Amazon SageMaker Canvas + AWS Glue DataBrewによるノーコード開発(前編)
投稿日: 2023/3/16
はじめに
はじめまして、伊藤忠テクノソリューションズ 山近です。みなさんは、データが手元にあって機械学習でAIモデルを開発したい場合、何が必要だと思いますか。一般的には、以下の3つのプロセスを経ることになります。
- ① プラットフォームの用意
- ② データ加工プログラムによる準備
- ③ 機械学習アルゴリズムの適用
①については、答えはもちろんAWSです。AWSのアカウントを用意できれば、データレイク/データ加工/機械学習プラットフォームは、インストール作業等することなくすぐに使うことができます。
②③はどうでしょうか。どちらもpythonに代表されるようなプログラムで記述する必要があり、しんどいな、と思う方は多いと思います。
そこで、今回は、AWSのサービスである Amazon SageMaker CanvasとAWS Glue DataBrewを利用して、ノーコードでデータ加工と機械学習のAIモデル開発を実施してみましょう。
1.全体概要
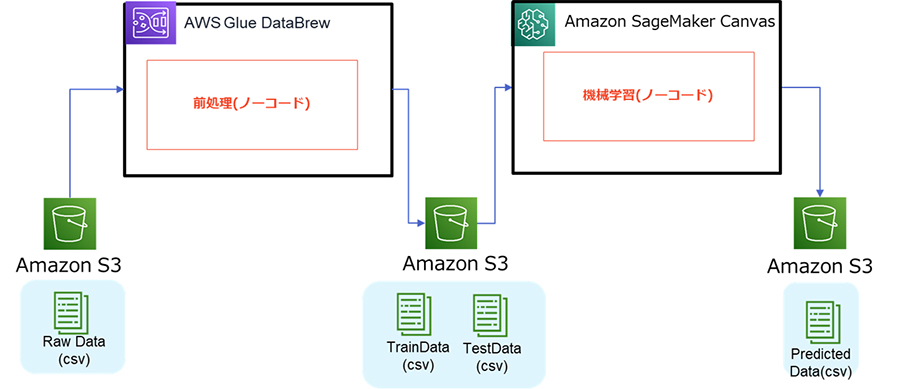
今回のシナリオの全体概要は以下のようになっています。RawDataをAWS Glue DataBrewで前処理し、そのデータをSageMaker Canvasで機械学習を行って予測結果を出力します。そして、これらをすべてノーコードで行ってみます。
2.Amazon SageMaker Canvasセットアップ
まず、SageMaker Canvasをセットアップします。こちらの記事に従って、セットアップしてみてください。
なお、SageMakerで使用されるデフォルトのS3バケットは
sagemaker-<作成したリージョン>-<アカウントID>になります。今回はこちらのバケット使用する前提で進めます。
※Amazon SageMaker Canvasセットアップの過程で作成されるS3バケットとサンプルデータを使用するため、手順の最初に持ってきています。別途用意したS3バケットやデータを使用する場合は、この手順を後に回してもでも構いません。
3.AWS Glue DataBrewについて
AWS Glue DataBrewはGUIベースのデータ準備ツールです。エンジニアに限らず、利用部門のユーザにも広く使われています。プログラムを組むことなく分析を行ったり、機械学習用のデータを用意することが可能です。
https://aws.amazon.com/jp/glue/features/databrew/
4.AWS Glue DataBrewセットアップ
AWS Glue DataBrewをセットアップします。以下のマニュアルに従って実施してみてください。
https://docs.aws.amazon.com/ja_jp/databrew/latest/dg/setting-up.html
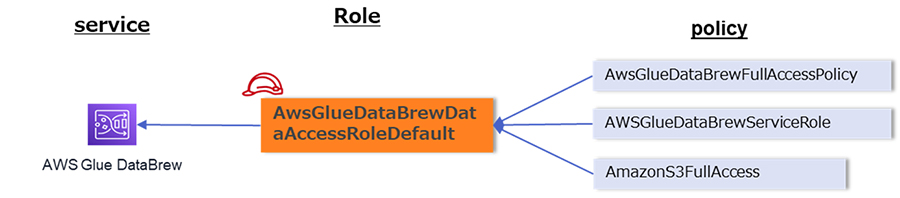
なお、今回の検証用に作成したロールとアタッチしたポリシーの関係を記載しておきます。
※権限が強すぎる等でセキュリティ的に問題があると想定される場合には、適切なものに各自で変更してください。
5.AWS Glue DataBrewでの実施概要
いよいよ、AWS Glue DataBrewで前処理していきます。DataBrewでの実施概要は次のようになります。
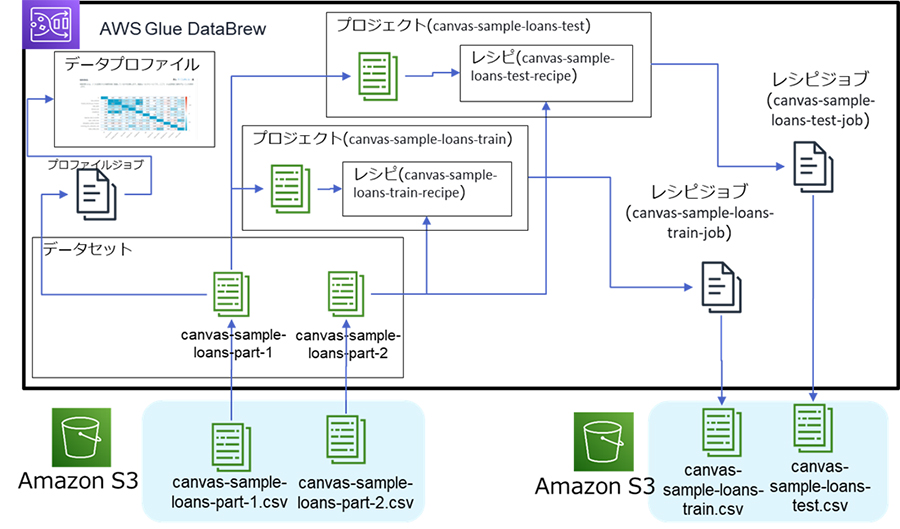
SageMaker Canvasに投入する学習用データ(canvas-sample-loans-train.csv)と、テスト用データ(canvas-sample-loans-test.csv)を作成することがゴールとなります。
6.AWS Glue DataBrewでの実施詳細
① データセットの読み込み
最初にDataBrewにデータセットを接続します。今回使用するのは、以下の2つのCSVファイルで、それぞれ別で2つのデータセットを作成してください。このデータセットは、2.Amazon SageMaker Canvasセットアップの過程で作成されています。
データセット名:
canvas-sample-loans-part-1
canvas-sample-loans-part-2バケット名:
sagemaker-<作成したリージョン>-<アカウントID>ファイル名
バケット名/canvas/ sample_dataset/ canvas-sample-loans-part-1.csv
バケット名/canvas/ sample_dataset/ canvas-sample-loans-part-2.csv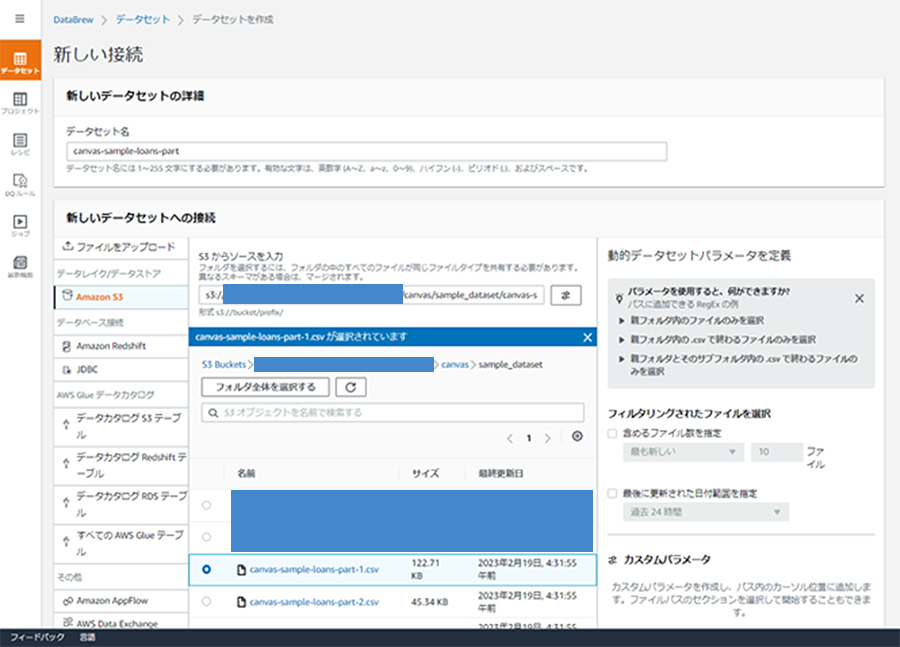
また、
ファイルタイプ:
csv
CSV区切り記号:
カンマ(,)
列ヘッダ値:
最初の行をヘッダとして扱う
を選択し、[データセットの作成]を押下します。
② プロファイルの作成
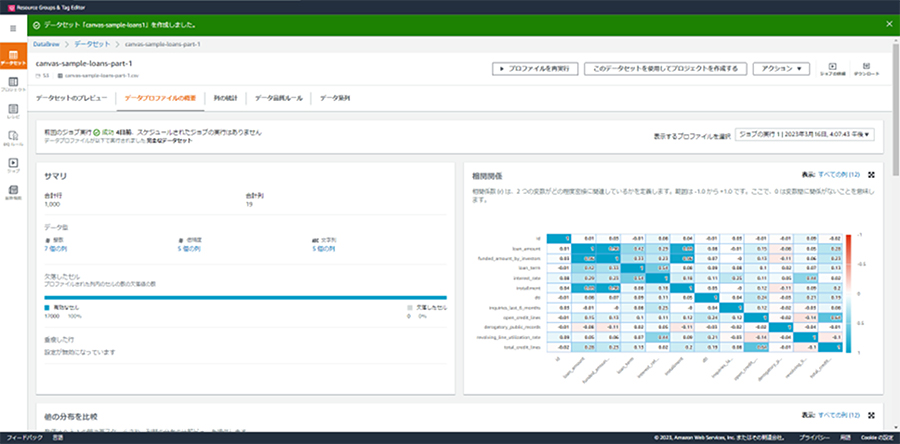
今回のシナリオには直接関係ないので簡単に触れる程度にしますが、作成したデータセットに対してデータプロファイルを作成できます。データプロファイルは、接続したデータセットに対しての詳細なデータ情報で、列の欠損情報や列同士の相関係数などが分かるため、未知のデータセットに対してどのような前処理を行っていけば良いかといった方針を立てるために用いることができます。
作成するには、データセットから[データプロファイルを実行]を押下します。

その後、プロファイルジョブの各項目を入力・選択する画面に遷移するので、適宜、入力・選択し、プログラムジョブを実行します。少し待つと、以下のようなデータプロファイルが作成されます。
③ プロジェクトの作成
最初に学習用データ生成のためのプロジェクトとレシピを新規作成します。先ほど作成したデータセットのうち、片方(canvas-sample-loans-part-1)を紐づけます。なお、許可ロール名は、3.AWS Glue DataBrewセットアップで作成したロールになります。
プロジェクト名:
canvas-sample-loans-trainレシピ名:
canvas-sample-loans-train-recipe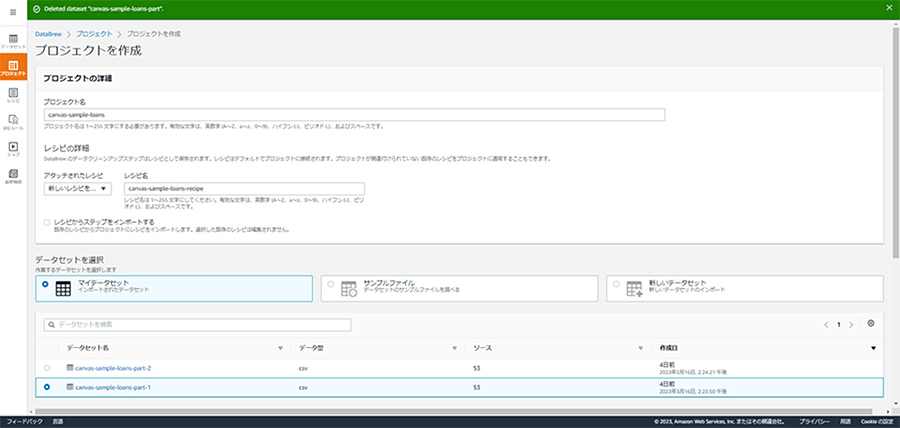
④ レシピの作成
レシピを作成します。レシピとは、データ加工の工程を意味しています。レシピの各工程を説明する前に、今回のデータ加工で実施したいことは以下の通りです。
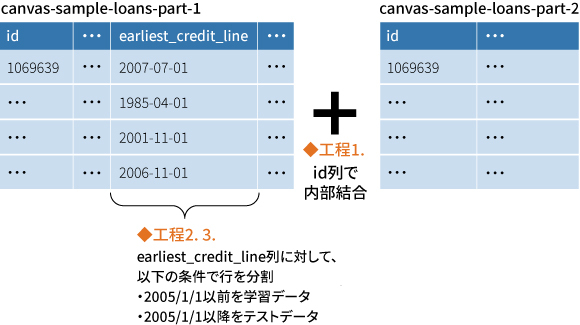
- 今回の2つのデータセットはid列で1対1に内部結合できる。
- earliest_credit_line列において、2005/1/1以前のデータを学習用データ、それ以降のデータをテスト用データとして、データ全体を行で分割する。
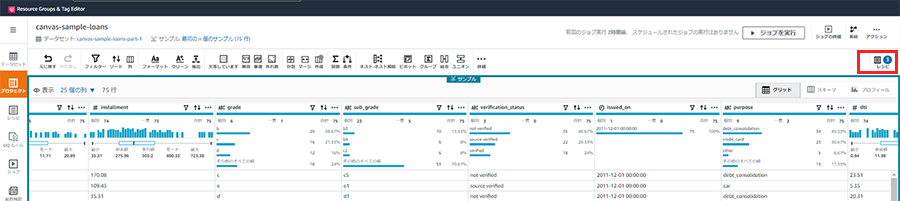
実際にレシピを作成してみましょう。まず、先ほど新規作成したレシピを編集してきます。プロジェクトの画面から、[レシピ]を押下します。
1. 結合
id列で内部結合します。レシピのステップの追加から、[結合]を選択します。
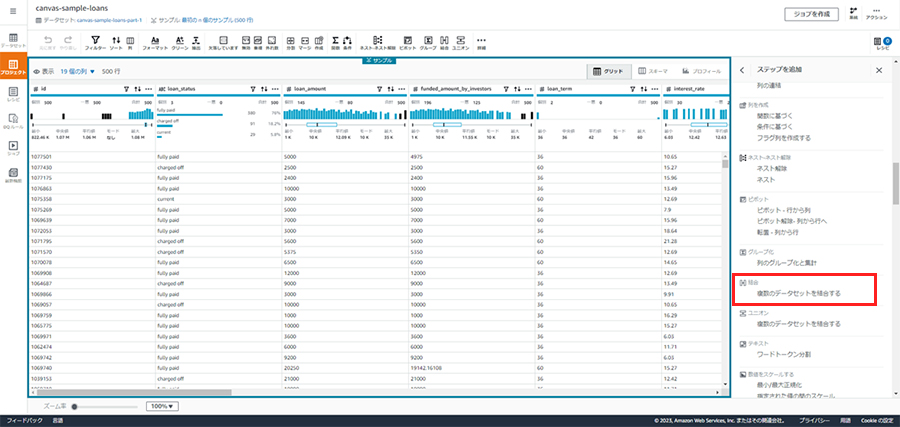
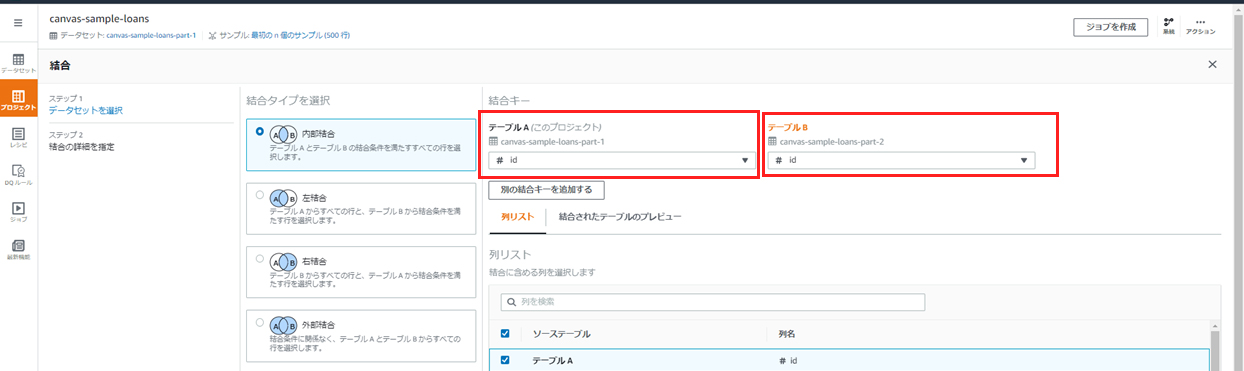
結合したいcanvas-sample-loans-part-2を選択します。

内部結合を選択し、結合する列として両方のテーブルでid列を選択します。
2. 条件に基づく列を作成
日付列による行の分割ですが、いくつか方法はあります。ここでは、新規にフラグ列を追加し、その条件で行を分割する方法を実施しています。
earliest_credit_line列の値に基づいた列を新規追加します。レシピのステップの追加から、[列を作成]-[条件に基づく]を選択します。
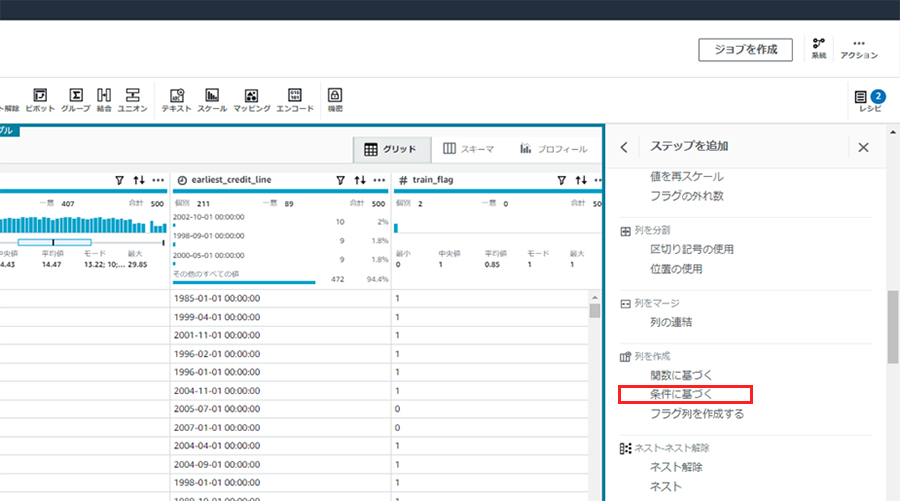
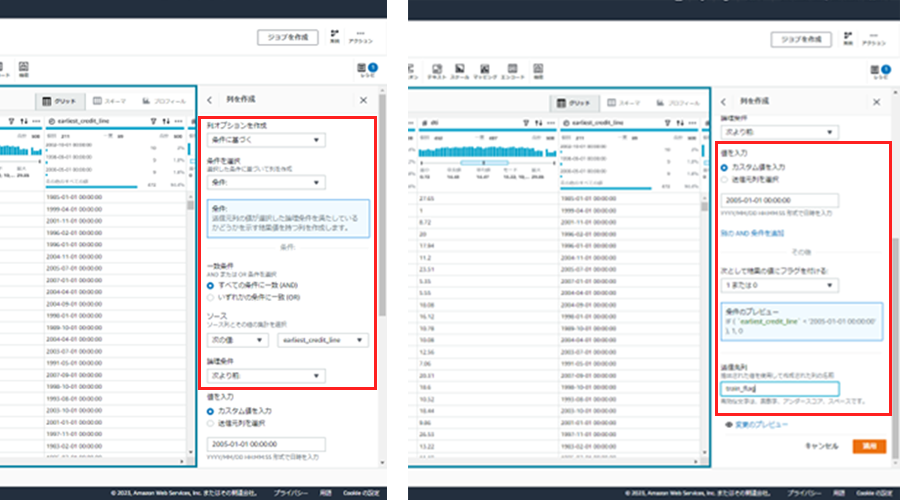
条件として、以下の内容でtrain_flag列を新規作成します。
- A)earliest_credit_lineが2005-01-01 00:00:00より前
- B)A)に一致した場合は1,それ以外は0を選定
- C)B)の値を新規列とする
3. 条件に基づく行のフィルター
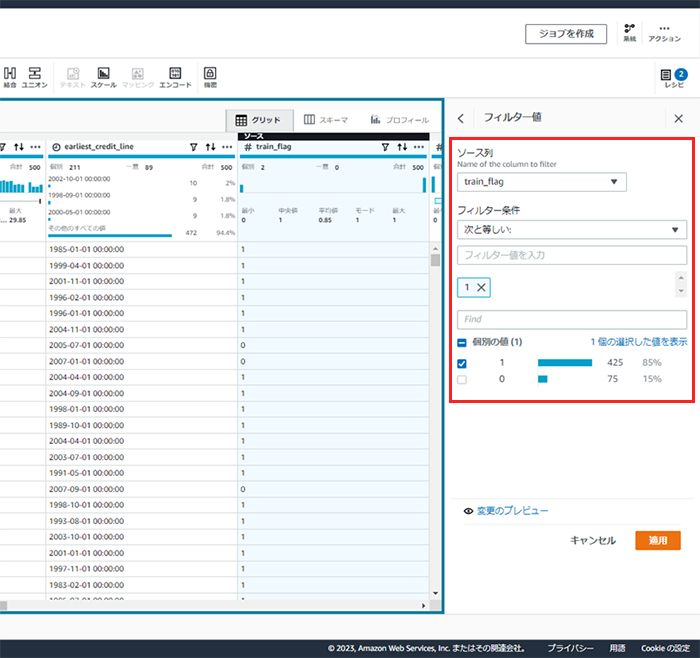
前項の作業によって、train_flag列が1の行が学習用データになるため、train_flag=1の行を抽出します。レシピのステップの追加から、[フィルター]-[条件別]を選択します。
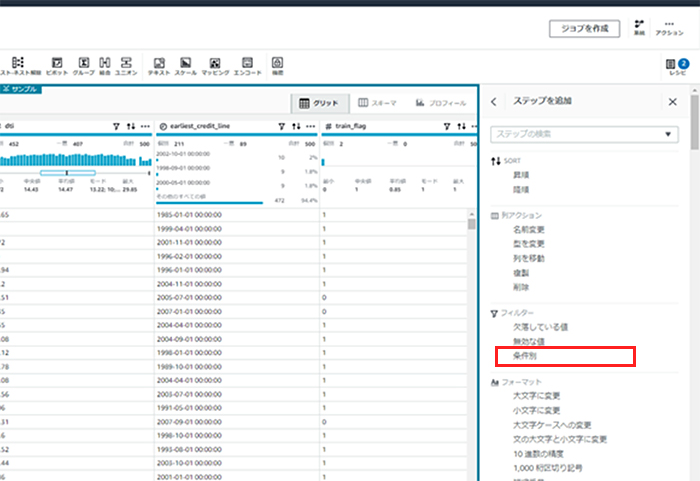
train_flagが1に等しい行を選択します。
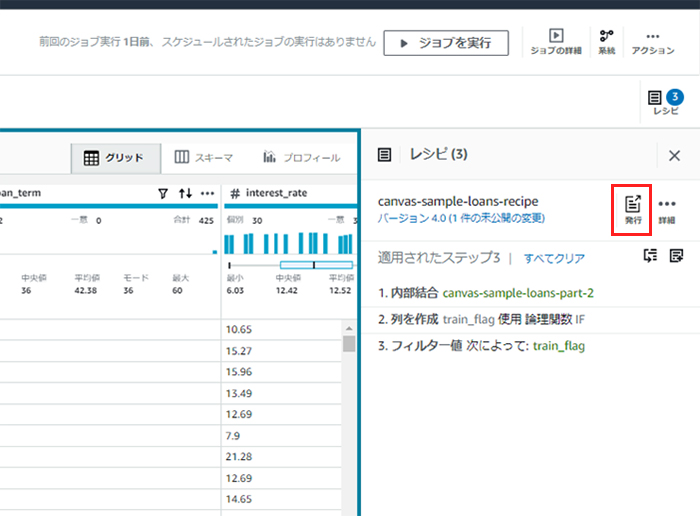
4. レシピの発行
レシピが完成しました。レシピを発行することで正式なものとなりますので、発行を押下します。
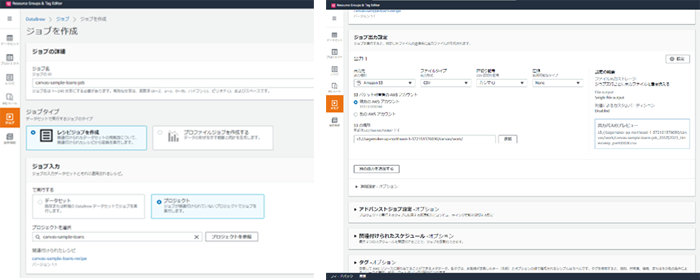
5. レシピジョブの作成と実行
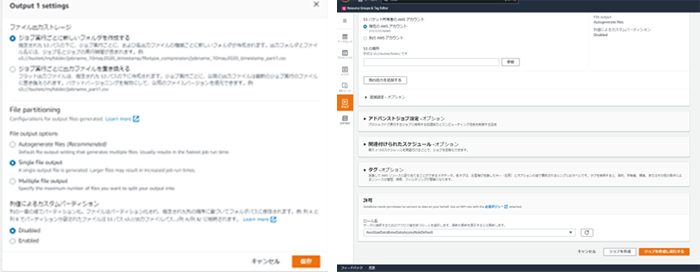
レシピジョブを作成します。主な設定情報を以下に記載します。
レシピジョブ名:
canvas-sample-loans-train-jobプロジェクト:
canvas-sample-loans-train出力先:
Amazon s3
ファイルタイプ:
csv
CSV区切り記号:
カンマ(,)
S3の場所:
バケット名/canvas/ work
⑥ 加工後データの出力確認
レシピジョブジョブを実行すると、以下のように設定したS3出力先にファイルが出力されます。
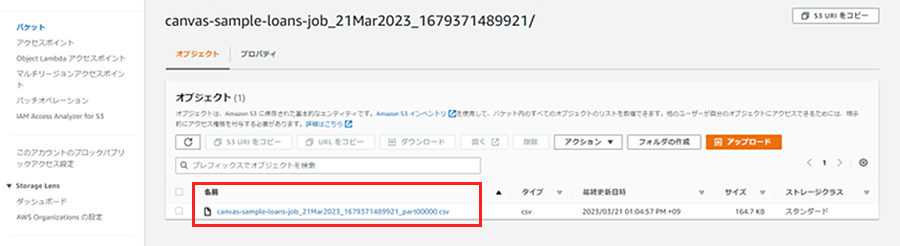
生成されたファイルはCanvasで使用する学習データとなりますので、以下のファイル名に変更しておいてください。
ファイル名:
canvas-sample-loans-train.csv
⑦ プロジェクトの複製とレシピ修正
いまの手順で学習用データが生成できました。今度は、テスト用のデータ(canvas-sample-loans-test.csv)を生成します。
テスト用データ生成のためのプロジェクトとレシピ名を、先ほどまで作成したプロジェクトとレシピから複製します。
プロジェクト名:
canvas-sample-loans-testレシピ名:
canvas-sample-loans-train-test
これで、名前の異なる全く同じプロジェクトとレシピができました。では、テスト用データデータを生成するにはどこを修正すればよいでしょうか。
答えは、レシピにおける第3工程です。train_flagが0に等しい行を選択すれば、テスト用のデータが出力されることになります。
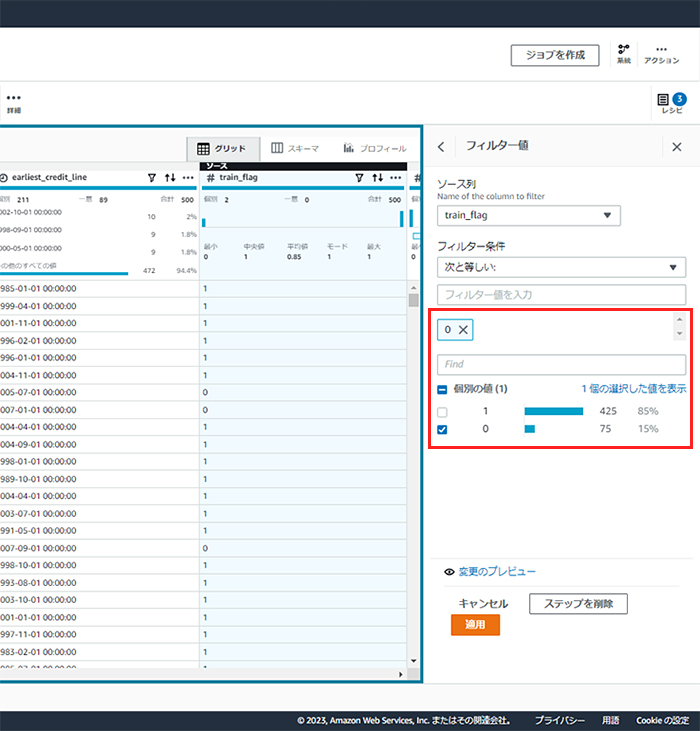
⑧ テスト用データの生成
あとは、⑤レシピジョブの作成と実行 を参考にしてレシピジョブを作成し、テスト用データを生成してください。
レシピジョブ名:
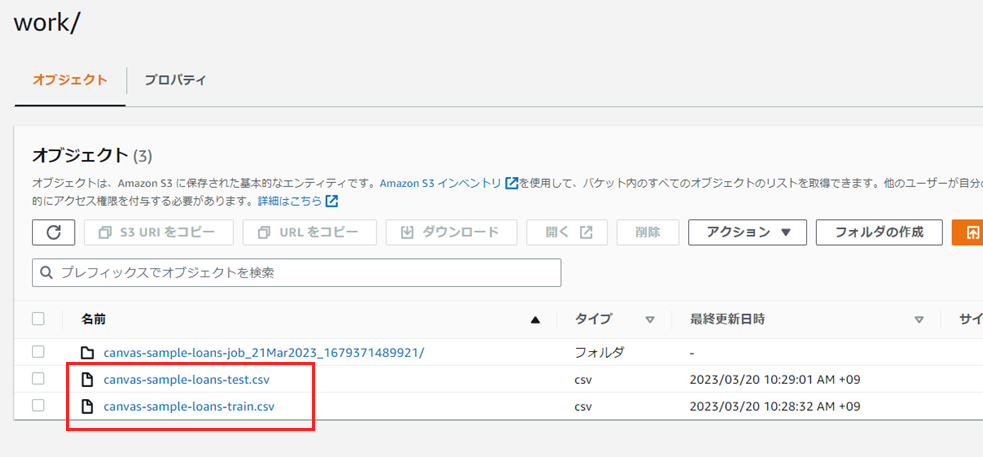
canvas-sample-loans-test-job生成されたファイルは、Canvasで使用するテスト用データとなりますので、以下のファイル名に変更しておいてください。
ファイル名:
canvas-sample-loans-test.csvこれで、SageMaker Canvasに投入するデータが完成しました。
7.まとめ
いかがでしたでしょうか。データ前処理にプログラミングは一切しませんでした。AWS Glue DataBrewはもっと複雑なデータ加工も可能です。是非、いろいろ試してみてください。
後編では、作成したデータをAmazon SageMaker Canvasに投入して、ノーコードで機械学習を実施してみます。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。

クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理

