Amazon SageMaker Canvas + AWS Glue DataBrewによるノーコード開発(後編)
投稿日: 2023/3/22
はじめに
こんにちは、伊藤忠テクノソリューションズ 山近です。前編に引き続いて、後編になります。
Amazon SageMaker Canvas + AWS Glue DataBrewによるノーコード開発(前編)
1.前編のおさらい
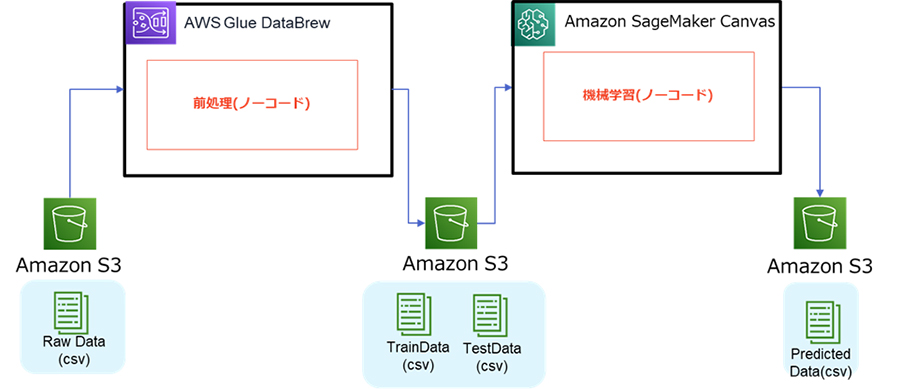
今回のシナリオの全体概要は以下のようになっています。前編ではRawDataをAWS Glue DataBrewで前処理してTrainDataとTestDataで分割してS3バケットまで出力しました。
後編ではSageMaker Canvasで機械学習を行って予測結果を出力します。引き続き、すべてノーコードで行ってみます。
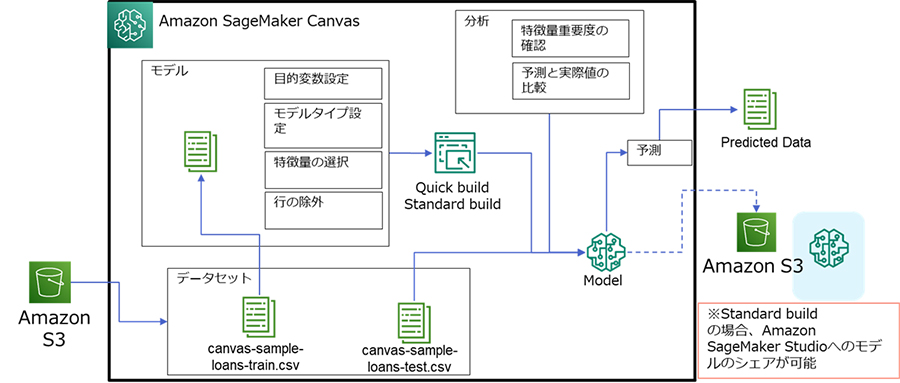
2.Amazon SageMaker Canvasでの実施概要
Amazon SageMaker Cancvasでの実施概要は次のようになります。
SageMaker Canvasについてはこちらの記事も参考にしてみてください。
なお、上記記事で既に説明済の内容については、一部、説明を省略させて頂く箇所もあります。
3.Amazon SageMaker Canvasでの実施詳細
① データセットのインポート
SageMaker Canvasで利用するためのデータセットをインポートします。

ファイル名:
canvas-sample-loans-train.csv
canvas-sample-loans-test.csv② モデルの作成
今回の学習用データはcanvas-sample-loans-train.csvですので、こちらのみを選んで[Create a model]を押下します。

③ 目的変数設定/モデルタイプ設定/特徴量除外
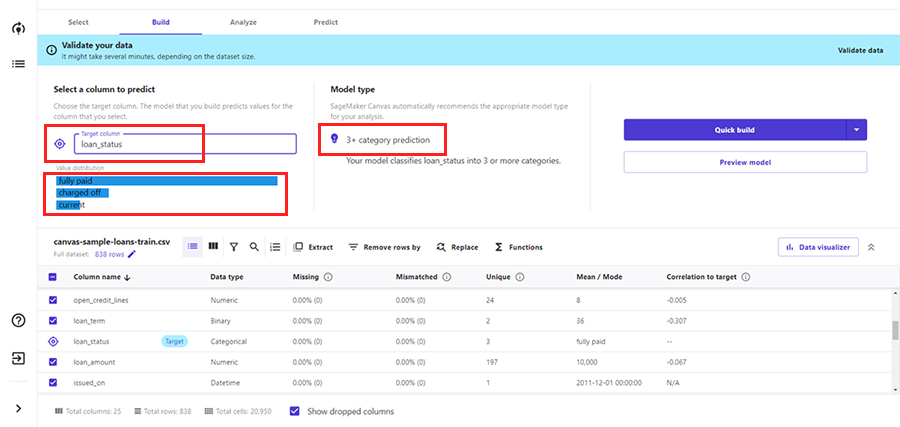
1. 目的変数設定
今回は、loan_statusを目的変数に設定します。loan_statusは、カテゴリタイプの列で、少なくとも3種類以上の要素があることが分かります。
2. モデルタイプ設定
3種類以上のカテゴリがある目的変数に対する機械学習なので、回帰ではなく多値分類になります。そのため、[3+ category prediction]が自動的に選択されています。
3. 特徴量除外
機械学習に使用しない特徴量(説明変数)を除外します。実施には表示をGrid Viewモードに変えてデータの中身を確認しつつ検討を行うことも有用です。
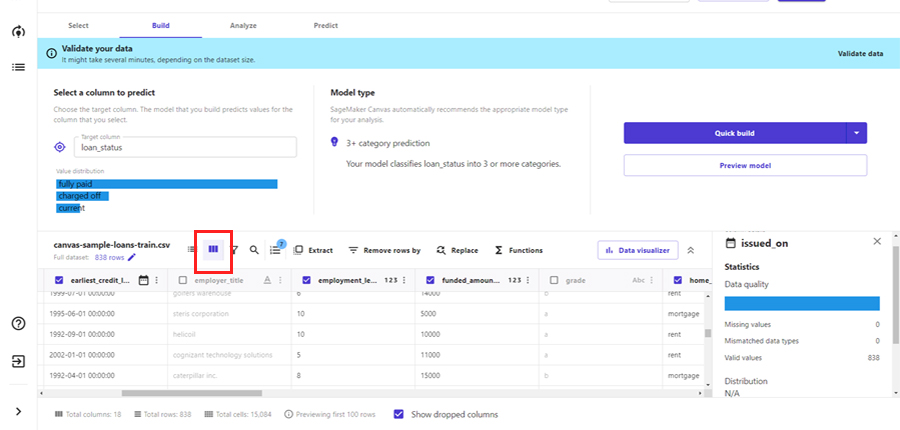
今回は、以下の特徴量を除外することにします。チェックを外すとともに、Model recipeに列が除外されている旨が表示されていることを確認します。
- id,TABLE_B_id
- employer_title
- grade, sub_grade
- train_flag
- issued_on
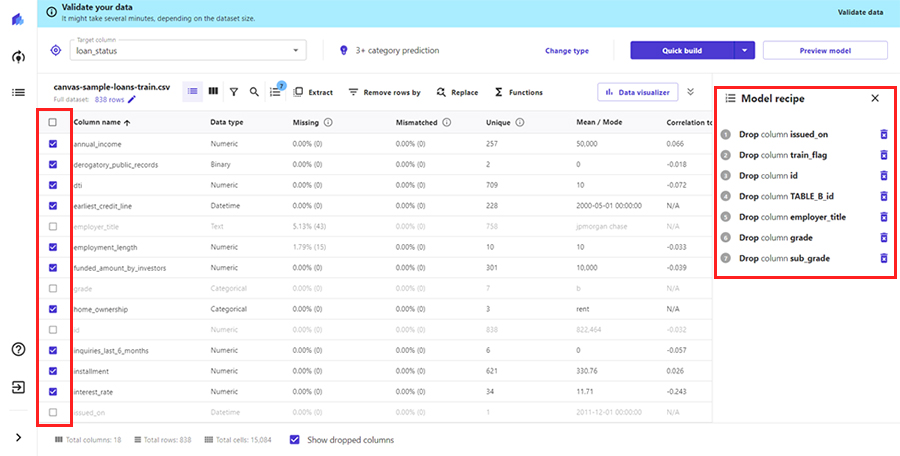
それ以外にも、特定行の除外なども実施可能です。その場合も、表示をGrid Viewモードに変えてデータの中身を確認しつつ検討を行うことになります。
④ Quick Build(Standard Build)の実行
今回はQuick buildを実行します。なお、Quick buildを実行するには、入力データセットの段階でデータの行数を50,000 行以下にする必要がありますので、注意してください。 (50,000 行を超えるデータセットで始めてしまうと、Standard buildしか押下できません。)
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/canvas-build-model.html
⑤ 分析
Quick buildが完了すると、分析画面が表示されます。なお、表示された数値が異なる場合がありますが、サンプリング等の偶然性によるためです。
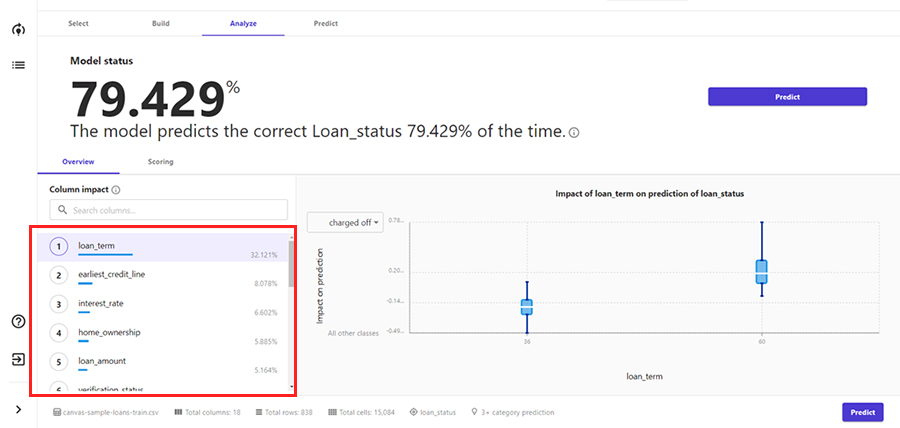
Overview
ここでは、特徴量インパクトが表示されます。目的変数に設定したloan_statusの予測に対しての各特徴量の重要度が降順で表示されます。今回の分析では、loan_termの影響が最も大きくなります。
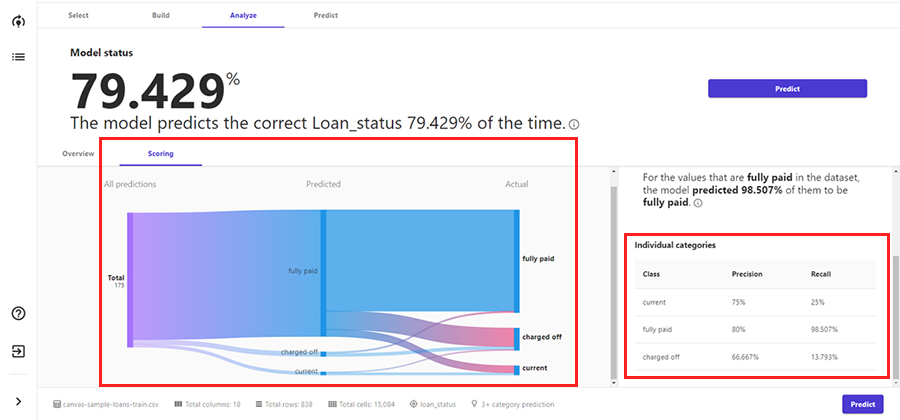
Scoring
予測の内訳(今回は3種)と実際との対比です。例えば、
- [fully paid]と予測したデータに対して、実際の結果はどうであったのか
- 実際の結果が[fully paid]であるデータに対して、予測がどうであったのか
などを定量的に判断することができます。また、分類の指標であるPrecision(適合率:予測したもののうち、それが実際に正しかった割合)やRecall(再現率:実際に予測が正しかったもののうち、それを予測できていた割合)も表示されます。
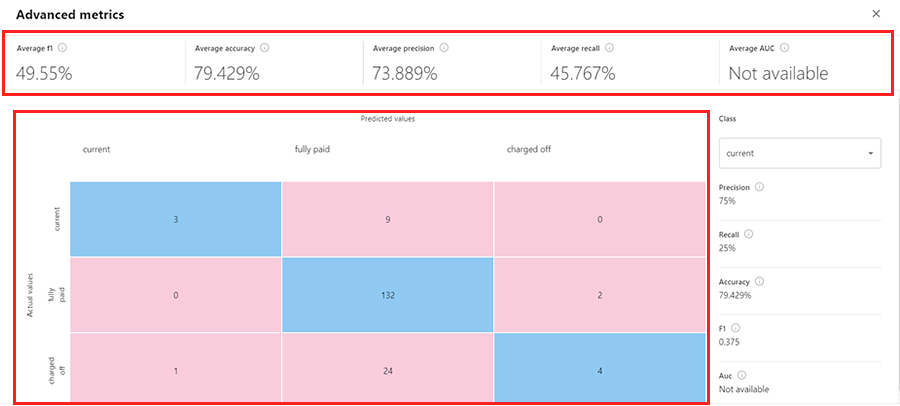
[Advanced metrics]を押下すると、高度な指標が表示されます。
- 上段には、分類における指標で利用されるf1-Scoreと呼ばれるPrecisionとRecallの調和平均なども表示されます。
- 下段には、予測内容と実際の組み合わせである混同行列(Confusion Matrix)が表示されます。
なお、回帰や時系列分析の時には、また、それの分析の種類に沿った表示に変わります。
⑥ 予測の実施
今までの分析は、学習データで作成したモデルに対して学習データで分析していました。最後に、そのモデルに対してテスト用のデータcanvas-sample-loans-test.csvで予測します。
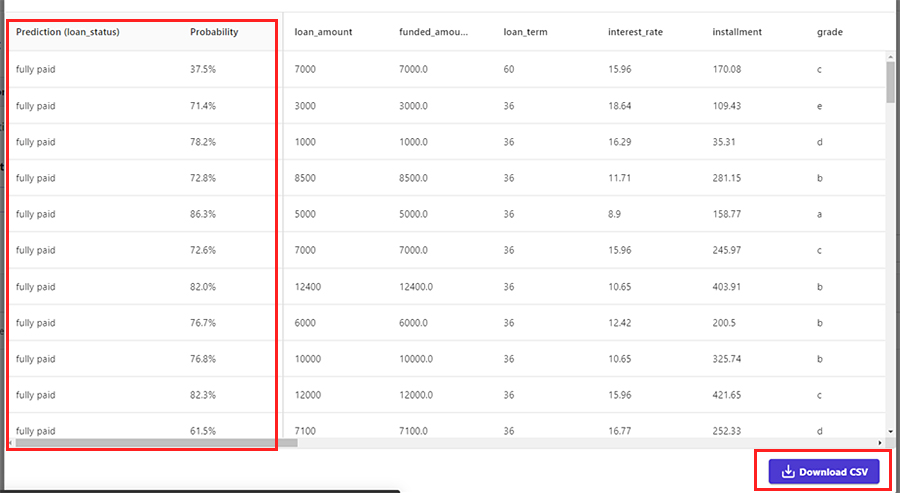
予測した結果とその予測における確信度(0~100%)が表示されます。結果をcsvでダウンロードすることも可能です。
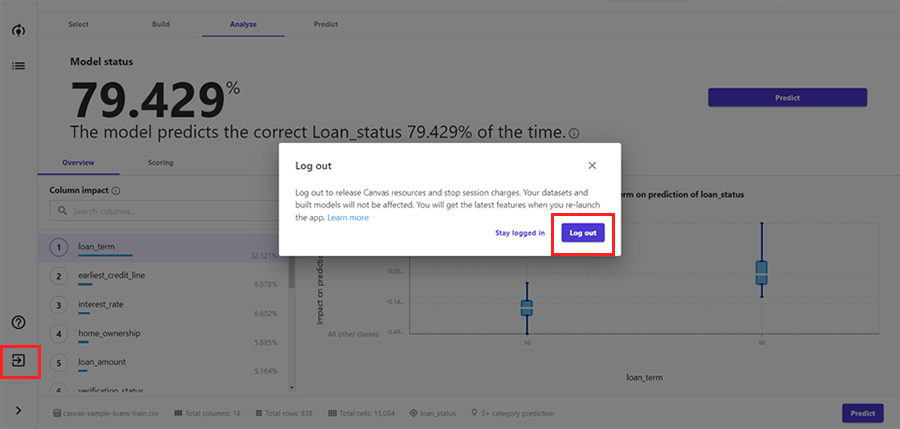
最後は必ずログアウトしてください。ログアウトせずにブラウザを閉じても、その後も課金が続いてしまいます。ご注意ください。
4.まとめ
いかがでしたでしょうか。後編の機械学習でもプログラミングは一切しませんでした。もちろん、前編での内容含めて、機能上、実現できないことはたくさんあります。重要なのは、ノーコードでできるところ/できないところを見極め、それを把握して次のステップへ進めてみることだと思われます。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。

クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理

