[AER205] Choosing the right accelerator for training and inference(AI/ML)
投稿日: 2022/12/09

Amazon EC2 は、機械学習アプリケーションのための最も広範で深いインスタンスポートフォリオを提供します。P4やG5などのGPUベースの高性能インスタンスから最高の価格パフォーマンスを実現するために、AWSシリコンで特別に設計されたTrn1およびInf1インスタンスまで、各機械学習ワークロードに適したインスタンスがあります。このセッションでは、これらのインスタンス、ベンチマーク、および各インスタンスの理想的なユースケースガイドラインについて学びました。

課題は以下の通りです。
- データサイエンティストは、より少ない時間とコストでさまざまなタイプ/サイズのMLモデルを構築/配布する必要があります。
- MLモデルの構築/配布のための最も効率的なコストパフォーマンスを提供する最高のハードウェア設定を選択する必要があります。
- MLモデルを構築/配布するための最高のコストパフォーマンスハードウェアを構成する必要があります。

AI/MLのための最も広範で深いコンピューティングインフラストラクチャは、従来のMLでの学習/推論のためのM、C、Rインスタンスファミリー、ディープラーニング推論のためのInf、Gインスタンスファミリー、およびモデル学習のためのP、Trnインスタンスファミリーがあります。

ML学習にCPUインスタンスを使用する場合は、次のようになります。
- 従来のMLモデルを学習する場合(表形式のデータ)
- 表形式のデータを前処理する場合
- ディープラーニングモデルのプロトタイプ製作
- 少ないデータセットで微調整を行う場合
Gravition3: ML
BERTモデルを使用してSQuAD v1.1クエリ応答を実行するNLPワークロードを例に、パフォーマンス比較を行いました。Gravition3はbfloat16とSIMD帯域幅の2倍近くをサポートし、C7gはC6gよりもほぼ2.5倍高い性能を提供します。
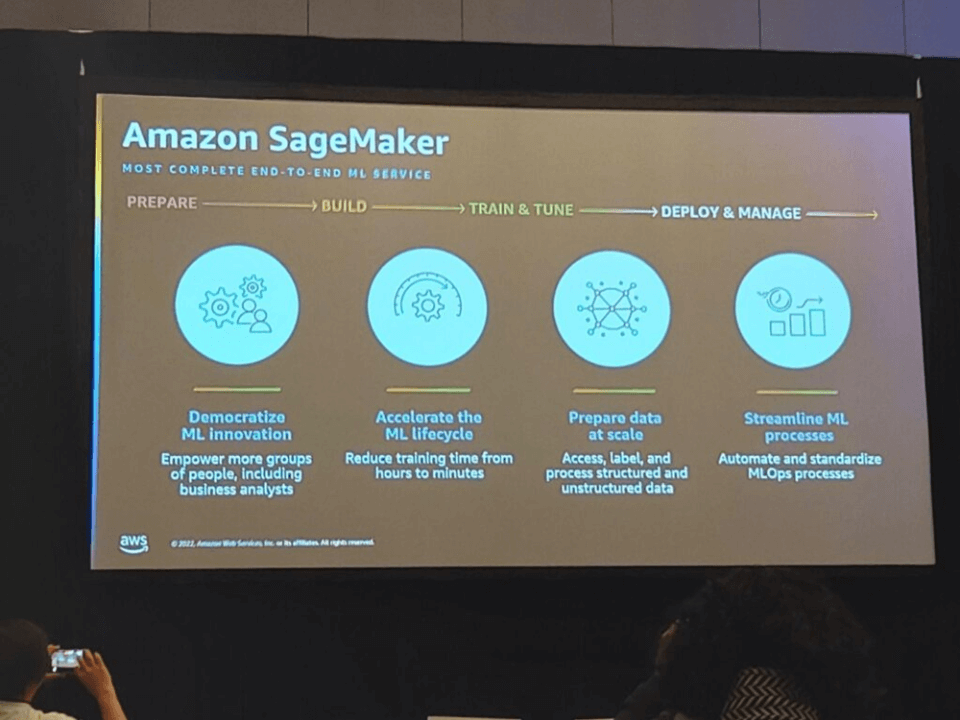
SageMakerでは、次のような利点があります。
- 1)MLの革新を民主化できます。
- ビジネスアナリストを含むより多くの人員グループをサポートします。
-
- 2)MLライフサイクルを加速することができます。
- 学習時間を数時間から数分に短縮できます。
-
- 3)規模に合ったデータを準備することができます。
- 整形データと非定型データにアクセスし、ラベルを付けて処理します。
-
- 4)MLプロセスの簡素化が可能です。
- MLOpsプロセスの自動化と標準化が可能です。

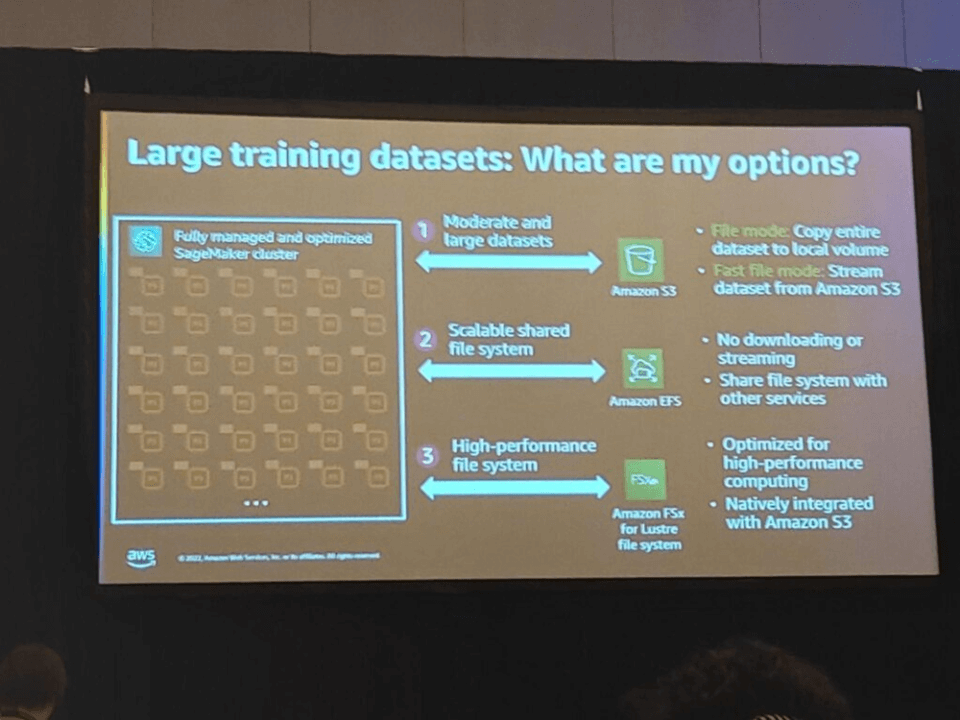
大規模な学習データセットのオプションは次のとおりです。
- 1)中規模および大規模データセットはS3を介して呼び出すことができます。
- ファイルモード:データセット全体をローカルストレージにコピーする
- Fast file mode:S3からデータセットをストリーミングして読み込む
-
- 2)拡張可能な共有ファイルシステム(EFS)を使用できます。
- ダウンロードやストリーミングがない
- 他のサービスとファイルシステムを共有する
-
- 3)高性能ファイルシステム(FSx)
- 最適化された高性能コンピューティング
- S3と基本的に統合されている

最初のカスタマーケースでは、Finch はディープラーニング変換モデルをGPUベースのインスタンスからAWS Incentiaに基づくAmazon EC2 Inf1インスタンスに移行し、Amazon ECSを使用してカスタムコンテナを実行しました。顧客は、GPUの使用に比べてコストを80%以上削減しながら、顧客のスループットと応答時間を維持しました。

2番目のカスタマーケースでは、Amazon RoboticsにおいてAmazon SageMakerを使用してMLモデル開発プロセスを近代化し、推論ワークロードをAWS IncentiaベースのInf1インスタンスに移行しました。お客様は、自己管理ソリューションと比較して推論コストを最大70%削減し、モデルパフォーマンスを40%向上させ、1日に2億を超える推論に拡張できます。

3番目のカスタマーケースであるPaigeは、Amazon Web Servicesに切り替えて、MLワークロードを実行し、増加するデータスペースを管理するハイブリッドアプローチを取りました。分散トレーニングのために、お客様はAmazon EC2 P4dインスタンス、Elastic Fabric Adapter、およびFSx for Lustreを採用しました。PaigeはMLタスクを並行して実行し、内部ワークフロー速度を72%向上させることができ、クラウド内のコンピューティングリソースを拡張してコンピューティングコストを最適化し、チームが革新できるようにしました。
既存のMLプロセスを加速するためにデータの視点やアルゴリズム中心に解決策を考えましたが、実際にはプロジェクトでは分析ロジックを変更できず、入ってくるデータセットも一定の形式である場合があります。
このセッションを聞いた後、このような場合、視野をソフトウェアだけに置かずにハードウェア側に回して速度を上げる方法について学ぶことができ、有益でした。
