[ANT206] “What's new in Amazon OpenSearch Service” (分析)
投稿日: 2022/12/09
Amazon Opensearch Serviceの紹介と機能、およびOpensearchの新機能とロードマップの紹介について聞くために、このセッションに参加しました。

Agendaは次のとおりです。
- Introduction to Amazon Opensearch Service
- Innovations in OpenSearch-search, log, analytics/observability
- What's new in Amazon Opensearch Service-cost optimizations, security, and automation at scale
- Road ahead
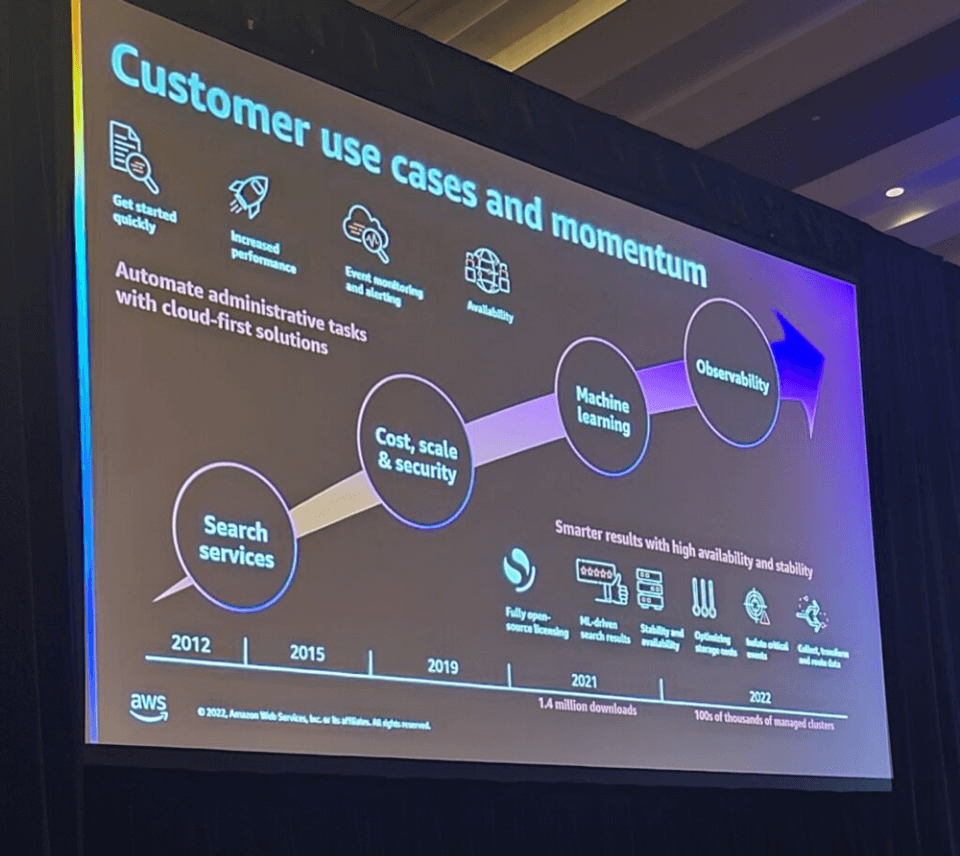
本サービスはウェブ/アプリ検索サービスで始まりましたが、機能がますます追加されて発展してきました。
- コスト最適化、スケーラビリティ、セキュリティ
- Machine Learning
- Observability(可視性)
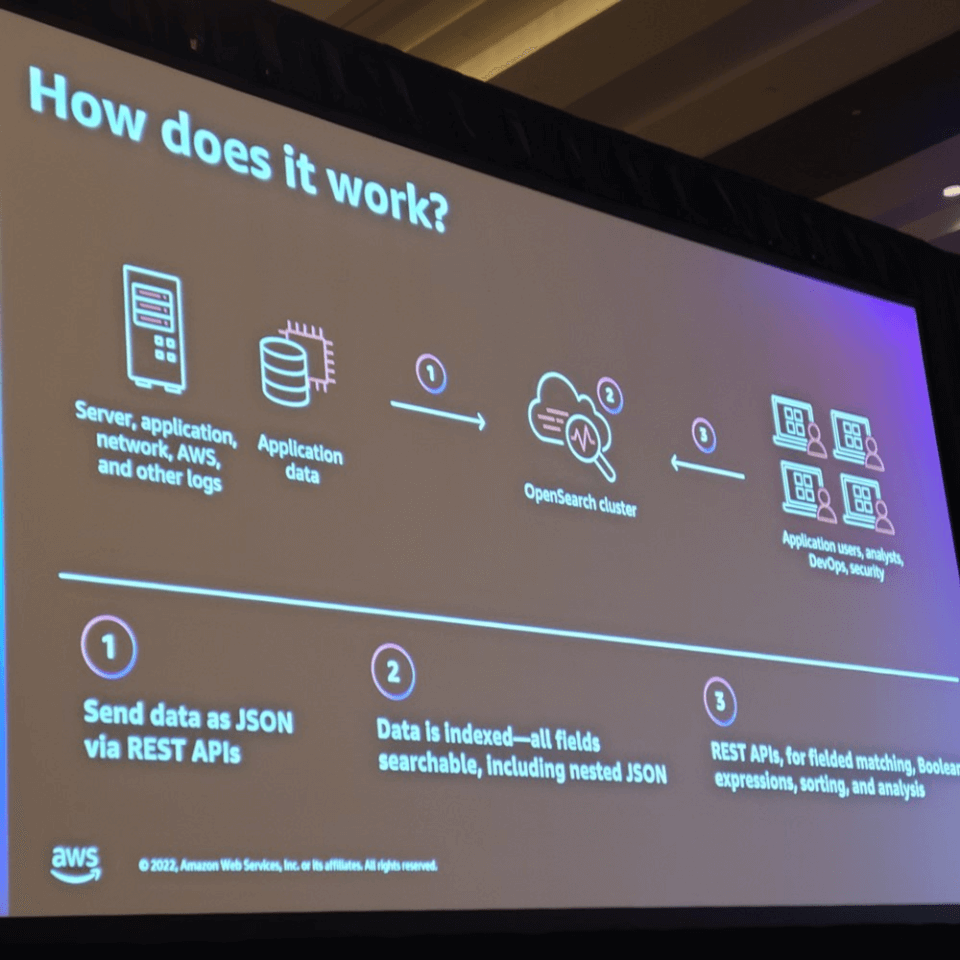
以下のような動作方式をとっています。
- Server、Applicationなどの複数のソースからのデータをOpensearchに保存
- Opensearchで内部的にLuceneがインデックス化
- Opensearchダッシュボードで、データアナリスト、セキュリティ担当者、Devopsエンジニアなどがデータを分析

Opensearchの説明も聞くことができました。
Elasticsearchから派生し、Apache 2.0ライセンスの下で提供される完全なオープンソースとして発売以来、現在までに200万件以上のダウンロード数記録中であり、引き続き成長中だそうです。
重要なデータの収集、セキュリティ、検索、集計、表示、分析により、ウェブサイト/運営データのリアルタイム検索、ストリーミングデータ(ログ)のモニタリング分析を容易にするのに役立ち、さまざまなCSPでサービス提供されています。

Amazon OpenSearch Servicの利点は次のとおりです。
- 1. マネージド - 広く使用されているオープンソースソリューションを使用して運用効率を向上
- 2. セキュリティ - データセンターとネットワークアーキテクチャと組み込み認証によるデータの監査と保護
- 3. コスト削減 - 戦略的な仕事のための時間とコストの最適化
- 4. 可視性 - 機械学習、警告、可視化のためのオープンソースソリューションを使用してシステムの問題を検出、分析、解決
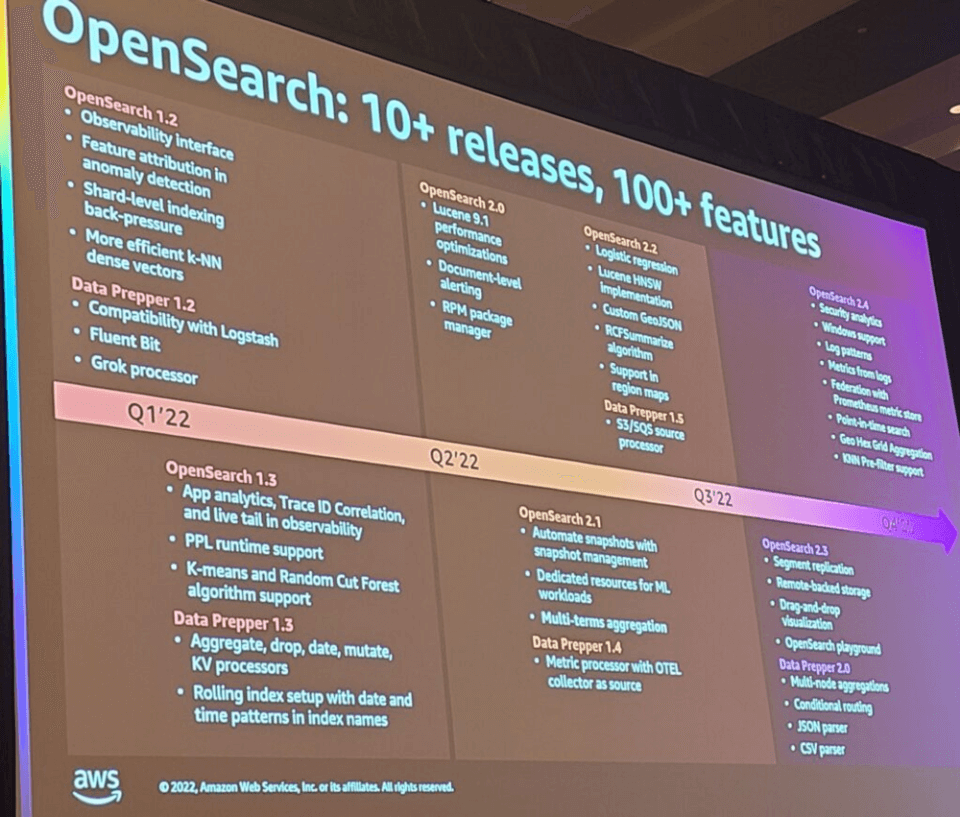
Opensearchは今年だけで10個以上のリリースと100個以上の機能がリリースされ、そのうちの一部が紹介されました。

1. ML innovations for search:検索と分析のために追加された新しいアルゴリズム
- 1)効率的な類似性の検索とクラスタリングのための「FAISS」ライブラリを含む「k-NN」
- 2)Lucene 9.1(Opensearch 2.x)ベースのApproximate k-NNによる類似性の検索
- 高次元ベクトルのインデックススループットを最大30%向上
- 高次元ベクトルで最大 10% 速い最近傍探索

2. Improving search relevance : semantic search (Opensearch 2.4 での実験機能)
- 1)ニューラルネットワークモデルの使用
- ドキュメントセットに基づく言語モデルの微調整
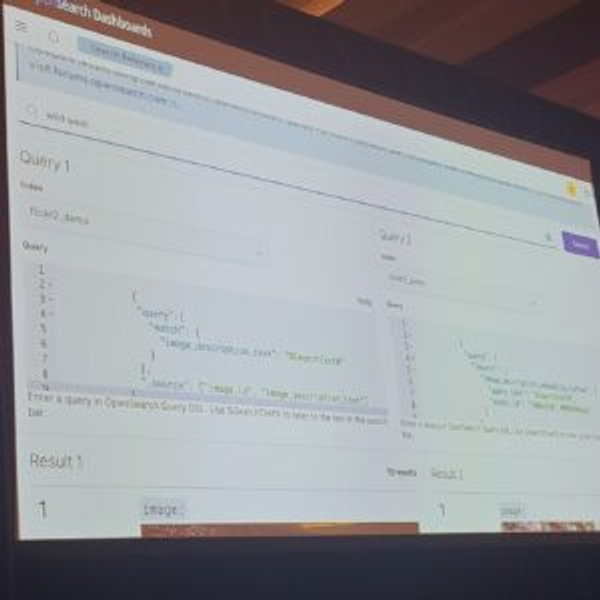
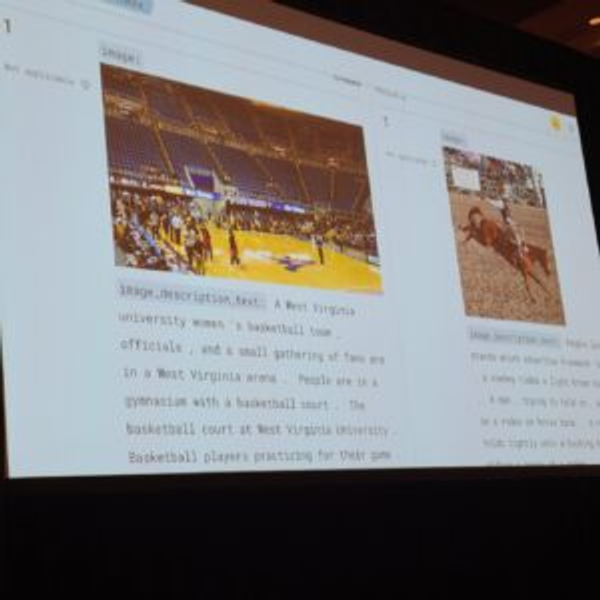
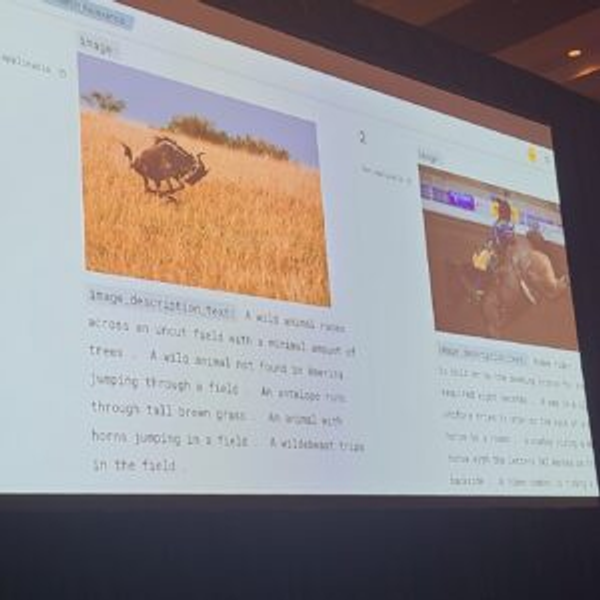
Semantic searchのデモも確認できましたが、Opensearchダッシュボードのsplit viewを通じて行われました。
左が一般的なキーワード検索、右がsemantic searchを使って「wild west」という単語を検索した結果を示しました。
通常の検索とは異なり、セマンティック検索では、検索語に似た画像が表示されました。

Observabilityの導入が必要な背景について聞くことができました。
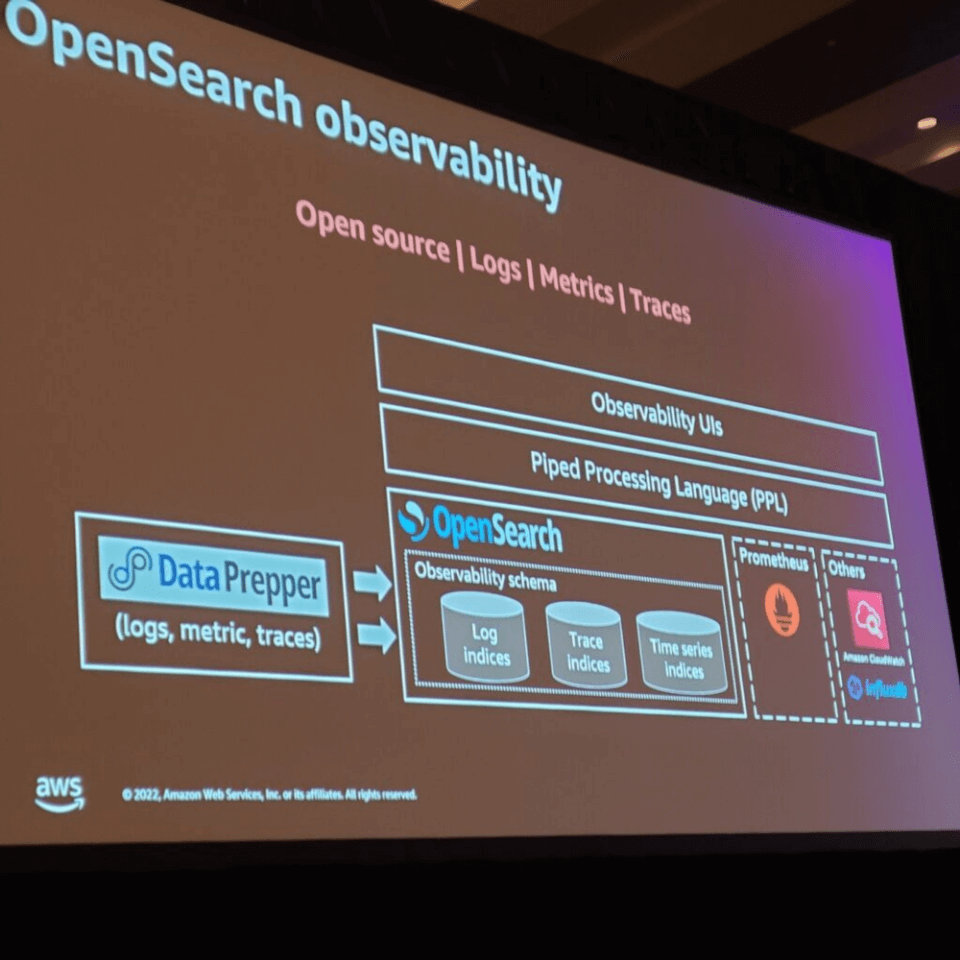
OpenSearchでObservabilityを実現することについては、以下の説明を聞くことができました。
- Data Prepperを使用してlogs、metrics、tracesデータを収集する
- OpenSearchにObservability用のlog、trace、time series indexデータを保存
- Prometheus、Amazon CloudWatch、およびinfluxDBとの連携

それでは、なぜデータパイプラインを使用するのですか?以下のような利点があるそうです。
- 1)コストの観点 – データ冗長性の除去、フィルタリング、サンプリング、ルーティングなどによるコスト削減
- 2)データ品質 – データ標準化、スキーマ適用など
- 3)プライバシー – 機密データの修正と難読化
- 4)ストリーミング分析 – 品質強化と推論プロセス
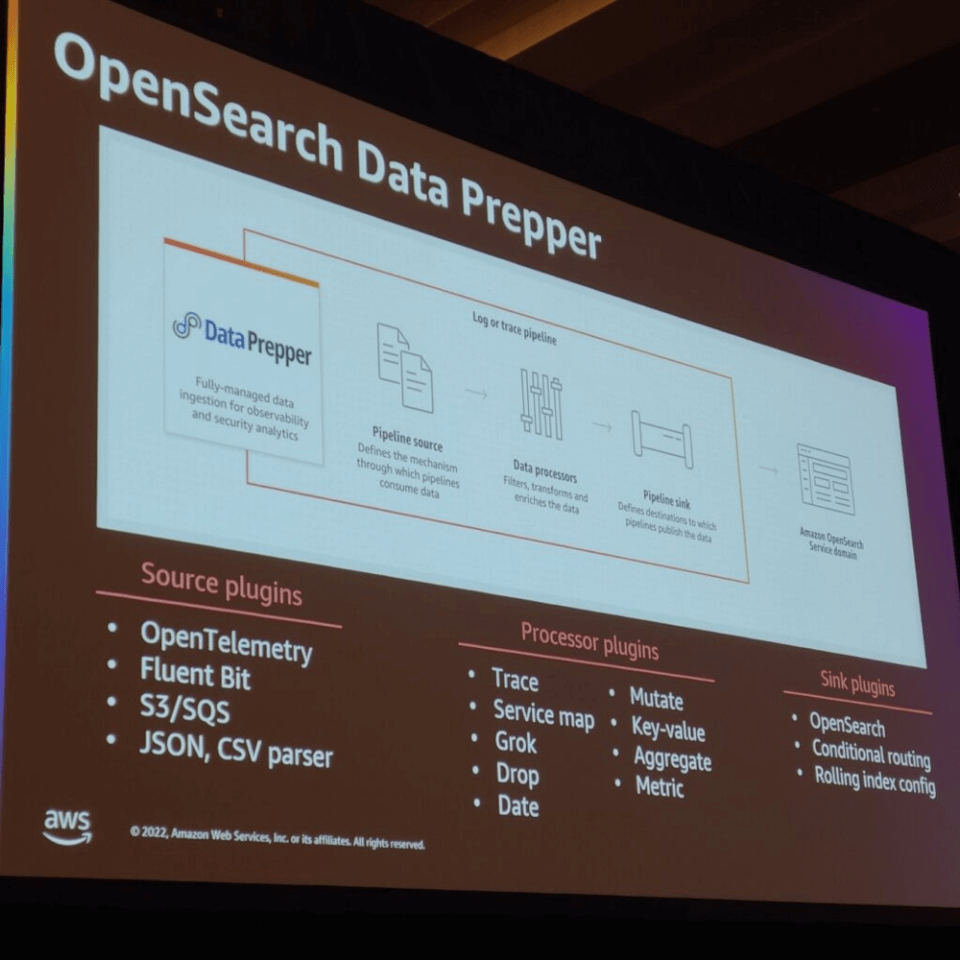
OpenSearch Data Prepperは、データパイプラインを作成するツールの紹介です。Plugin で複数のソリューションを統合できます。


OpenSearchのObservabilityを見てみましょう。
- 1. 分散追跡
- 2. APM
-
3. ログ監視とイベント分析
- 1)指標分析
- 特別な点として、OpenSearch 2.4以降ではPrometheusインジケーターをサポートしています。
- 1)指標分析
-
4. ログパターンの分析
- 1)異常動作(unexpected outliers)を検知できると何度も強調して説明しました。
- 2)log tailing, log surround and log monitoring 機能の実装が可能です。
-
5. 異常検出の強化
- 1)1分あたり100万のエンティティをサポート

最初の新機能はgp3ボリュームサポートです。
Gp3のサポートにより、従来のgp2ボリュームと比べて10%程度のコスト削減効果が見られるようになりました。

セキュリティの面では、AWS PrivateLinkのサポートにより、より細かなアクセス制御が可能になりました。

Blue/Green展開関連の機能が強化され、Auto-Tune、Shard-level indexing backpressureなど、運用自動化の面での機能強化と詳細なEventアラームが追加されました。

予定された改善機能とopensearchロードマップが簡単に紹介されました。

最後に、Opensearch 2.4の実験機能であるSecurity Analyticsについても簡単に紹介されました。
このセッションを聞きながら、Amazon opensearch serviceに関する最新情報に触れる絶好の機会だったと思いました。広げられるようになって良いセッションだったようです。
今後、Opensearchを通じて検索エンジンやObesrvabilityを活用したログ分析などの導入を提案してみてもいいようです。
