GUI の ETL ツール Google Cloud Dataprep by Trifacta を使ってみた
- Google Cloud
- データ分析
- AI/ML
- エンジニア
投稿日:
はじめに
Google Cloud Dataprep by Trifacta(以下、Dataprep と呼称します。)は、Google と Trifacta が連携して提供する GUI の ETL ツールです。
本記事では、Dataprep のクイックスタートの手順を参考にハンズオンを実施し、Dataprep の基本的な使い方とその利便性について確認します。
事前準備
- Google Cloud のプロジェクトを作成し、課金を有効化します。
- 下記 サービスと API を有効化します。
- Dataflow
- BigQuery
- Cloud Storage APIs
ここでは詳細な手順は割愛します。Google の公式ドキュメントを参照してください。
参考:Google Cloud プロジェクトをセットアップする
参考:API を有効にしています
手順
1. Dataprep の有効化
はじめにでお伝えした通り、Dataprep は Google と Trifacta が連携して提供しています。
そのため、利用にあたっては Trifacta によるプロジェクト内のデータへのアクセス等を許可する必要があります。
本手順では、Dataprep の利用開始に伴い必要な操作を解説します。
1-1. 各種同意及び許可
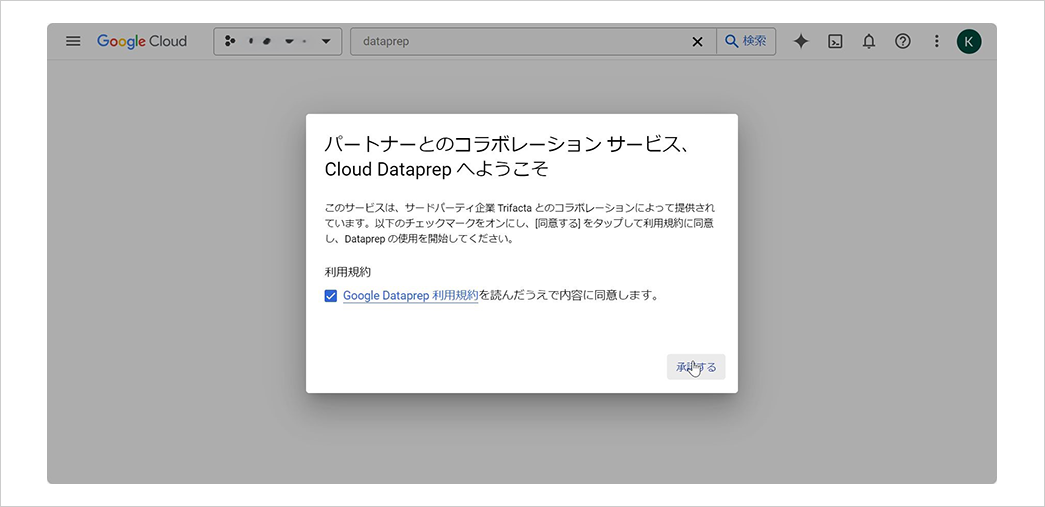
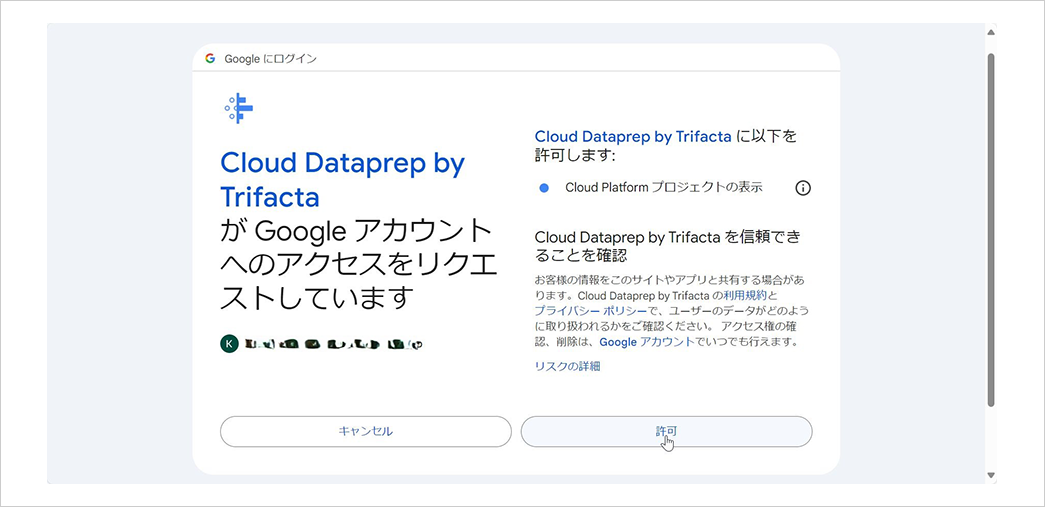
Dataprep を初めて利用する場合は、以下の確認画面が表示されるため、利用規約を確認して同意します。
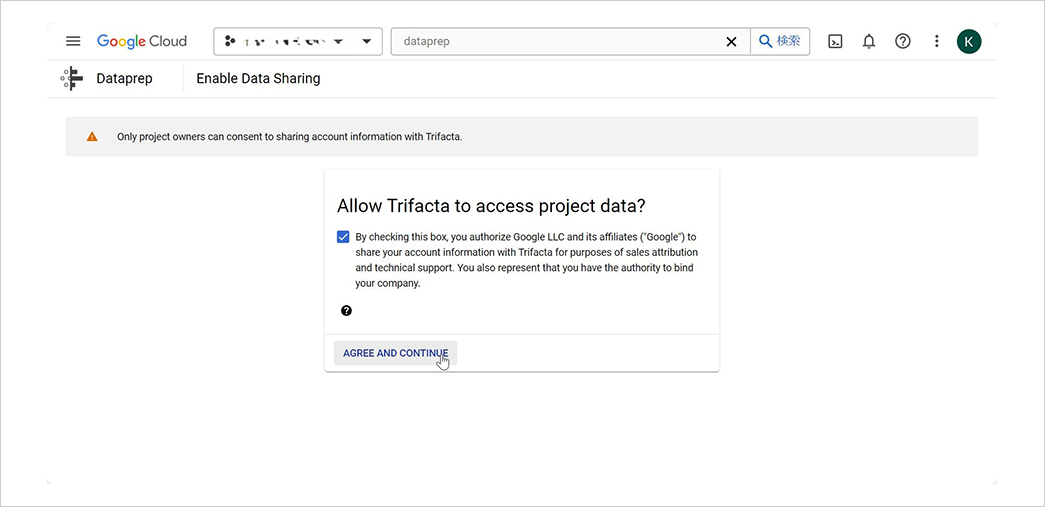
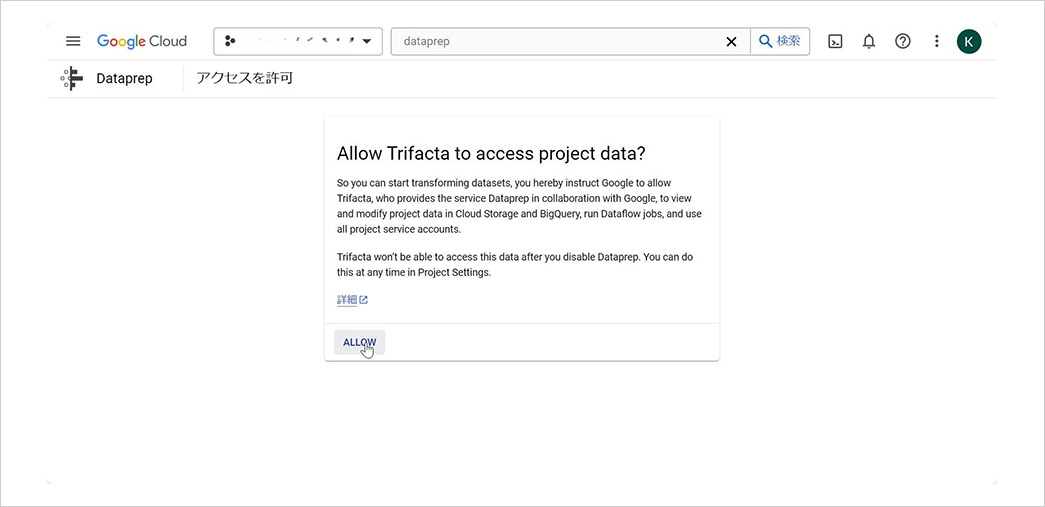
続けて Google から Trifacta への情報提供や、Trifacta によるプロジェクト内のデータへのアクセスについて確認画面が表示されるため、同意します。
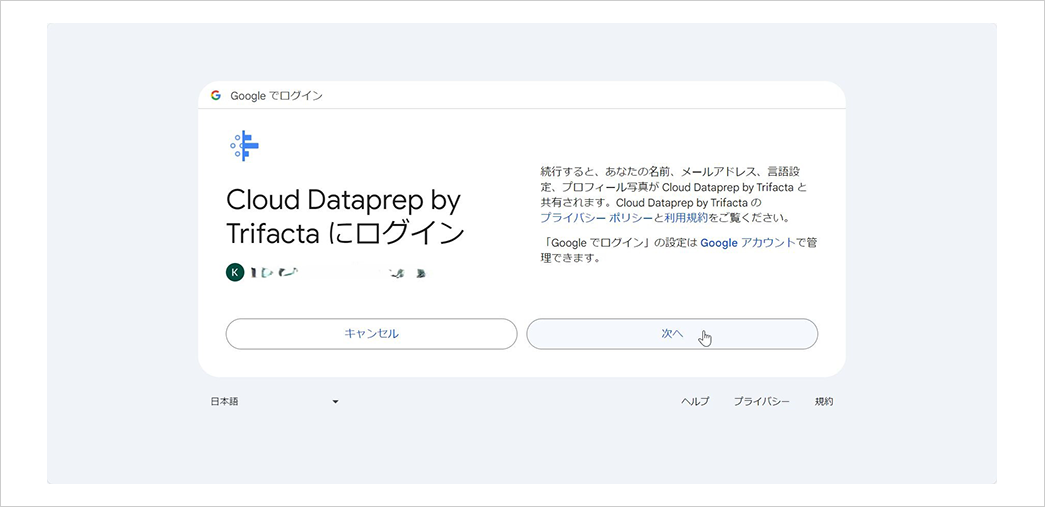
Dataprep へログインします。
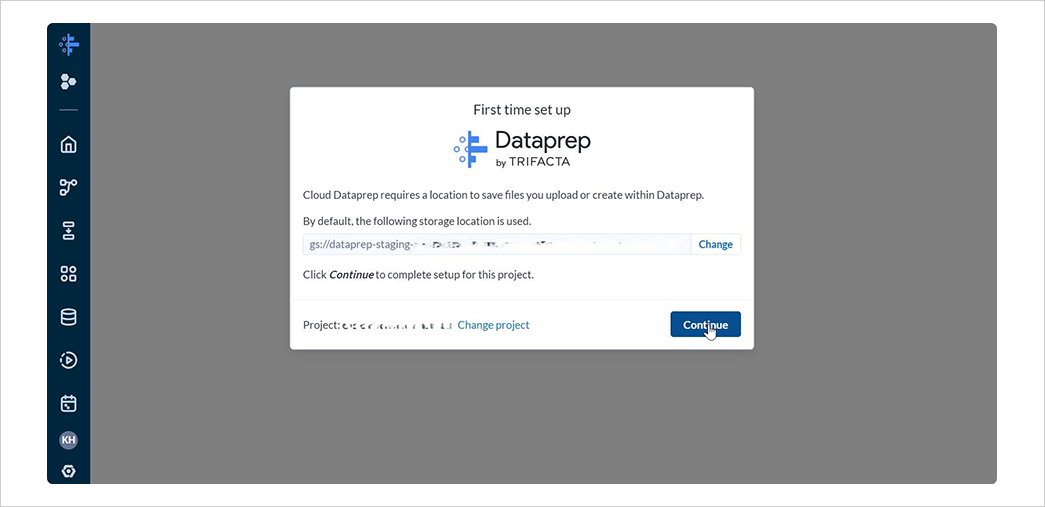
1-2. ステージングバケットの設定
Dataprep の利用にあたり、Dataprep 内で利用するデータを保存するためのストレージ(ステージングバケット)を設定する必要があります。
デフォルトでは US リージョンに自動で作成されるため、デフォルトのままステージングバケットを設定します。
ステージングバケットの設定が完了すると、Dataprep が利用可能となります。
2. フローの作成
Dataprep では、どの元データ(データセット)に対し、どんな処理(レシピ)を実施し、どのようにアウトプットするのかを定義したものをフローと呼びます。
本手順では、フローを作成する方法について解説します。
2-1. フローの作成
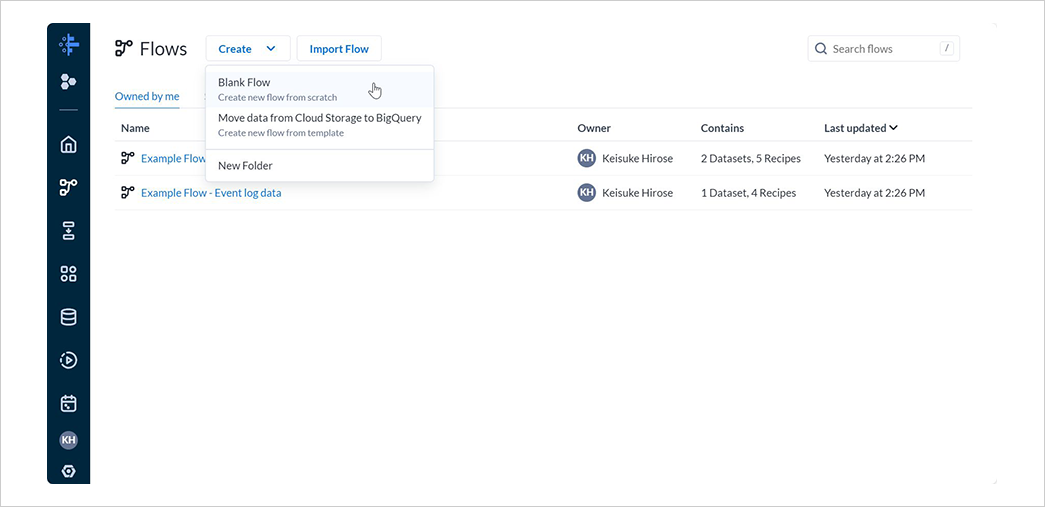
Dataprep のコンソール画面にて、左側のナビゲーションバーからFlowsを選択します。
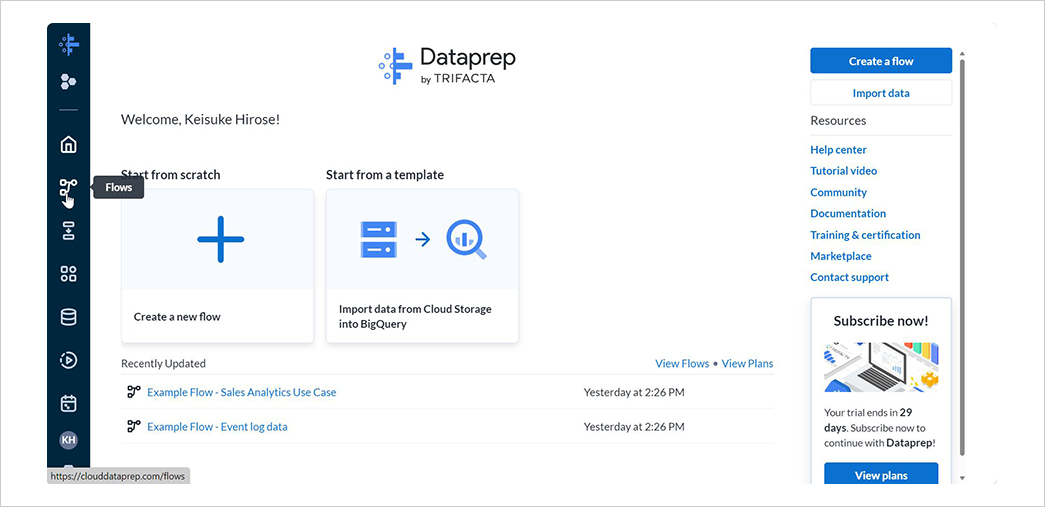
CreateからBlank Flowを選択してフローを作成します。
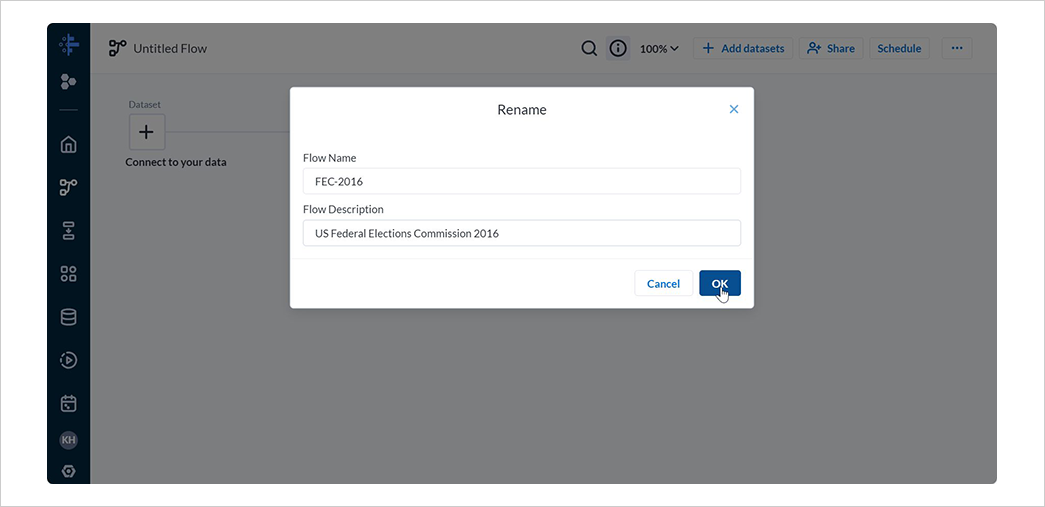
2-2. フロー名の編集
フローの名称や説明は、フロー名を選択することで編集できます。
クイックスタートでは、米国連邦選挙委員会の 2016 年のデータを利用しているため、名前と説明をそのように編集します。
3. データセットのインポート
本手順では、フローで処理する元データ(データセット)のインポートの方法を解説します。
3-1. データセットの選択
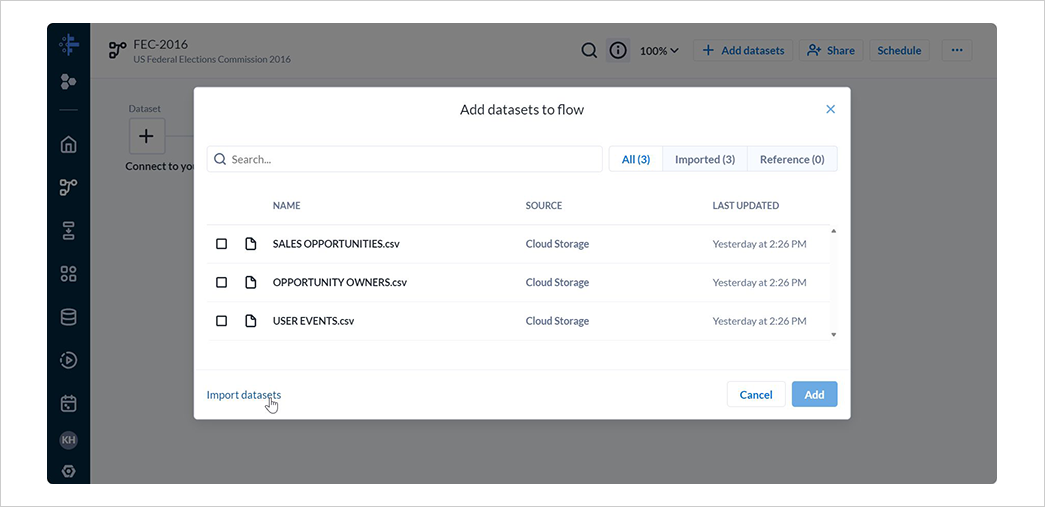
フロー画面にてDatasetの+を選択します。
利用可能なデータセットが表示されますが、今回は新たにインポートするため、Import datasetsを選択します。
3-2. データセットのインポート
データセットのインポート画面からCloud Storageを選択し、検索欄に今回インポートするデータが保存されているバケットのパスgs://dataprep-samples/us-fecを入力してGoを選択します。
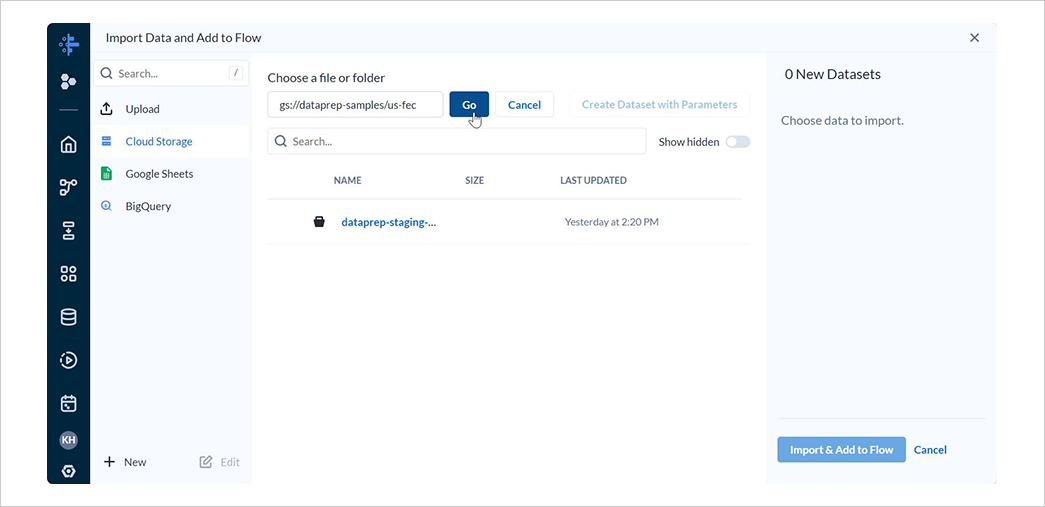
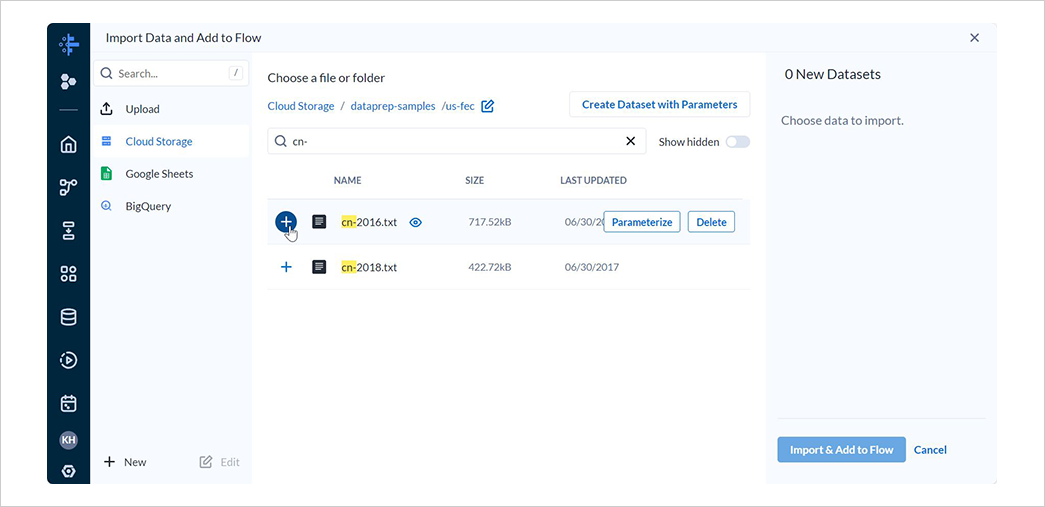
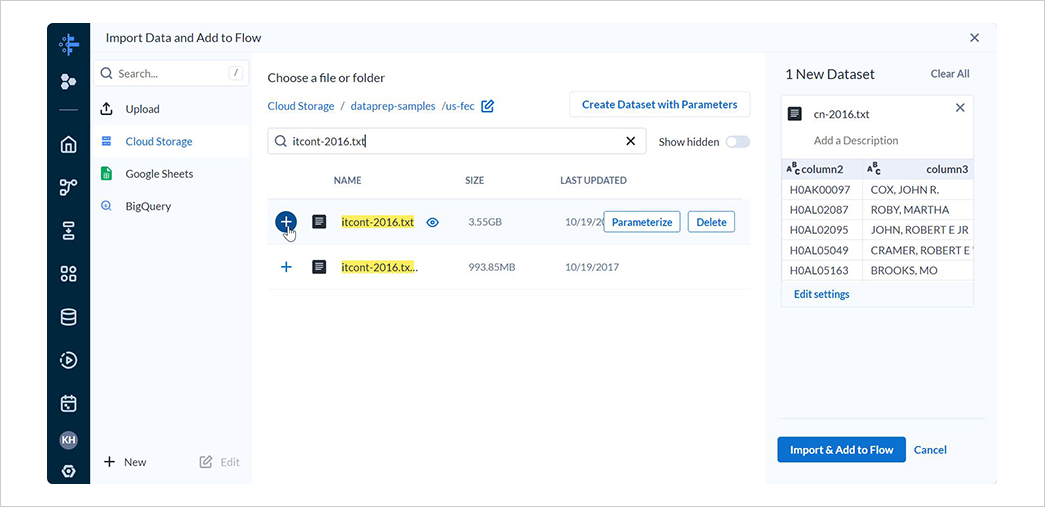
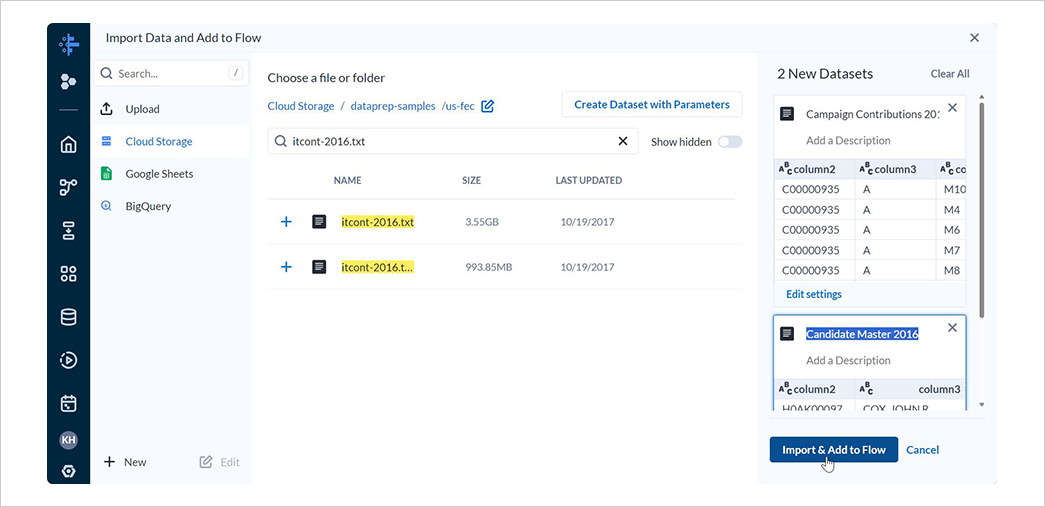
cn-2016.txtとitcont-2016.txtの 2 つのファイルを選択し、それぞれデータセット名をCandidate Master 2016とCampaign Contributions 2016に変更した後、Import & Add to Flowを選択します。
なお、Candidate Master 2016は候補者マスターデータ、Campaign Contributions 2016は選挙献金データです。
3-3. フローの確認
フローに 2 つのデータセットが追加されていることを確認します。
1 つめのデータセットには、デフォルトで空のレシピとアウトプットが追加されています。
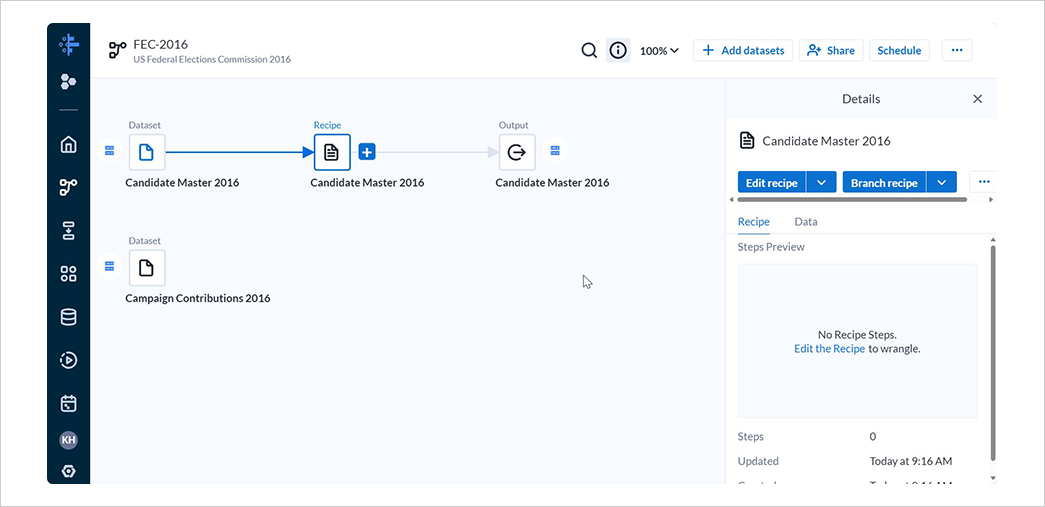
4. レシピの作成(その1)
本手順では、候補者マスターデータに対するレシピ(処理の定義)の作成方法を解説します。
処理の内容としては、候補者マスターデータから 2016 年の選挙における大統領候補を抽出します。
4-1. レシピの編集
デフォルトで作成された空のレシピを選択し、Edit recipeを選択します。
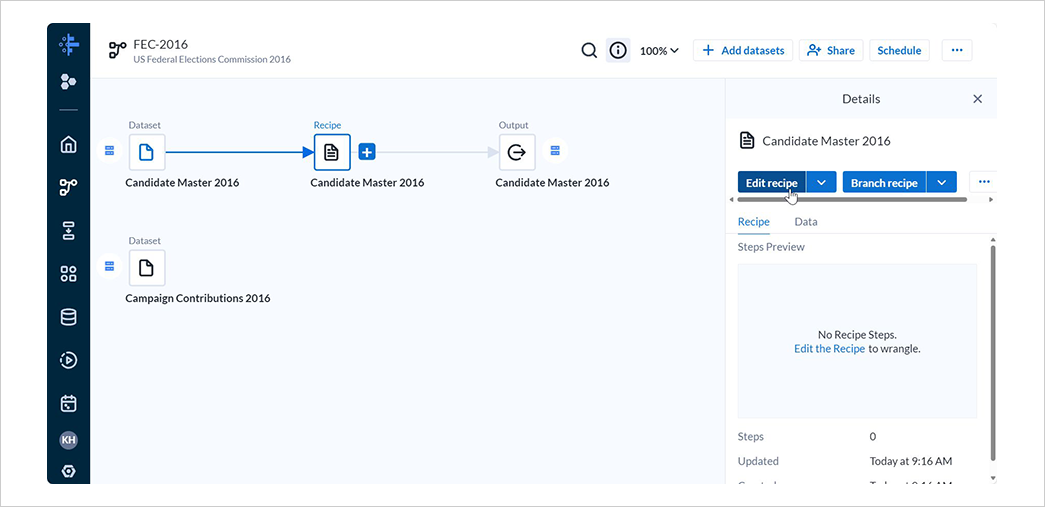
レシピの編集画面では、データセットのプレビューと処理の内容が確認できます。
大規模なデータセットの場合は、データセットの最初の数行がプレビューとして表示されています。
最初の数行以外を表示したい場合には、initial dataからプレビューの設定を変更できます。
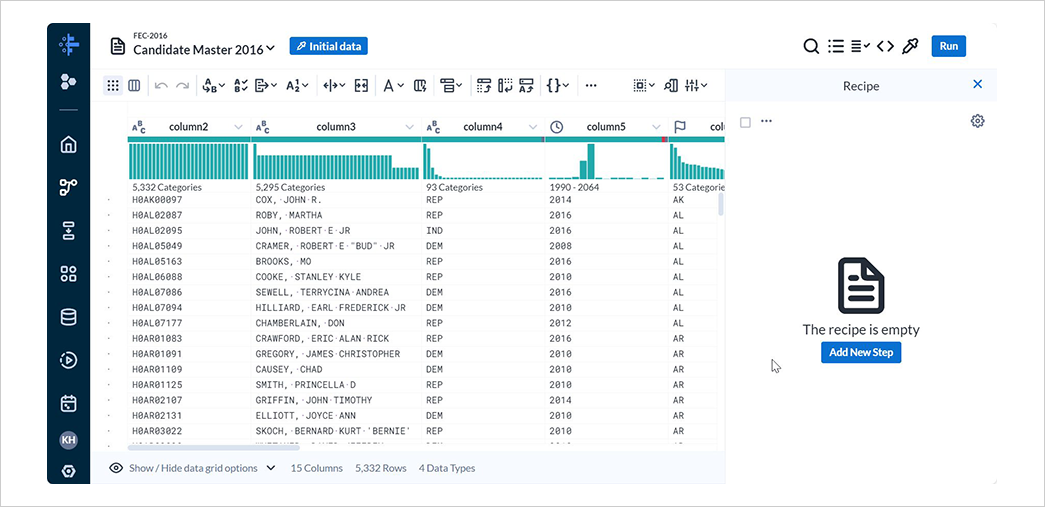
4-2. 年度の抽出
レシピの編集画面では、各列における値の分布をヒストグラムで確認できます。
column2は候補者IDなので、各値が一意であることが分かります。
column5は年度で、カーソルを当てると行数や割合などが確認できます。
ただし、データセット全体ではなく、プレビューとして表示されているデータの範囲での分布であることに注意してください。
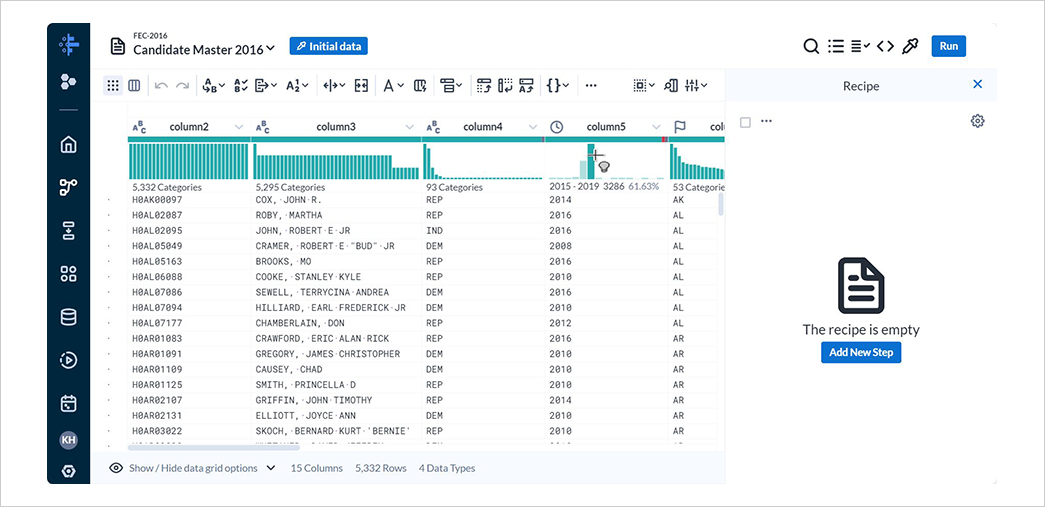
column5にて 2016 年を含んだ範囲のバーを選択すると、Suggestionsが表示されます。
Keep rowsには、選択した範囲でデータを抽出する式が表示されています。
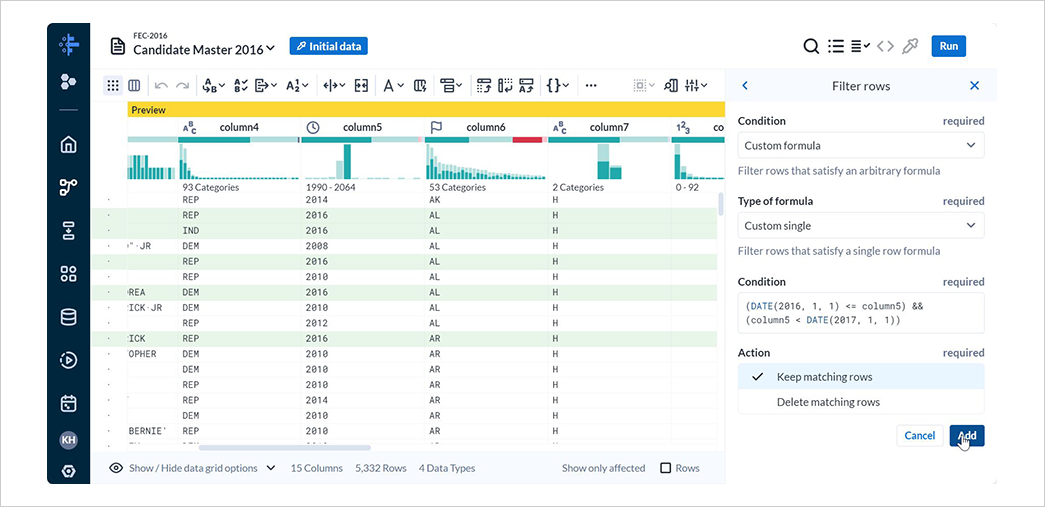
2016 年のデータのみを抽出するため、Editを選択します。
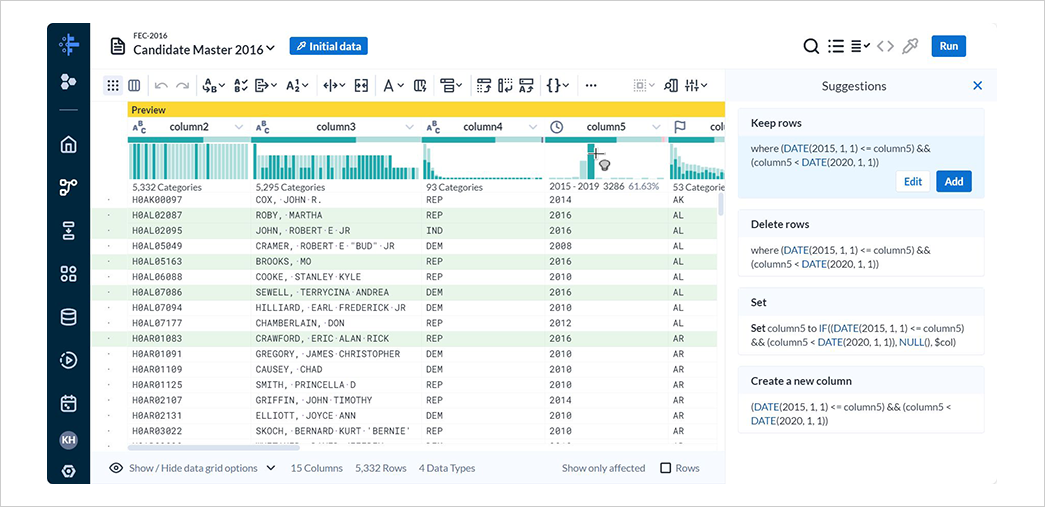
Conditionの式を 2016 年のデータのみを抽出するように修正し、Addを選択します。
レシピに処理が追加されたことを確認します。
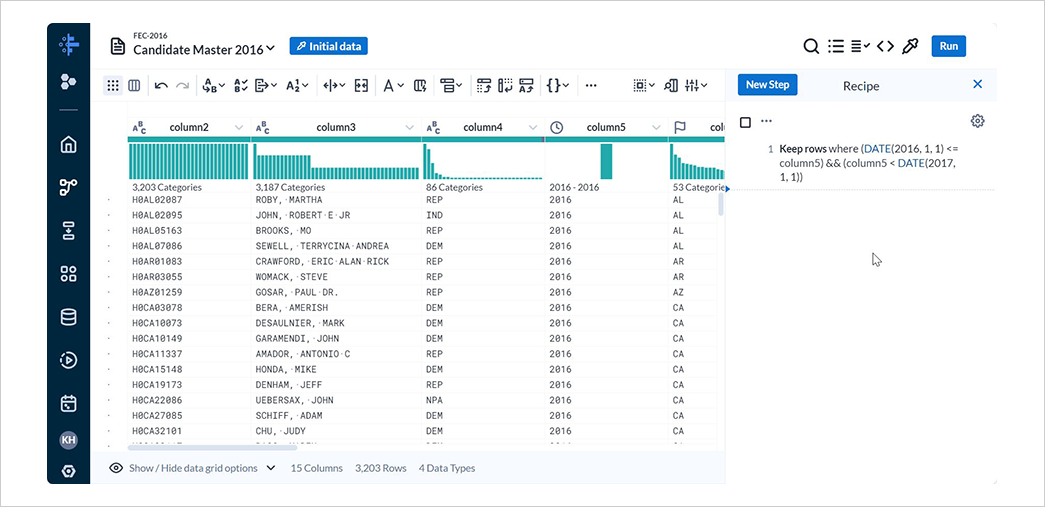
4-3. データ型の修正
column6は州ですが、ヒストグラムの上部に赤色のバーが表示されています。
説明文にはmismatched valuesとの記述があります。
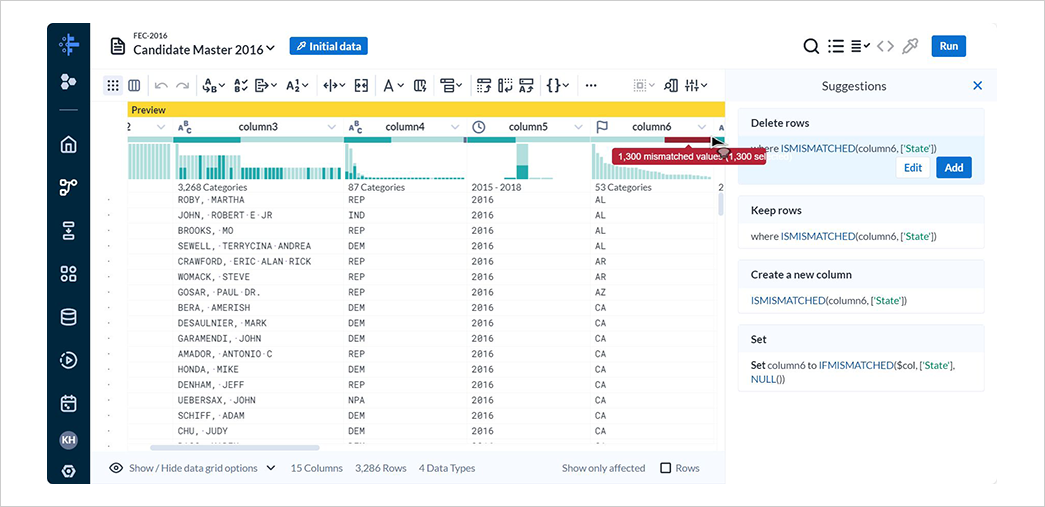
赤色のバーを選択した状態で、Show only affected Rowsをチェックすると、原因となっている行が表示されます。
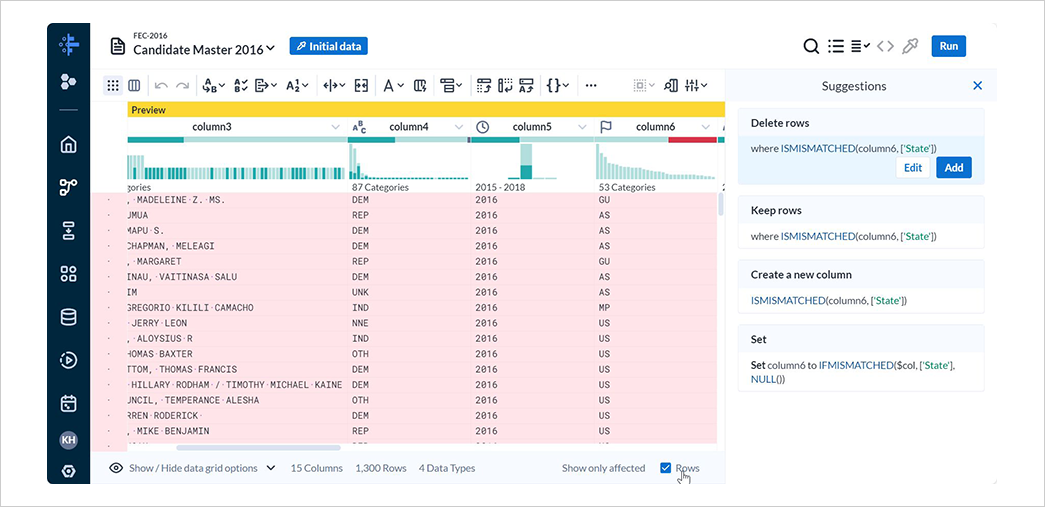
これは、column6のデータ型がState(州)であるのに対し、US(国)やGU(島嶼地域、例:グアム)などが含まれており、データ型と不一致しているためです。
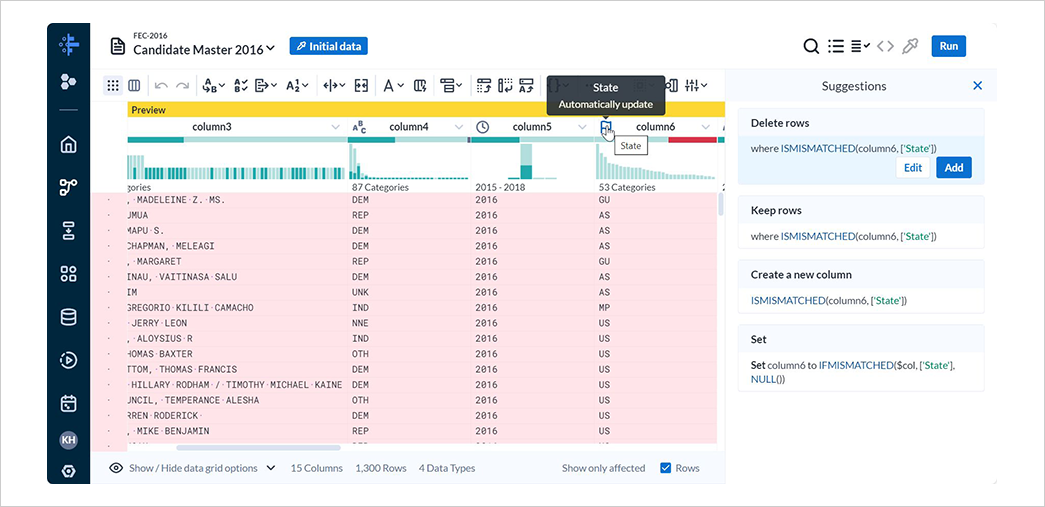
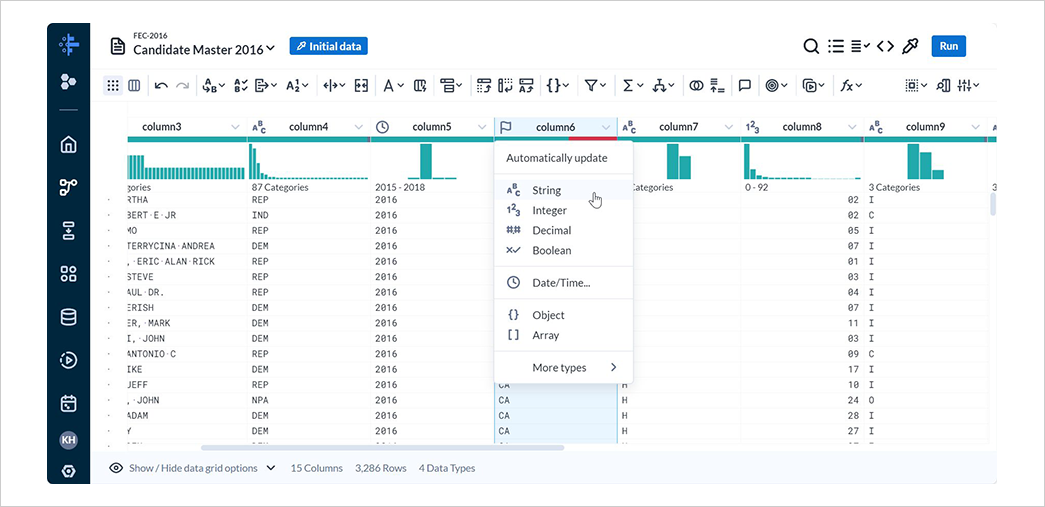
cloumn6のデータ型をStirngに変更し、データ型との不一致を解消します。
バーが全て緑色になったことを確認します。
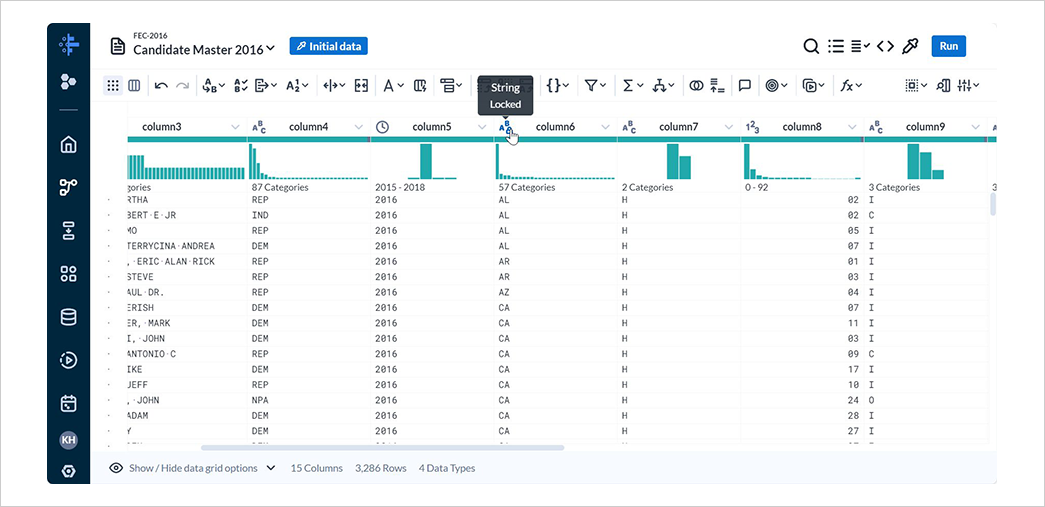
4-4. 大統領候補の抽出
column7は候補者が大統領候補(P)なのか、副大統領候補(H)なのかを表します。
P(大統領候補)のバーを選択し、SuggestionsからKeep rowsのAddを選択して大統領候補のみを抽出します。
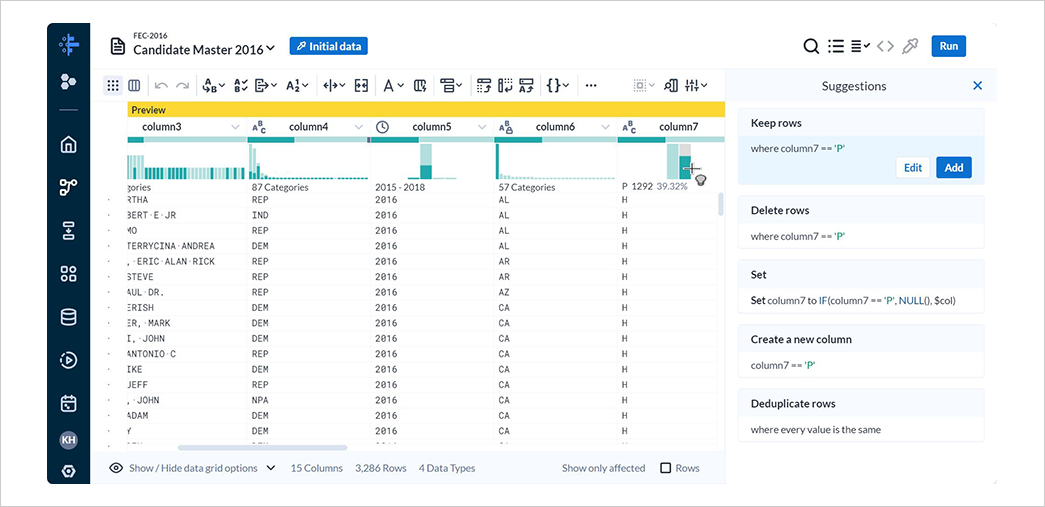
以上で候補者マスターデータから 2016 年の大統領候補を抽出するレシピが完成しました。
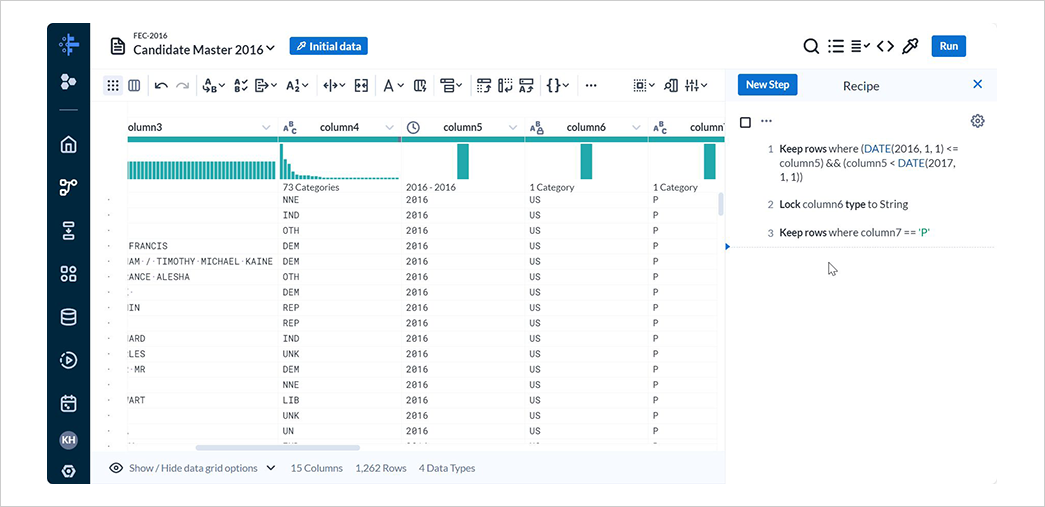
5. レシピの作成(その2)
本手順では、選挙献金データに対するレシピ(処理の定義)の作成方法を解説します。
処理の内容としては、選挙献金データから余分な区切り文字を削除した後、加工後の候補者マスターデータと結合し、献金に関するサマリーを生成します。
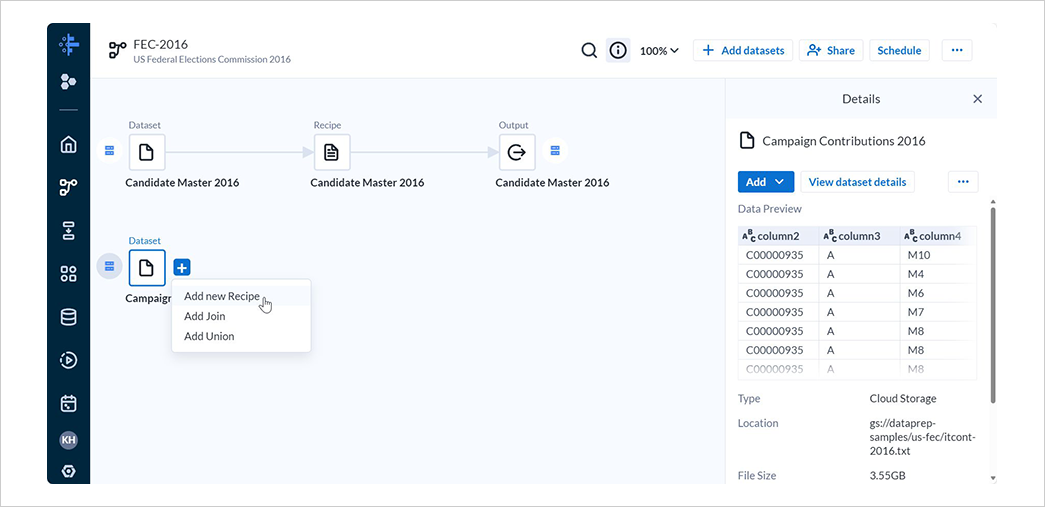
5-1. レシピの作成
フロー画面にて、2 つ目のデータセットの+を選択し、Add new Recipeを選択します。
5-2. 区切り文字の削除
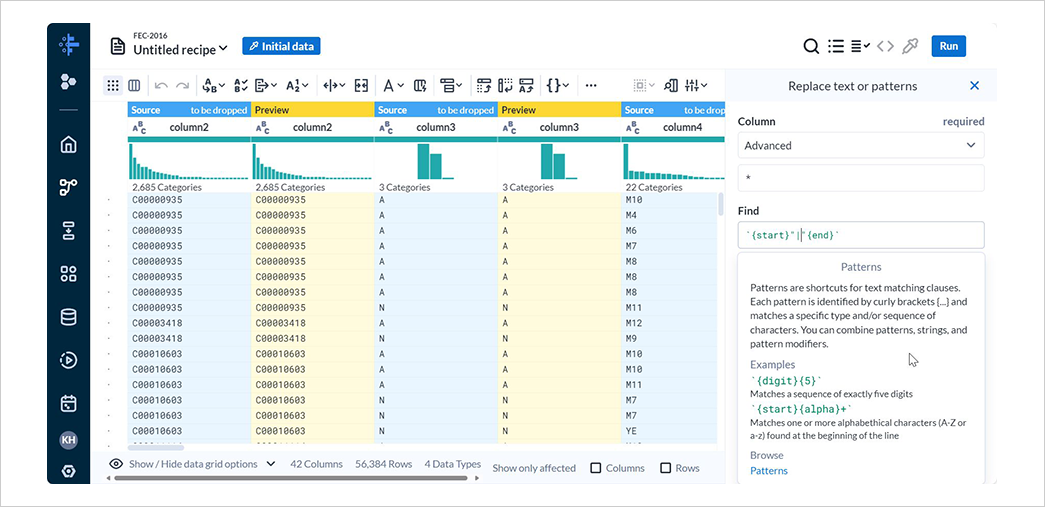
レシピの編集画面でReplaceのText or patternを選択します。
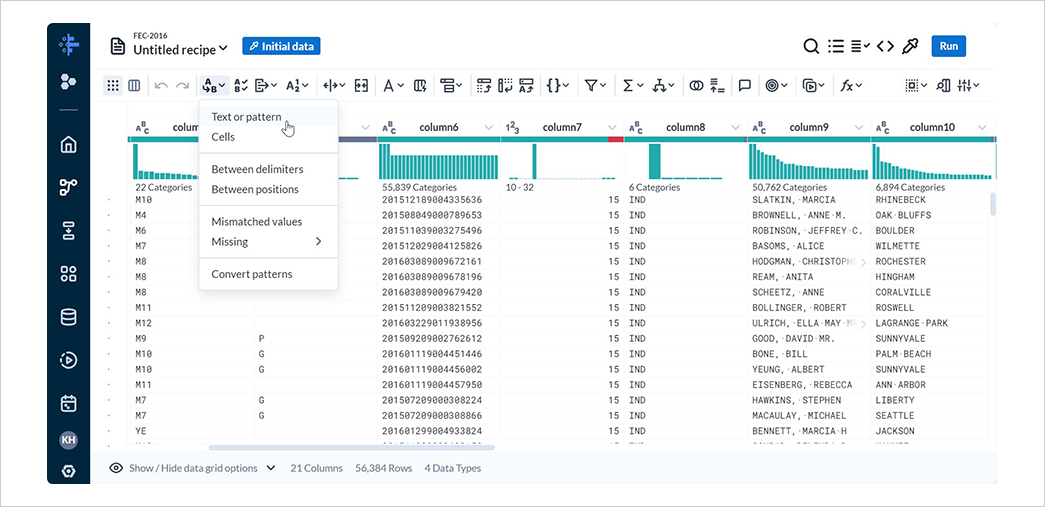
Columnでは、置換する列の選択ができます。
Multipleでは複数の列を、Allではすべての列を、Rangeでは連続する列の範囲を、AdvancedではMultipleとRangeを組み合わせた形で列を指定できます。
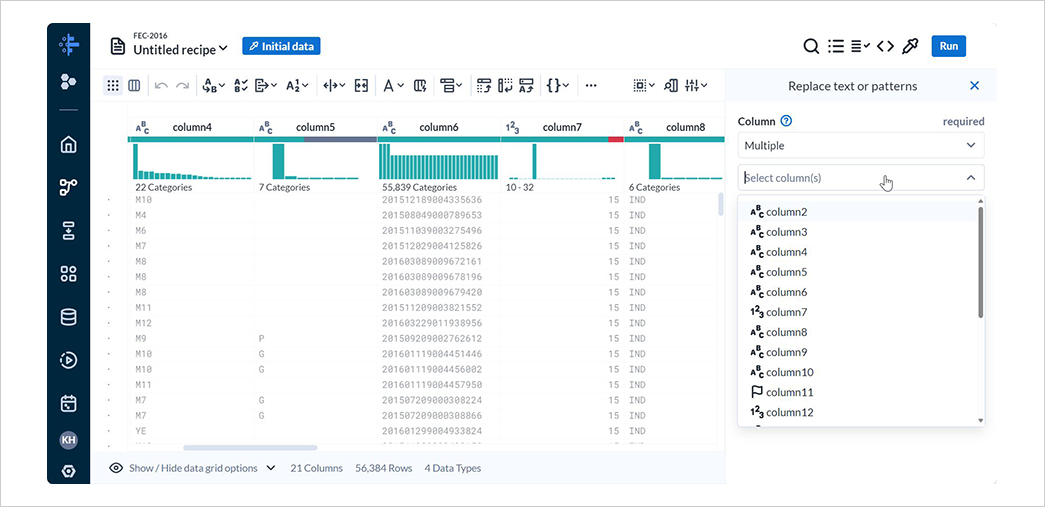
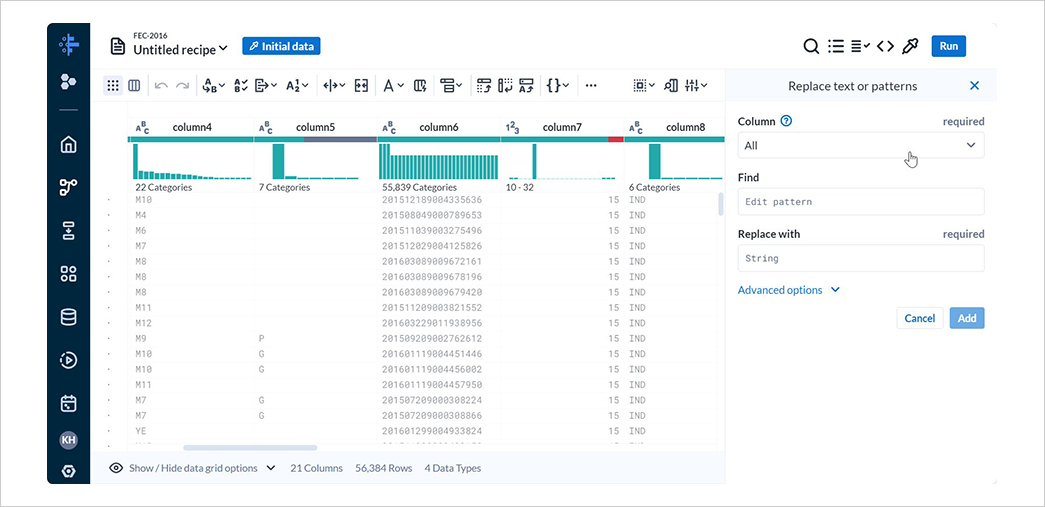
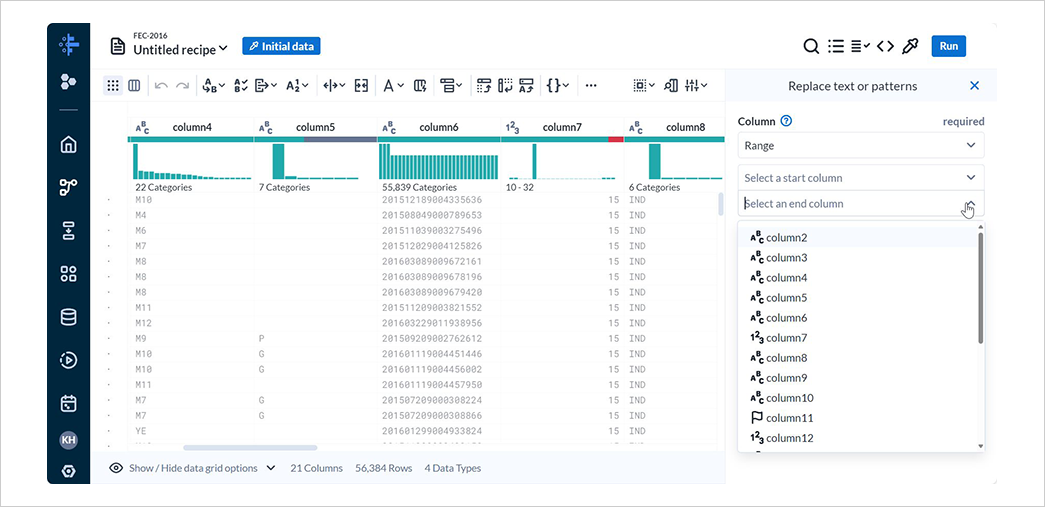
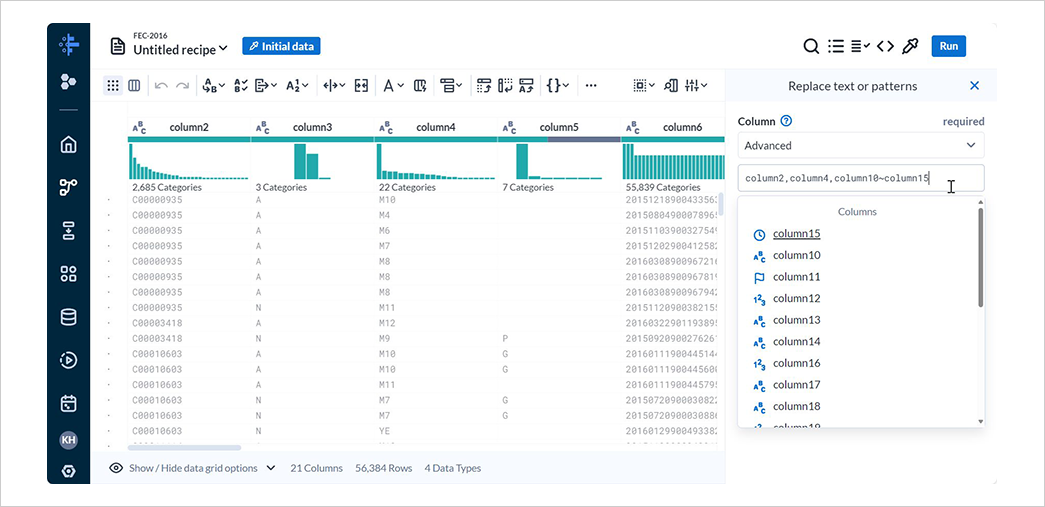
Advancedで*を指定してすべての列を対象に設定し、Findに {start}"|"{end} と入力してAddを選択します。
{start}は正規表現における^に相当し、{end}は正規表現における$に相当します。
置換後の文字を空欄のままとしているため、"|"に完全一致する値を削除する処理が追加されます。
5-3. データセットの結合
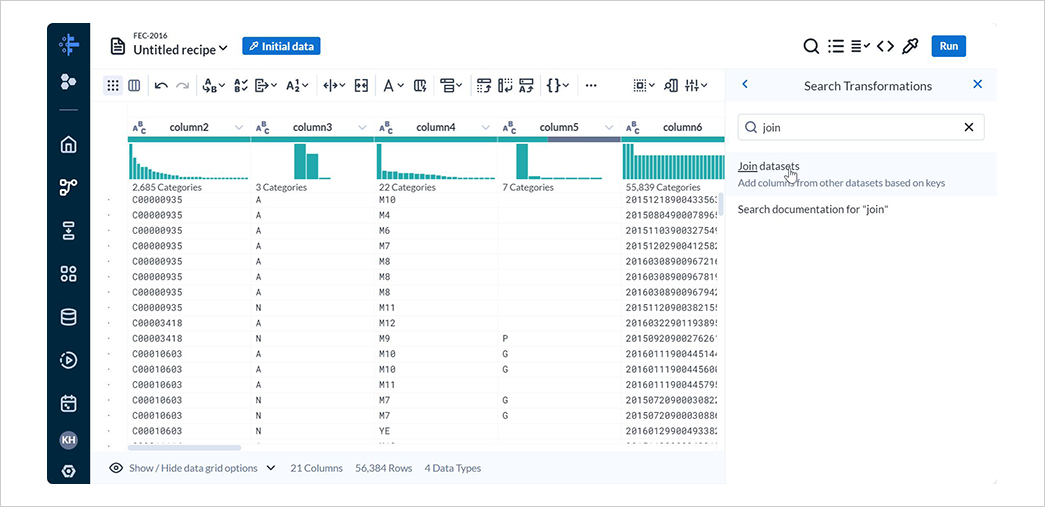
New Stepを選択して表示される検索欄にjoinと入力し、Join datasetsを選択します。
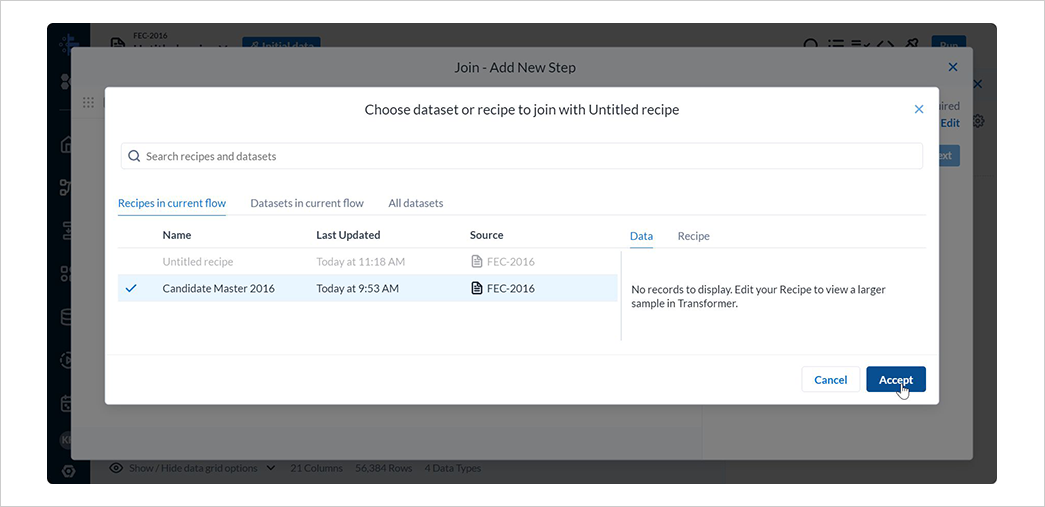
Recipes in current flowタブにて、4. レシピの作成(その 1)で作成した候補者マスターデータのレシピを選択し、Acceptを選択します。
Join keysの編集アイコンを選択します。
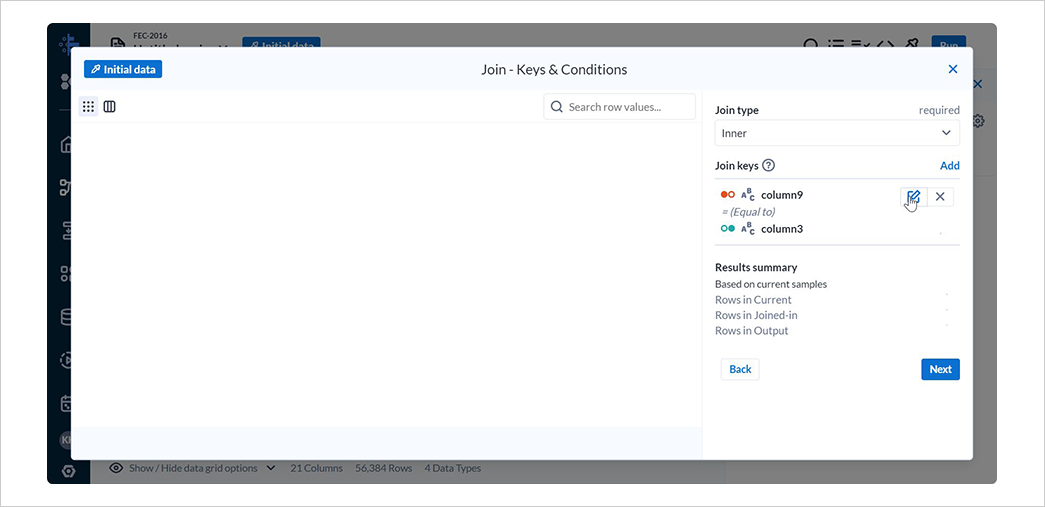
Currentにcolumn2を、Joined-inにcolumn11を指定し、Save and Continue、Nextと選択します。
候補者IDをキーとして 2 つのデータを結合しています。
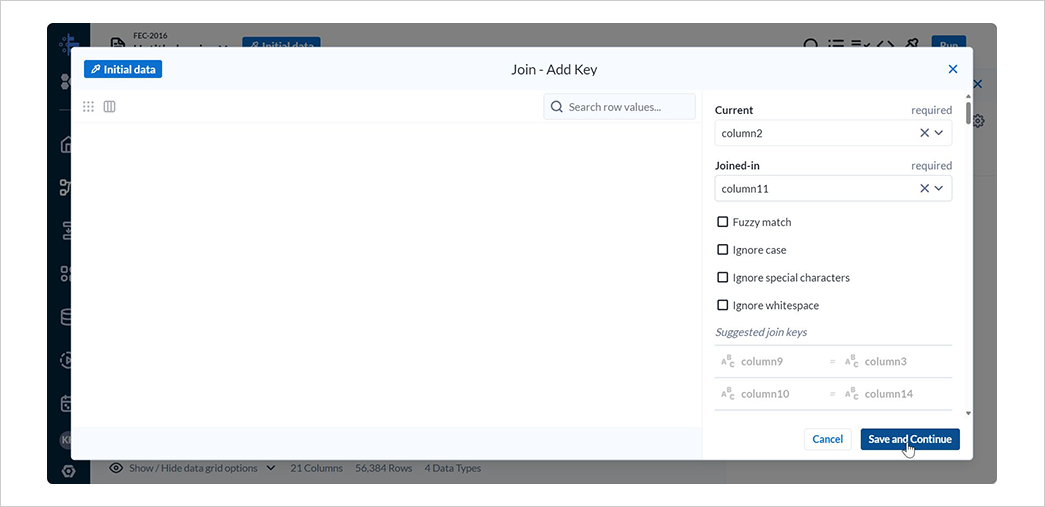
結合後のデータに全ての列を表示するため、全ての列のチェックボックスをチェックし、Review、Add to Recipeと選択します。
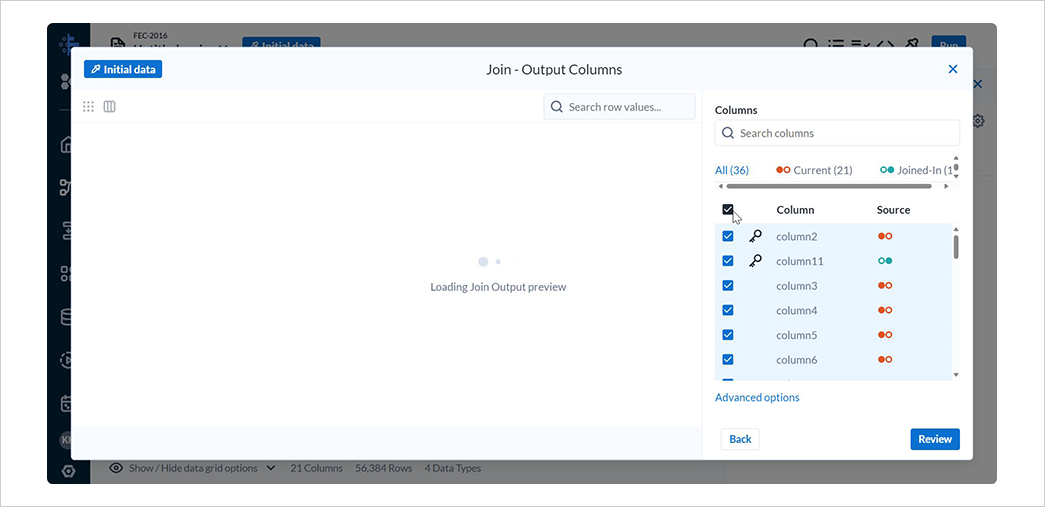
レシピに処理が追加され、データが結合されていることを確認します。
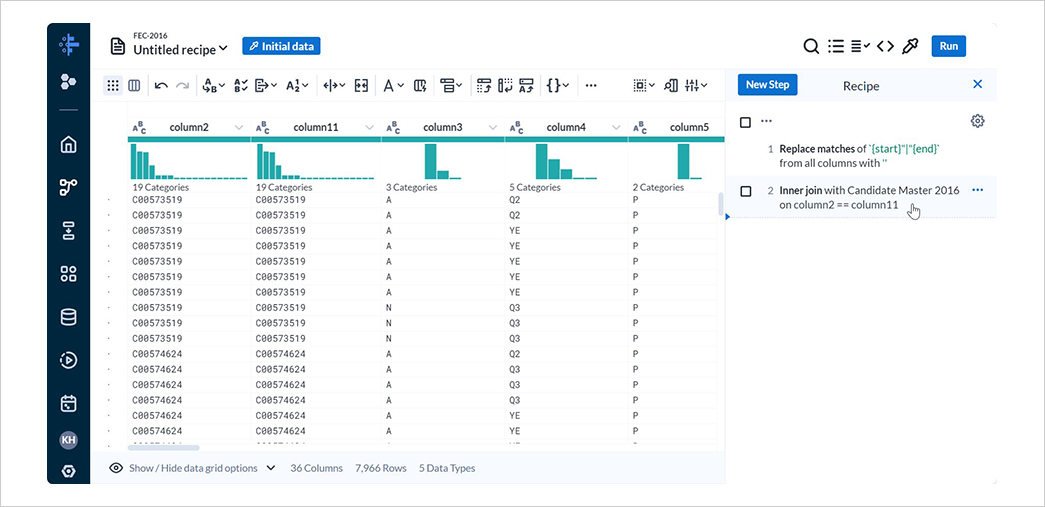
5-4. 献金データのサマライズ
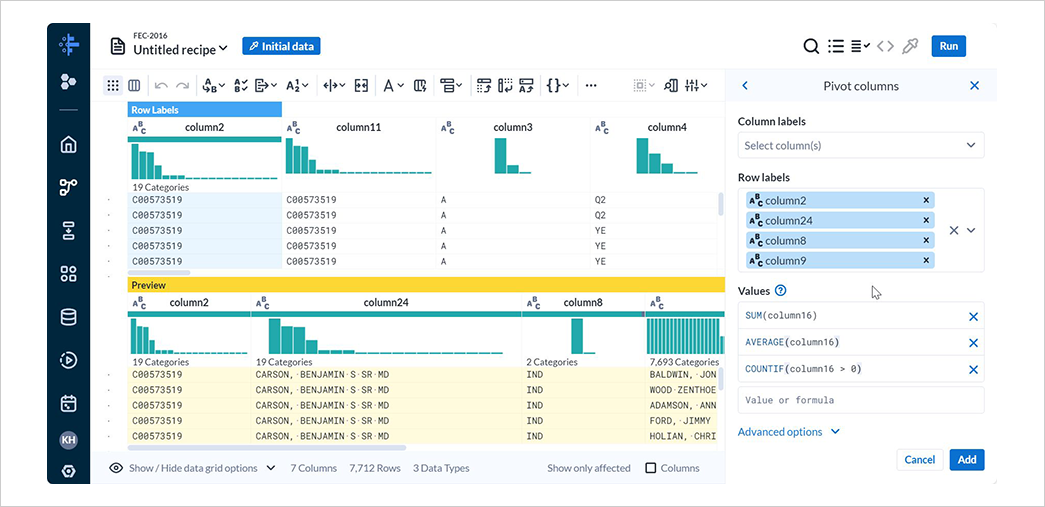
New Stepを選択して表示される検索欄にpivotと入力し、Pivotを選択します。
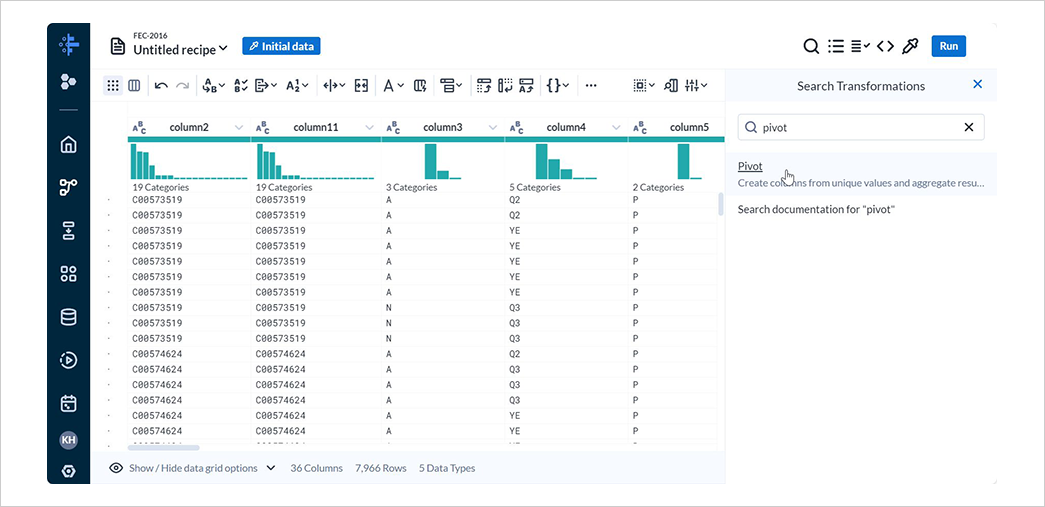
Row labelsに以下の行を指定します。
それぞれ候補者ID、候補者名、所属政党、献金者です。
- column2
- column24
- column8
- column9
Valuesには以下の式を入力します。
それぞれ合計献金額、平均献金額、献金回数です。
- SUM(column16)
- average(column16)
- contif(column16 > 0)
Addを選択しデータをサマライズします。
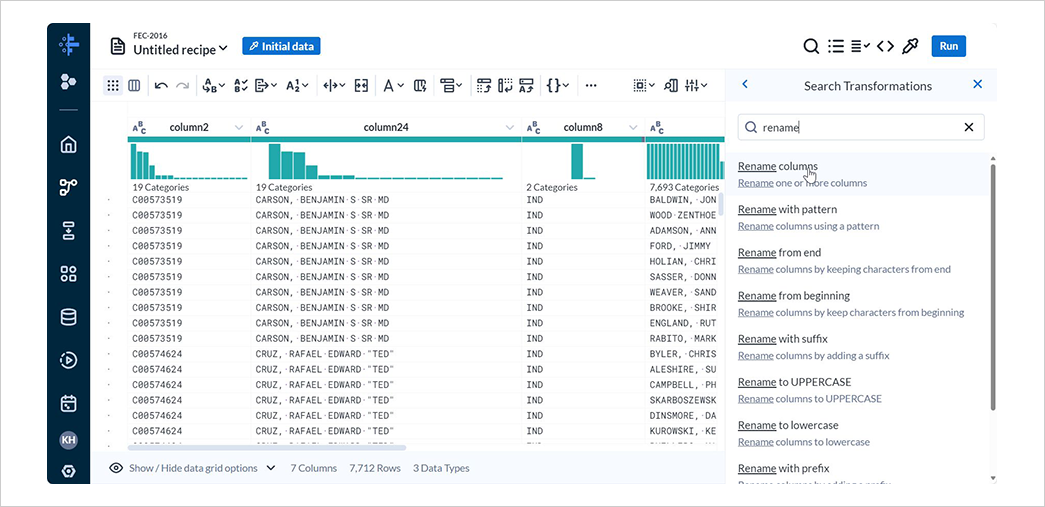
5-5. 列名の編集
New Stepを選択して表示される検索欄にrenameと入力し、Rename columnsを選択します。
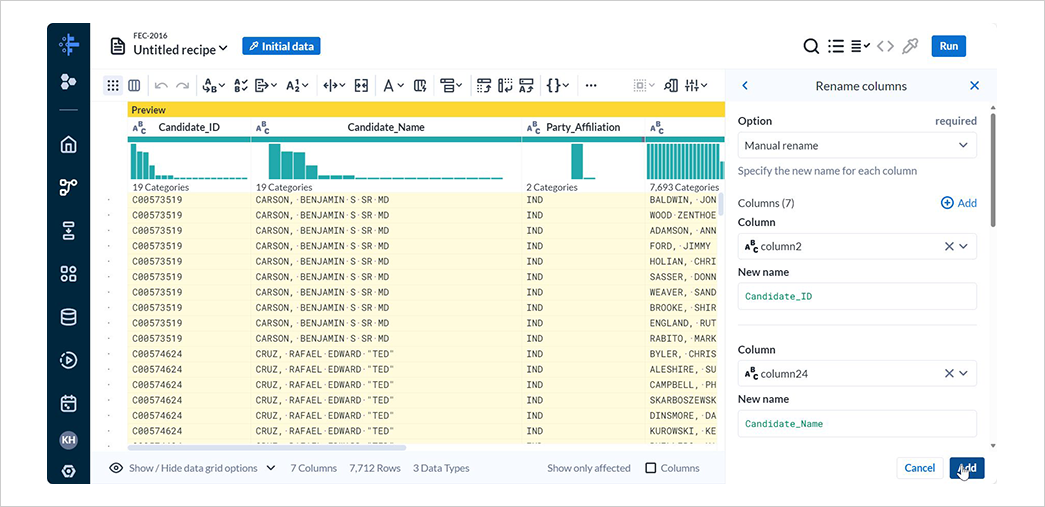
OptionにManual renameを選択し、以下の通りに各列名を変更しAddを選択します。
| 変更前 | 変更後 |
|---|---|
| column2 | Candidate_ID |
| column24 | Candidate_Name |
| column8 | Party_Affiliation |
| column9 | Donor_Name |
| sum_column16 | Total_Contribution_Sum |
| average_column16 | Average_Contribution_Sum |
| contif | Number_of_Contributions |
5-6. 端数処理
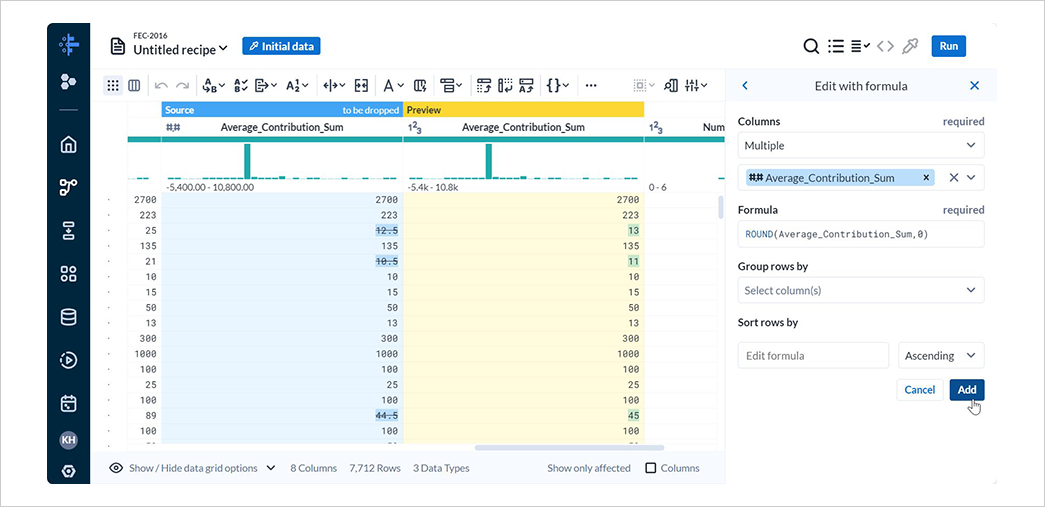
New Stepを選択して表示される検索欄にeditと入力し、Edit with formulaを選択します。
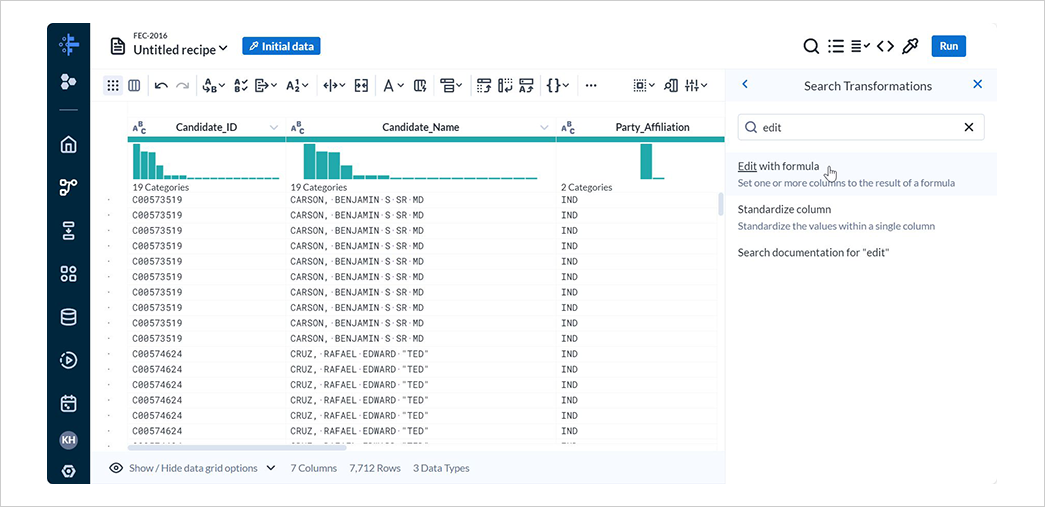
ColumnsにMultipleのAverage_Contribution_Sumを指定し、FormulaにROUND(Average_Contribution_Sum,0)と入力してAddを選択します。
6. ジョブの実行
本手順では、レシピで定義した処理を実際に実行し、加工後のデータをアウトプットする方法を解説します。
6-1. アウトプットの設定
選挙献金データに対するレシピの編集画面右上からRunを選択します。
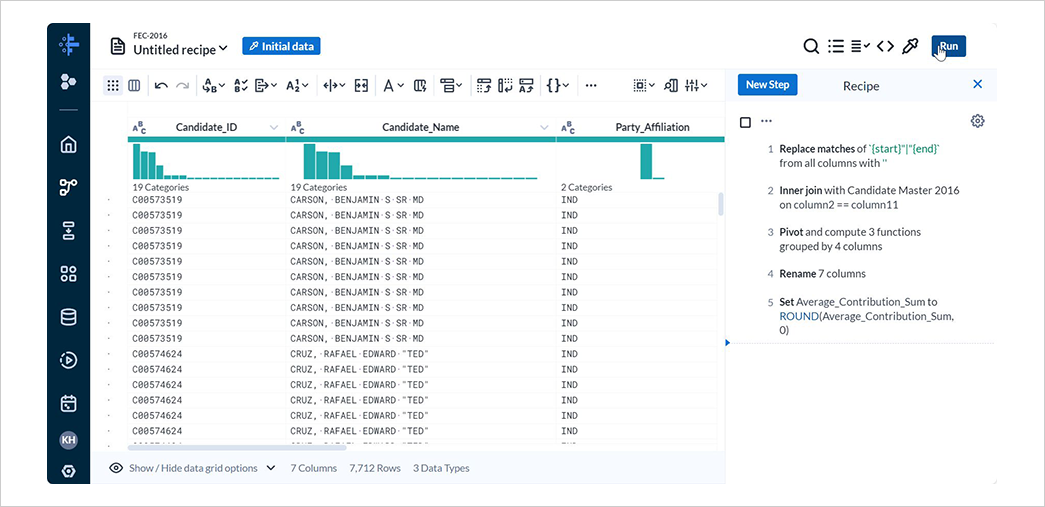
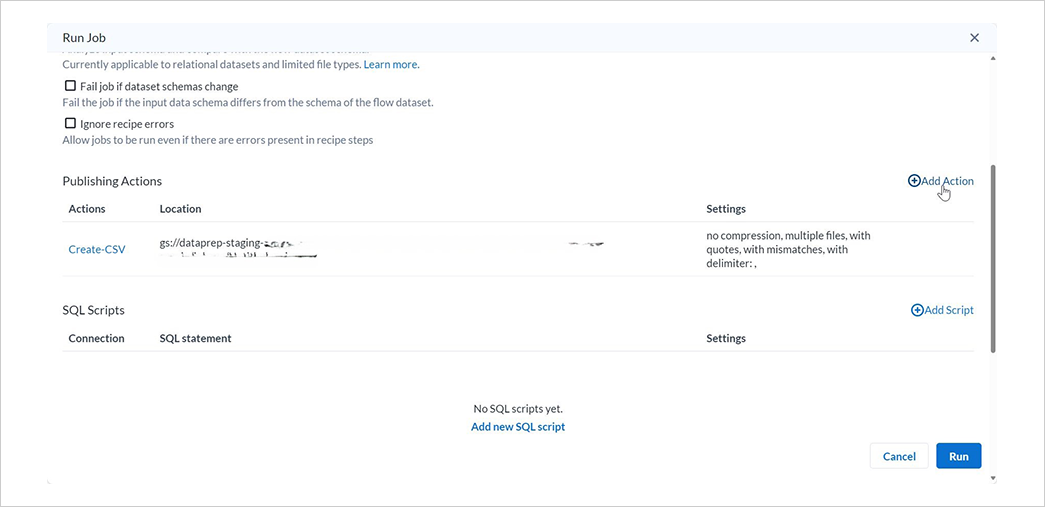
Publishng ActionsのAdd Actionを選択します。
なお、デフォルトで csv ファイルを CloudStorage にアウトプットするアクションが設定されています。
Create a new fileを選択します。
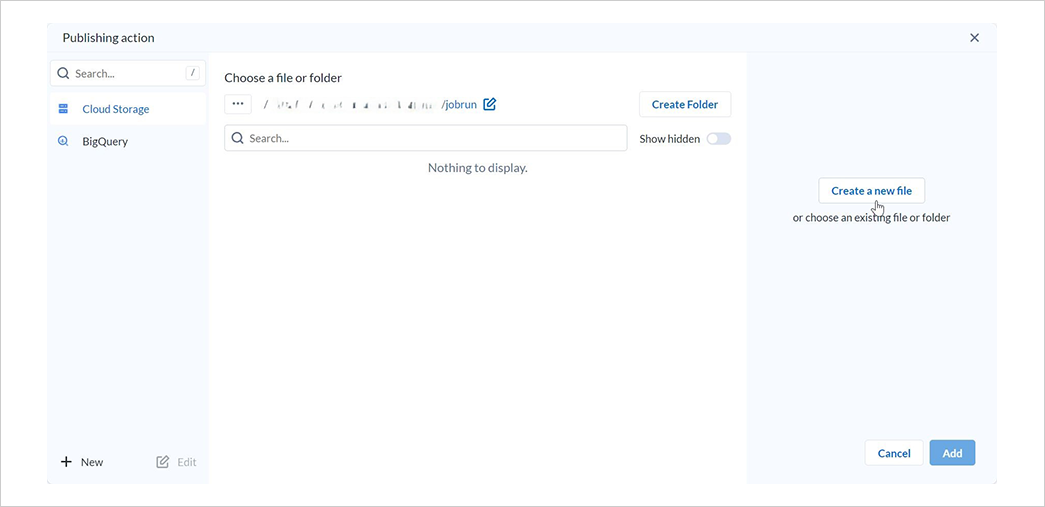
ファイル名を入力してフォーマットにJSONを指定した後Addを選択します。
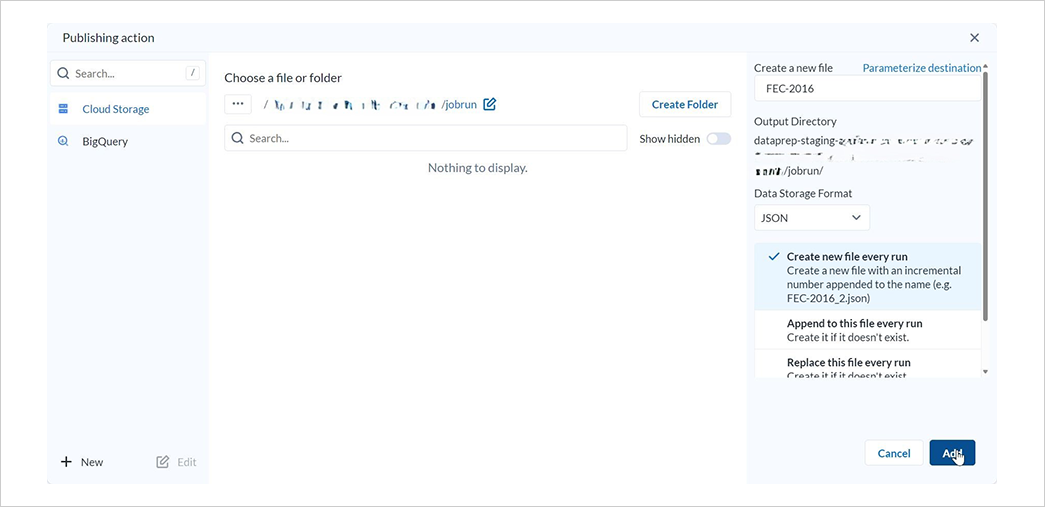
6-2. ジョブの実行
アクションが追加されたことを確認し、Runを選択します。
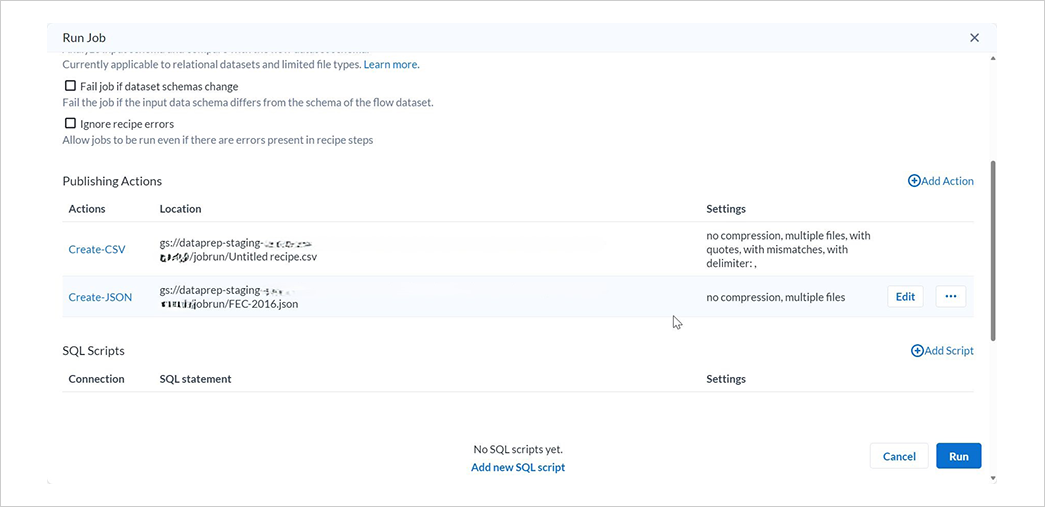
6-3. ジョブの確認
左側のナビゲーションバーからJob historyを選択し、対象のレシピ名を選択して進行状況を表示します。
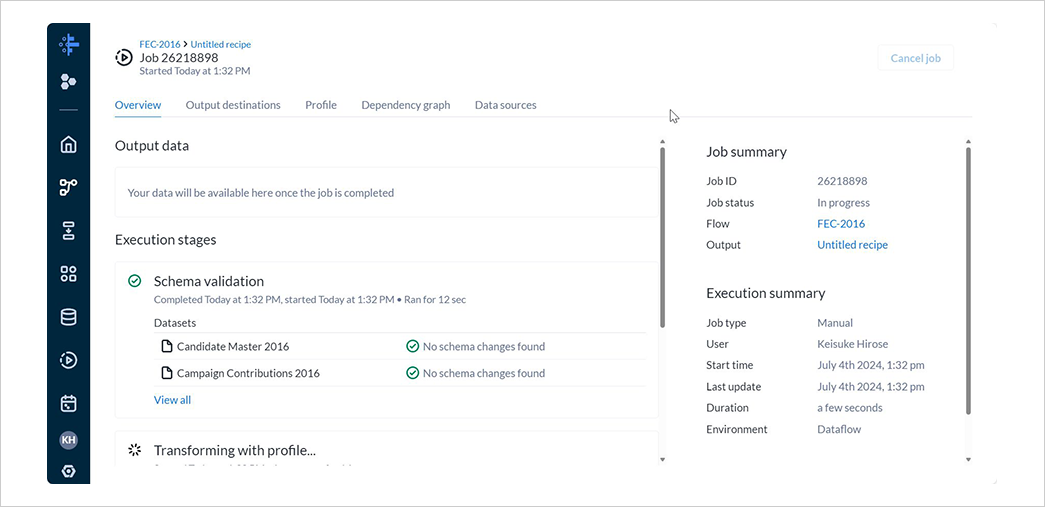
Output destinationsタブではアウトプット一覧を確認できます。
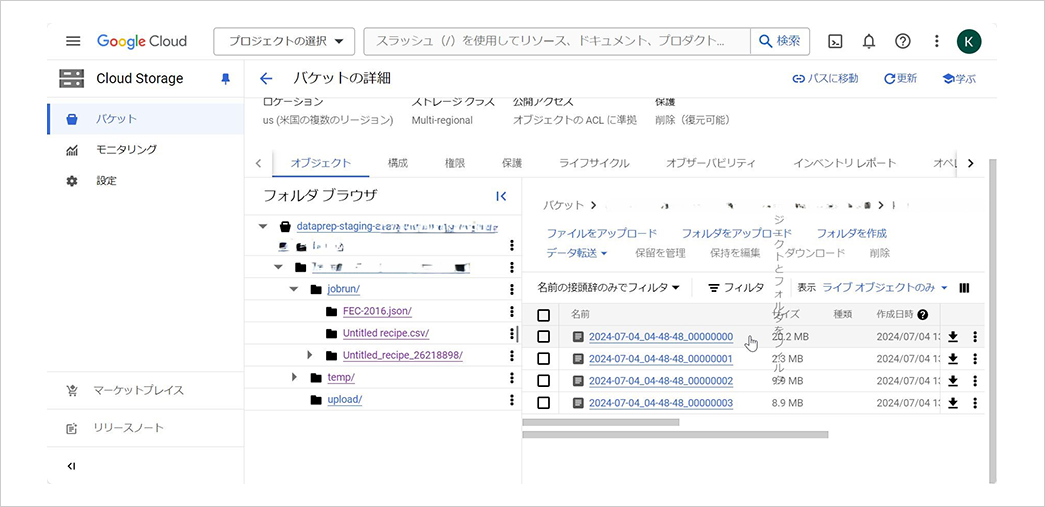
ジョブの完了後、各アウトプットのView on Cloud Storageを選択し、Cloud Storage に遷移します。
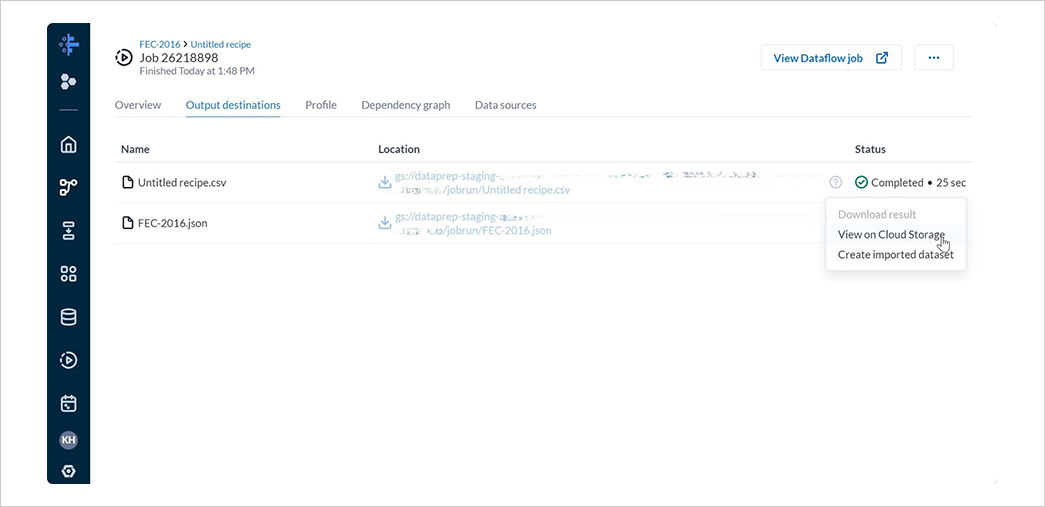
対象のバケットにファイルがアウトプットされていることが確認できました。
以上で、全手順が終了となります。
その他の機能
上記の手順では触れなかった機能について、概要を記載します。
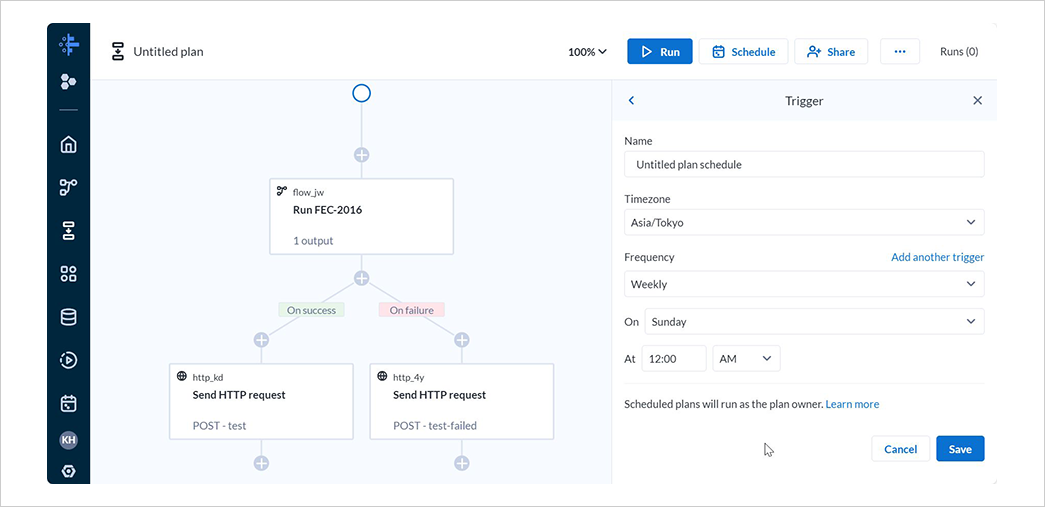
Plan
ジョブの実行や HTTP リクエストの実行など、個別のタスクを一連の処理として定義できます。
定義した Plan はスケジュール実行させることが可能です。
設定したスケジュールはSchedulesにて管理できます。
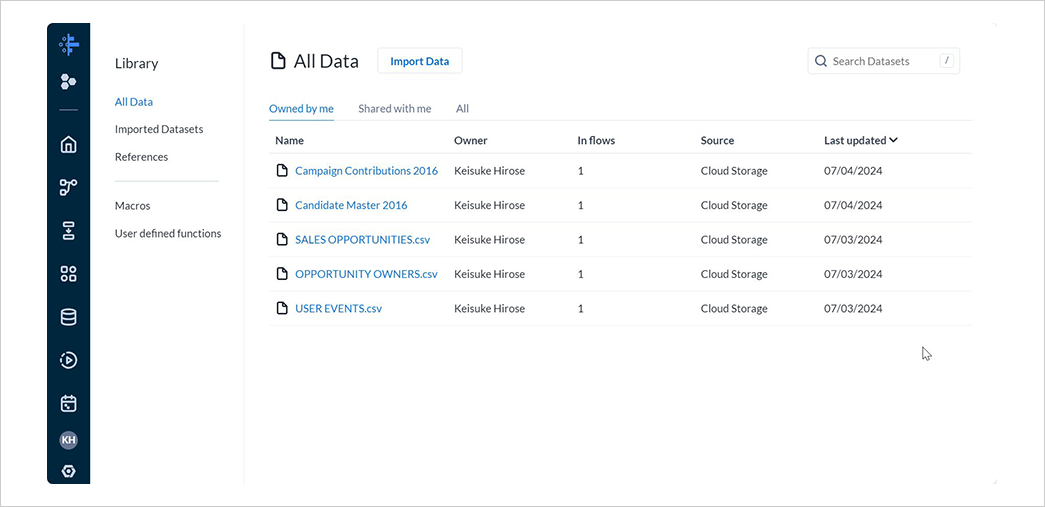
Library
インポート済みのデータセットなどを確認できます。
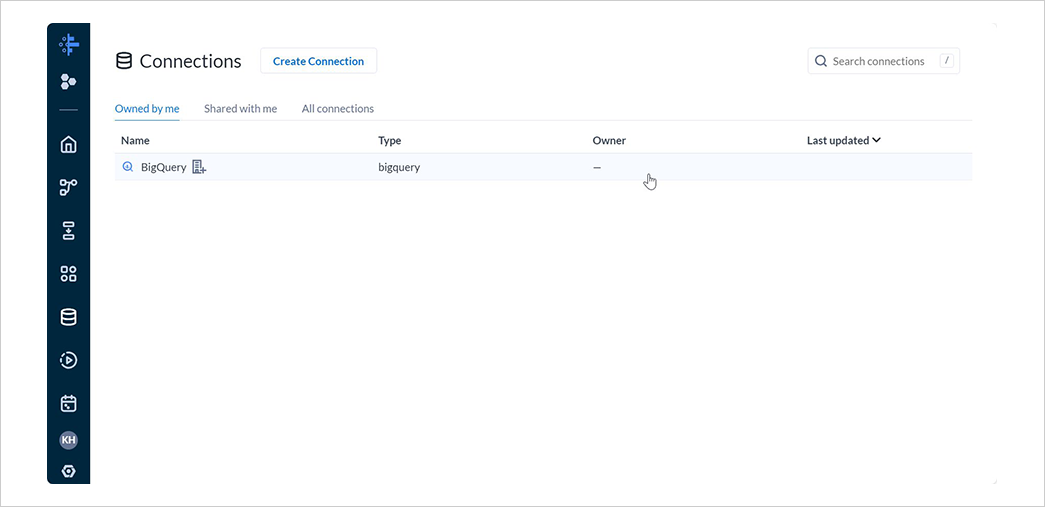
Connections
データソースとの接続を設定できます。
データソースには BigQuery の他、様々なアプリケーションやデータベース等を選択できます。
接続されたデータソースはデータセットのインポート元として利用できるほか、一部の接続ではアウトプット先としても指定できます。
料金
Dataprep には 30 日間の無料期間が存在します。
無料期間の終了後はStarter、Professional、Enterpriseのいずれかのプランで契約が必要です。
各プランの契約形態や料金は以下の通りです。
機能面でもいくつかの違いがありますがここでは割愛します。
| プラン名 | Starter | Professional | Enterprise |
|---|---|---|---|
| 契約形態 | 年間もしくは月間 | 年間のみ | 年間のみ |
| 利用料金(年間) | $960/user | $4,950/user + $10,000(basefee) | 要見積 |
| 利用料金(月間) | $100/user | - | - |
| 最小利用人数 | 1user~ | 3users~ | 7users~ |
次回予告
引き続き、Data周りのご紹介を予定しています。
ご期待ください!
著者紹介

伊藤忠テクノソリューションズ株式会社
廣瀬 啓丞
直近 1 年間ほど、パブリッククラウドに関する技術を担当。
最近は AI の活用を模索中。

