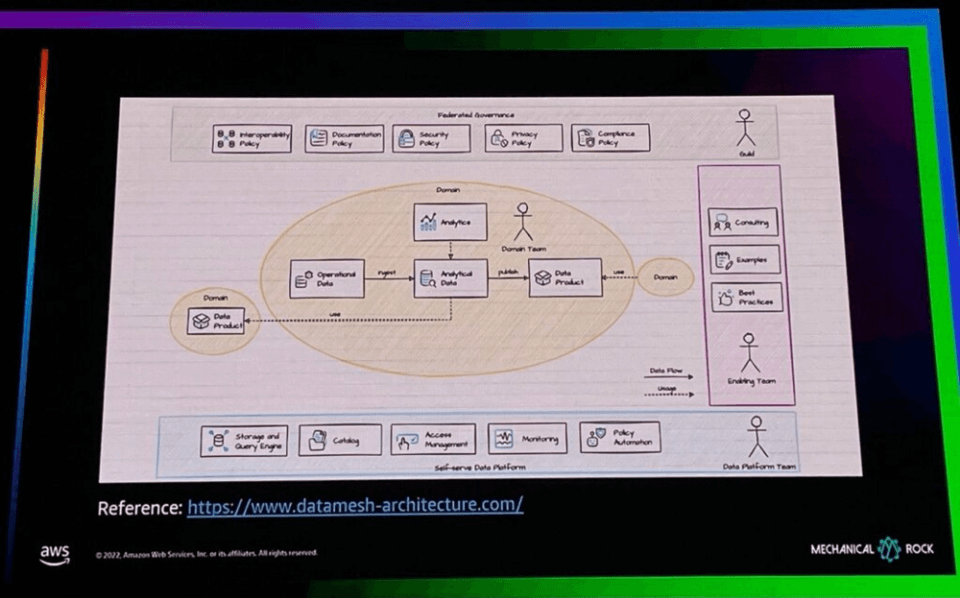
Data Mesh のアーキテクチャは上記と同じです。以下のように追加説明をさせていただきます。
- データプラットフォームチームは、ストレージおよびクエリエンジン、Catalog、Access management、Monitoring、Privact Automationなど、各ドメインチーム(データエンジニア)が自分のデータプラットフォームを構築、活用できるSelf-Serve Data Platformを構築します。
- 各ドメインのチームは、データエンジニアの相談、ガイド、Best Practicesを活用して、プラットフォームチームが構築したSelf-Serve Platformの上に自分のデータを収集、処理、活用するそれぞれのデータプラットフォームを作成します。

このような構造のself-serve platformが成功するためには、Platformの責任とDomainの責任を分離してそれぞれの責任を果たすようにしなければなりません。
Platform Responsibilities
- 1. ドメインチームの仕事をできるようにすること
- 2. Platform セキュリティ
- 3. 集中化されたアプローチ段階
- 4. Platformの一貫性
- 5. Platform品質監視
- 6. テンプレートの作成
Domains Responsibities
- 1. データ収集
- 2. データ変換/処理
- 3. データ供給
- 4. データ観察
- 5. 自動化されたデータテスト
- 6. データマスキング(PII除去など)

2番目の難しさは、ドメインチームに適切な能力がない可能性があることです。すべてのドメインチームが自分のデータを収集/処理/提供する能力を持つのは難しいからです。

このような問題を解決するためには、強力なプラットフォームを構築し、すべてのドメインチームの能力を結合しなければなりません。

3番目の問題は、プラットフォームの適用が遅いことです。

ドメインチームがそれぞれのデータ能力を適用できるように、自動化されたデータプラットフォームを作成する必要があります。

自動化されたプラットフォームには、固有のCI / CD、自動化されたテストパターン、観察能力(モニタリング)が必要です。

4番目の問題は、過度に防御的なデータチームの態度ですが、データチームはセキュリティ問題に敏感であるため、データを共有したくない態度を示し、効率的なデータプラットフォームの構築と活用に困難が生じることが多いです。

この問題を解決するには、セキュリティとデータ発見の能力をプラットフォームに反映する必要があります。

5番目の問題は、データプラットフォームに不必要に複数のパイプラインが集まっていることが多いことです。
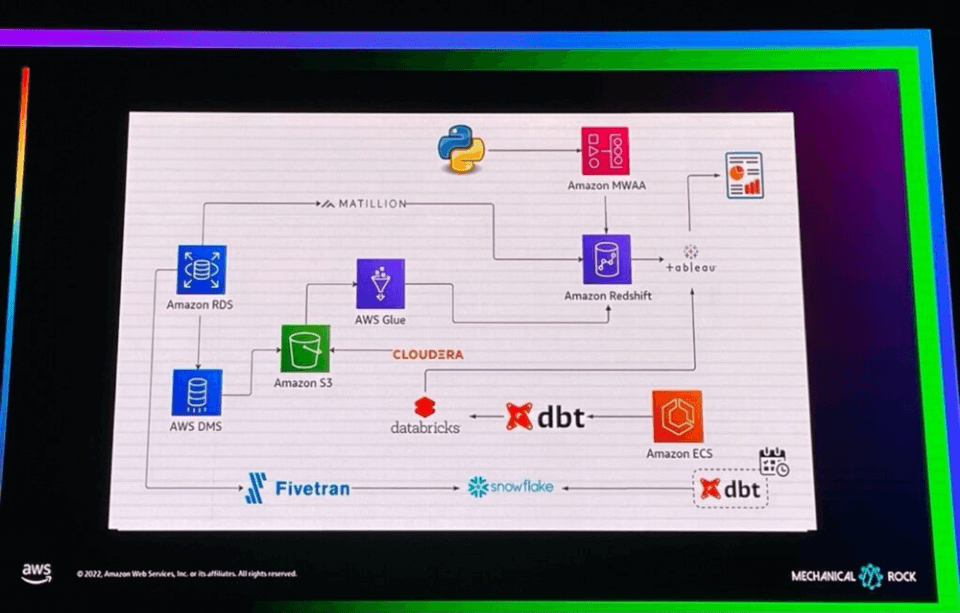
上の写真のように、既存にs3 -> glue -> redshiftデータパイプラインを持っていたデータプラットフォームで、いかなる問題解決や改善のためにdatabricksというサービスを活用するパイプラインを付け加え、またその後にsnowflakeとfivetranを活用するパイプ行を付け加えて、最終的に煩雑な複数のパイプラインが集まっている場合がしばしば発生しますが、このような場合、データプラットフォームの効率的な管理と活用が難しくなります。

この問題を解決するためには、一度に正しく構築する必要があります。

その他の成功したデータエンジニアリングには、以下の事項が推奨されます。
- git/version コントロールの使用
- 自動展開設定
- すべてのビジネスロジックの自動テストを追加
- データパイプラインとプラットフォーム管理の分離
- データパイプラインの状態に関するデータ収集
- データエンジニアから管理アクセスを削除する
今回のセッションでは、ソフトウェア開発者出身のデータエンジニアが実際に体験して見た内容に基づいた効率的なデータプラットフォーム構築アプローチについての実用的な話を聞くことができました。Data Meshは実際にはデータ部門で多く議論されているデータプラットフォーム構造であり、関心を持っていましたが、これに対する概念と必要性を学ぶことができるセッションでした。
効率的なデータプラットフォームのために考慮すべき事項を全体的にまとめるセッションなので、今後データエンジニアとして多くの役に立つと感じました。
