いまさら聞けない監視(CloudWatch)のお話し
投稿日: 2026/2/3
はじめに
こんにちは、園田です。
前回に引き続き、「いまさら聞けない」シリーズを開催したいと思います。
いまさら聞けないシリーズの第7弾は「監視(CloudWatch)」になります。
監視といえばAWSではCloudWatchですが(CloudWatchって監視サービスなんですかね?)、もうちょっと広義に監視のお話をしたいと思います。
もちろんメインはCloudWatchになります。
AWSで監視をしたいけど何をすればよいの?、という方に向けにいまさら聞けないシリーズを開催したいと思います。
いつもの通り、園田の独断と偏見が若干入っていますので、ご注意ください。
まぁ、AIが書いた記事面白くないですしね。偏見も入っていた方がいいんじゃないですかねー。
恒例のAWS資料を貼っておきます。
AWS サービス別資料
https://aws.amazon.com/jp/events/aws-event-resource/archive/?cards.sort-by=item.additionalFields.SortDate&cards.sort-order=desc&awsf.tech-category=*all※フィルターにてサービス名(今回だとCloudWatch、X-Ray)を入力してください。
AWSで監視したいんですけどー
いまさら聞けないシリーズは基本、「XXXXってなに?」から始まる形ですが、今回はテンプレートを変えて、別のお話からしたいと思います。
そもそもCloudWatchの前段、監視をしたい、というお話ですね。
AWSでシステム監視したい場合、基本CloudWatchで実施するという形になります。
とはいえ、基本CloudWatchはあくまでデータを入れる箱であり、監視をするという場合、こんな感じでアラーム設定を実施する必要があります。
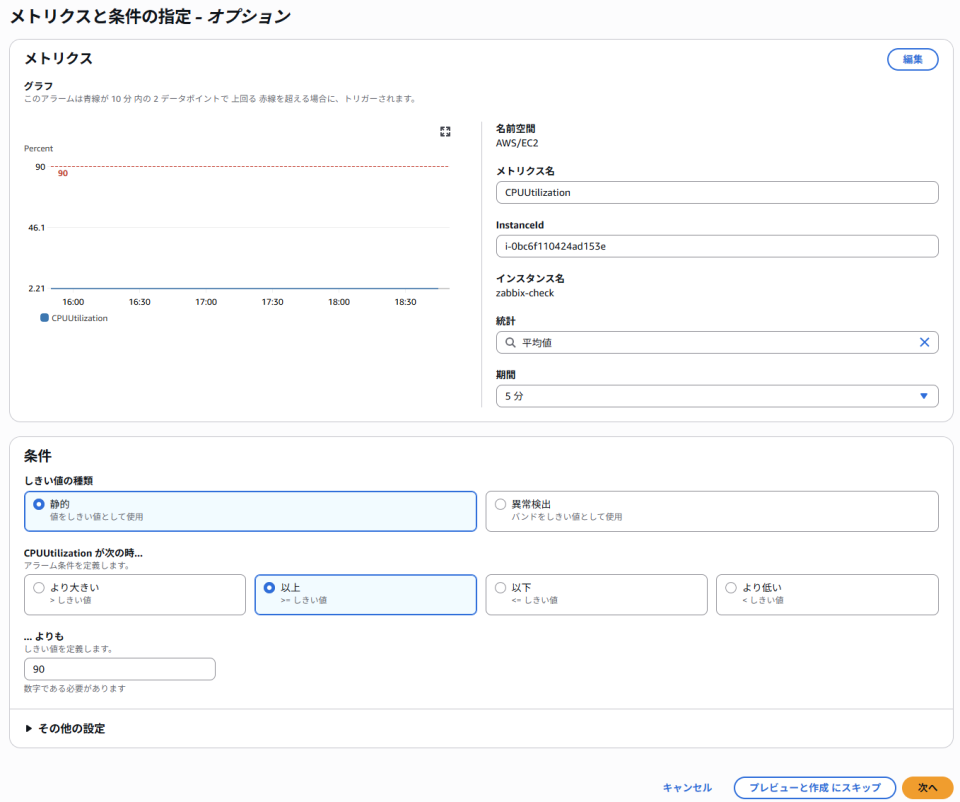
上記はCPUが90%になったらアラートを出すというアラーム設定ですね。
こんな感じで1つ1つアラーム設定を実施する必要があるのがCloudWatchの面倒な所です。
で、CloudWatchではデフォルトで以下のような項目の取得を実施しています。
EC2のメトリクス:
- サーバのステータス(StatusCheckFailed、StatusCheckFailed_Instance、StatusCheckFailed_System)
- CPU使用率(CPUUtilization)
- ネットワーク(NetworkIn、NetworkOut)
- ストレージ(EBSReadBytes、EBSWriteBytes)
みたいな感じです。
メモリやプロセスについてはCloudWatchのメトリクスには存在しません。
(あくまでEC2の話です。RDSやELBは別のメトリクスが用意されています。)
そのため、標準でCloudWatchのメトリクスに存在しないものはカスタムメトリクスとして、別途ツールを利用して、CloudWatchへデータを格納してあげる必要があります。
以前はAWS標準ツールでデータを格納することが難しく自前でシェル等を作成して実行、みたいなことをしていましたが、現状ではCloudWatchエージェントを正しく設定することでメモリやプロセスの状態をCloudWatchに格納することが可能です。
(便利になったものですね。そもそも何で最初からAWSの標準ツールでできなかったの、という話は置いておきましょう)
ここまで読んでわかることは、所謂エージェントが入らないAWSのSaaSサービス(EC2以外は全部そう)はAWSがデフォルトで用意しているCloudWatchのメトリクスをうまく活用して監視しないといけないという事です。
CloudWatchエージェントのインストール、設定
とりあえず、EC2を監視するのであれば、こんな感じでCloudWatchエージェントのインストール、並びに設定を実施しましょう。
●インストール(Amazon Linux 2023)
- yumリポジトリ確認
yum info amazon-cloudwatch-agent - CloudWatch エージェントのインストール
sudo yum install -y amazon-cloudwatch-agent - サービスの自動起動設定を確認
sudo systemctl is-enabled amazon-cloudwatch-agent - サービスの状態を確認
sudo systemctl status amazon-cloudwatch-agent
●インストール(Windows)
- 以下リンクからインストーラをダウンロード
https://amazoncloudwatch-agent.s3.amazonaws.com/windows/amd64/latest/amazon-cloudwatch-agent.msi - インストーラを実行
msiexec /i amazon-cloudwatch-agent.msi
●AWSプロファイル作成
今回はIAMユーザのプロファイルを作成します。(アクセスキー、シークレットキーを設定)
roleで実施する場合は不要になります。ちゃんと統制が取れているならroleの方が良いでしょう。なお、ユーザ、およびロールの権限はCloudWatchFull以上でお願いします
サーバにログインして、
aws configure --profile AmazonCloudWatchAgent
AWS Access Key ID [None]: <アクセスキー>
AWS Secret Access Key [None]: <シークレットアクセスキー>
Default region name [None]: <リージョン>
Default output format [None]:<Enter>
●CloudWatchエージェントの設定
- 設定ファイルの格納先へ移動
cd /opt/aws/amazon-cloudwatch-agent/etc - common-config.tomlの編集(AmazonCloudWatchAgentのプロファイルを利用するよう設定)
shared_credential_profile = "AmazonCloudWatchAgent"
shared_credential_file = "/root/.aws/credentials"
※プロキシを利用している場合、本ファイルにプロキシ設定を実施してください。 - amazon-cloudwatch-agent.jsonの編集
こんな感じで記載ください。
この設定ではメモリ、ディスク、プロセスの状態をCloudWatchに送信する設定としています。
※プロセス追加したい場合、同様の記載方法でプロセスを追加してください。
{
"agent": {
"metrics_collection_interval": 300,
"run_as_user": "root"
},
"metrics": {
"namespace": "CWAgent",
"aggregation_dimensions": [
[
"InstanceId"
]
],
"append_dimensions": {
"InstanceId": "${aws:InstanceId}"
},
"metrics_collected": {
"mem": {
"measurement": [
"mem_used_percent"
]
},
"disk": {
"measurement": [
"used_percent"
],
"resources": [
"*"
],
"ignore_file_system_types": [
"tmpfs",
"devtmpfs",
"vfat"
]
},
"procstat": [
{
"exe": "sshd",
"measurement": [
"pid_count"
]
},
{
"exe": "chronyd",
"measurement": [
"pid_count"
]
}
]
}
}
}
この設定だと、取りあえず
- メモリ
- ディスク
- 指定プロセス
のデータがCloudWatchに格納される形になります。
一般的な監視としてはこれで十分でしょう。
なお、Windowsのサービス監視をしたい場合、残念ながらCloudWatchエージェントではデータをCloudWatchに送ることは出来ません。
自分でスクリプトを作成する必要があります。
(生成AIさん(copilotとか)にスクリプト作って、とお願いすると作ってくれると思います。)
AWSサービスの監視
EC2以外でAWSのサービスを監視したい場合、AWSが持っているCloudWatchのメトリクスを利用する必要があります。
で、サービスの死活監視をしたい。みたいな要望が時々ありますが、そもそもAWSにおいてサービスの死活監視なんてものは出来ません。
例えばELBとかを見てみましょうか。
ELB(ALB)のメトリクスは以下の通りとなっています。
なお、文中に出てくる「ターゲット」とは負荷分散対象をさしています。
- MitigatedHostCount
→ ロードバランサーによって処理され、正常に処理されたターゲット数 - AnomalousHostCount
→ ターゲットホストからの異常な応答があるホスト数(5XXエラーなど) - RequestCount
→ ターゲット(EC2など)に転送した回数 - UnHealthyHostCount
→ 正しく認識できなかったターゲット(EC2など)の数 - HealthyHostCount
→ 正しく認識できたターゲット(EC2など)の数 - RequestCountPerTarget
→ ターゲットグループ内のターゲットあたりの平均リクエスト数 - HealthyStateDNS
→ DNSにより正常状態と判断されたゾーンの数 - HealthyStateRouting
→ ルーティングにより正常状態と判断されたゾーンの数 - UnhealthyStateDNS
→ DNS での正常状態に関する要件を満たしていないため、DNS により障害があるとマークされたゾーンの数 - UnhealthyStateRouting
→ ルーティングの正常状態に関する要件を満たしていないゾーンの数 - UnhealthyRoutingRequestCount
→ ルーティングフェイルオーバーアクション (フェールオープン) を使用してルーティングされたリクエストの数 - TargetResponseTime
→ ターゲットが応答ヘッダーの送信を開始するまでの経過時間 (秒) - HTTPCode_Target_2XX_Count
- HTTPCode_Target_3XX_Count
- HTTPCode_Target_4XX_Count
- HTTPCode_Target_5XX_Count
→ ターゲットによって生成された HTTP 応答コードの数
見ていただいて分かる通り、「どのくらいの処理が出来ているか」、「異常が発生しているターゲットが無いか」などの確認は可能ですが、ALB自体の障害を表すメトリクスは存在しません。
こちらはALBだけでなく、全てのサービス(EC2除く)において、そのような障害のメトリクスは存在しません。
これはそもそもクラウド自体がシングルポイントオブフェイリア(Single Point of Failure)を回避する設計に出来ること、ならびにクラウド自体は単一障害時も動作するという思想に基づいています。
そのため、自身が提供しているサービスにおいて、何をもって正常に処理できているとするかをきちんと定義してあげる必要があります。
サービスの監視はAPMでしようよ。という話
15年ぐらい前(だいぶ前だな)までは監視といえば、ちょっと良く分かりませんが死活監視を指しました。
まぁ、URL監視とかはあったので、サービスのステータスぐらいはチェックできましたね。
クラウドサービスが台頭するようになり、所謂APM(Application Performance Monitoring)が一般的になったと認識しています。結局「生きてる」、「死んでる」だけだとサービスが利用者にとって、適切に提供できているかは判断できない。
という事ですね。
APM(Application Performance Monitoring)について有名なのはDatadog、New Relic、Dynatraceですね。
SaaSサービスの提供時期もDatadog→New Relic→Dynatraceの順番になっています。
Datadogが2010年です。
でAWSの場合は、AWS X-Rayになります。
X-Rayが2017年リリースなので、APMが一般的になったのは2015年ぐらいですかね。
それなりに歴史があります。
X-Rayもそうですが、基本APMのサービスはSaaS側がエージェントを用意しています。
エージェントを入れることで、こんな感じでサービスマップを作ってくれます。
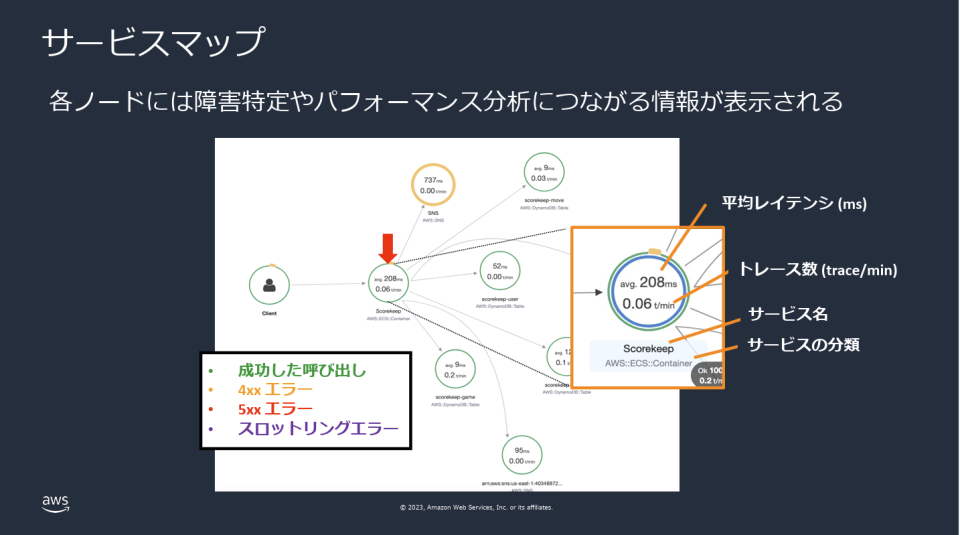
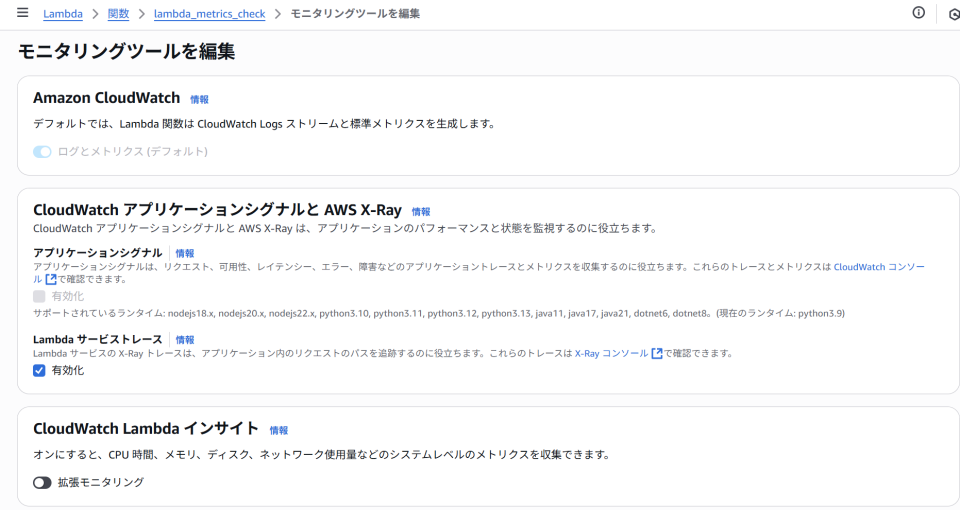
なお、エージェントと言いましたが、Lambdaの場合であれば、X-Rayの有効化は以下の画面で「Lambda サービストレース」の項目にチェックを実施するだけで利用可能です。
だいぶ敷居が低くなりましたね。(API GatewayもチェックでX-Rayが有効化できます)
APM(Application Performance Monitoring)の良いところは利用者から見てボトルネックとなる個所がきちんと可視化され、サービス改善に取り組むことが出来るという点ですね。
開発段階からAPM(Application Performance Monitoring)でパフォーマンスチェックを実施しているという所も珍しくないですね。
もちろん障害という点においても正しく動作していない点が可視化されますので、どこが障害ポイントかという点も判断がつきます。
なお、クラウドでは完全に使えないけどスローダウンするという事もあります。APM(Application Performance Monitoring)を活用しているとそういったケースも検知できます。そもそもそういうケースを検知するために作られているとはいえ、開発側からしたらありがたいことです。
そもそも障害ってなに?
どーでもいいですが、「障害」って何なんでしょうね。
AWS Summit Japan(2025年)では「ソフト障害」、「グレー障害」みたいな言葉が出てきました。(多分、日本だけで使っている言葉だと思います。)
どうも「障害」というのは「使えない」事らしく(園田には良く分からないですけど)、スローダウンとかレスポンスが悪いなどは、(多分、無理やり)「ソフト障害」、「グレー障害」という言葉にして歩み寄ってくれているようです。
障害の概念が変わるのであれば、監視の概念も変わっていって欲しいものです。
「監視」ではなく、自分たちが提供しているサービスを「モニタリング」するという概念が世の中の常識になるといいですね。
願わくば、10年以内に常識が変わって欲しいな。と思います。
という訳で、皆さんもクラウド上でのサービスをモニタリングしていきましょう。
終わりに
という訳で、「いまさら聞けない監視(CloudWatch)の話」でした。
あんまり、監視の話をしていないような気もしますが、まぁ良しとしましょう。
CUVIC on AWSでは監視サービスとしてCloudWatchを利用したEC2運用パック、並びにZabbixを利用してオープンソース監視を提供しています。
また、Datadogを使った監視サービスも実施しております。
ご興味がある方は是非お問い合わせください。
とはいえ、結局モニタリングするためには、お客様のアプリケーションに近い位置にいる必要があります。
そのため、この辺はどうしても個別になってしまいサービス化が難しいところです。とはいえ、お客様に寄り添うという意味ではこちらの方が良いのかもしれません。
なお、2025年時点で園田の部署では、Datadogの技術主管も兼務しておりますのでDatadogに興味があるよーという方はお声がけいただくとうれしいです。
ではまた、別の記事でお会いしましょう。

