【Amazon Bedrock】Amazon Titanと日本語でチャットしたい!
~継続的な事前トレーニング編~
投稿日: 2024/02/08
はじめに
こんにちは、佐々木です。
Amazon Bedrockが一般提供開始されてから、半年が経とうとしています。
今回は、Amazon Bedrock基盤モデルのカスタマイズ方法を、作業サンプルを交えながら紹介します。
*本コラムの内容は、2024年1月時点の情報を基に作成しています。最新情報はAWSのWebページよりご確認ください。
*生成AIモデルを利用する際の入出力データの取り扱いは、AWSサービス利用規約、モデル開発元規約や自社ルールを遵守し、細心の注意をお願いします。
背景
Amazon Bedrockの特長として、AI21 Labs, Anthropic, Cohere, Meta, Stability AI, Amazonなどの企業が提供するさまざまな生成AIの基盤モデルの中から、自社のニーズに合ったモデルを選択、利用できる点が挙げられます。
しかし、これら基盤モデルの大半は英語テキストデータを中心にトレーニングされており日本語のテキストデータをトレーニングしているとは限らないため、日本語の入出力を前提とした業務ユースケースでは、実質的な基盤モデルの選択肢は大幅に限定されてしまいます。
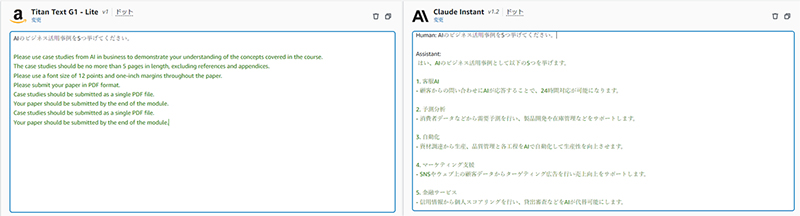
Playground画面でAmazon Titan Text G1 – LiteとClaude Instant v1.2に同様の質問をしたとき
Amazon Bedrockのトレーニング方法概要
独自のデータでAmazon Bedrockの基盤モデルをカスタマイズする方法には、「微調整(Fine-tuning)」、「継続的な事前トレーニング(Continued pre-training)」の2種類があります。
それぞれの違いとしては、
- 微調整:特定のタスクの精度を高める、少量のラベル付きデータを学習させる(教師あり学習)
- 継続的な事前トレーニング: ベースモデルにまだ存在しない新しい分野の知識をモデルに教える、大量のラベル無しデータを学習させる(教師なし学習)
現在、微調整は一般提供開始、継続的な事前トレーニングはプレビュー段階です。また、どちらもバージニア北部リージョンおよびオレゴンリージョンで利用できます。
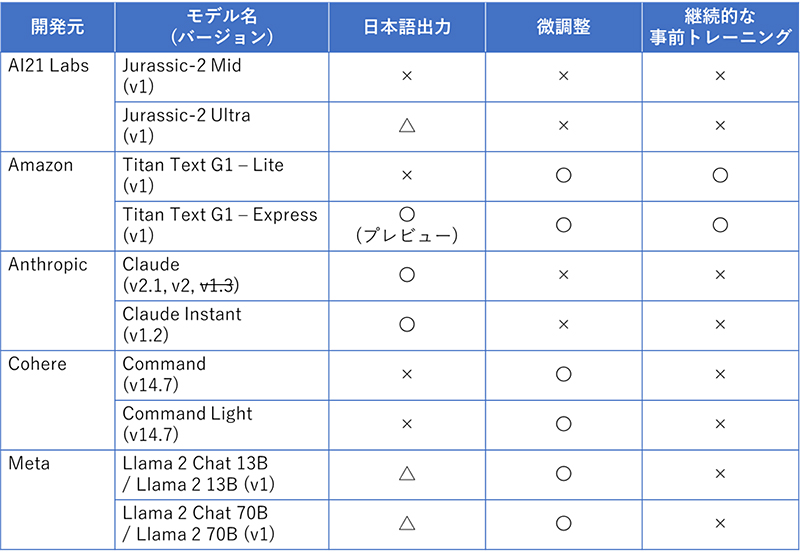
各基盤モデルの対応状況
現在Amazon Bedrockで提供されているテキスト生成モデルの日本語出力およびカスタマイズ可否は以下のように整理することができます。
※日本語出力については、以下の3段階に分類しています。
〇:日本語対応を発表している
△:日本語対応を発表していないが、日本語を出力できる場合がある(※弊社検証時)
×:日本語対応していない
カスタマイズ方針
Titan Text G1 – Liteを以下の2段階でトレーニングすることにより、最終的に「日本語の質問に日本語で回答できる状態」を目指します。
- ① 継続的な事前トレーニングを実施して、自然な日本語出力ができるようにする
- ① ②で作成したモデルをファインチューニングして、質問に回答できるようにする ここからは、①を実現するための方法を紹介します。回答の正確さについては、今回は問わないものとします。
手順
① -1: データ準備
まず初めに、トレーニング用の日本語テキストデータを用意する必要があります。
今回は、Wikipediaのダンプファイルをダウンロード、解凍したものを利用します。解凍後のデータが50GBを超えるため、ストレージ空き容量に余裕がある環境で実行しましょう。本コラムではSageMaker Studioを使っています。
(例)

Amazon Bedrockで継続的な事前トレーニングを実施する場合、学習データには以下のルールがあります。
- 1つのJSONLファイルで、各JSONレコードは”input”フィールドのみを持つ
- トレーニング1回あたりのレコード数上限:100,000
- 1レコードあたりのトークン数上限:4,096
これらを踏まえて、以下i~iiiのテキスト処理を実施します。(実装コードは割愛します。)
また、JSONLファイルは任意のS3バケットにアップロードします。
-
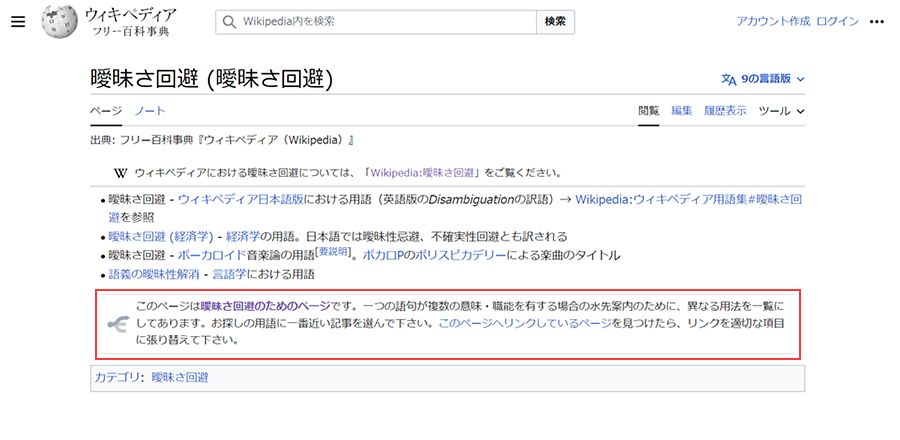
i. Wikipedia固有の文章(例:以下図の赤枠部分)を除去する
-
ii. トークン数上限に収めるため、各記事の先頭1,500文字を抽出
-
iii. 100,000記事分をJSON形式にして、1つのJSONLファイルに追加

② -2:トレーニング
管理コンソールを使えば、コーディングをすることなくAmazon Bedrockの基盤モデルをトレーニングすることができます。 先述の通り、今回は継続的な事前トレーニングジョブを選択します。
(例)
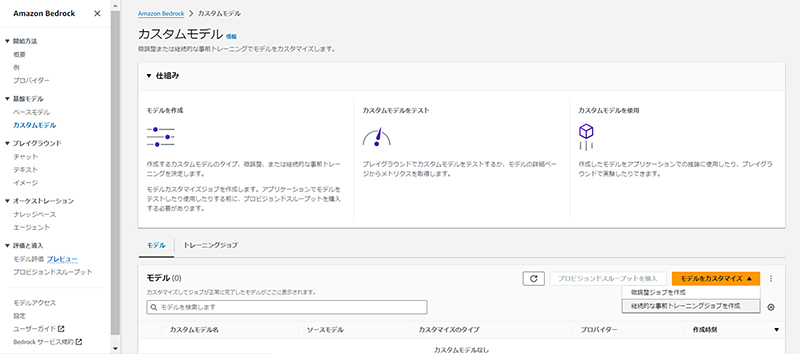
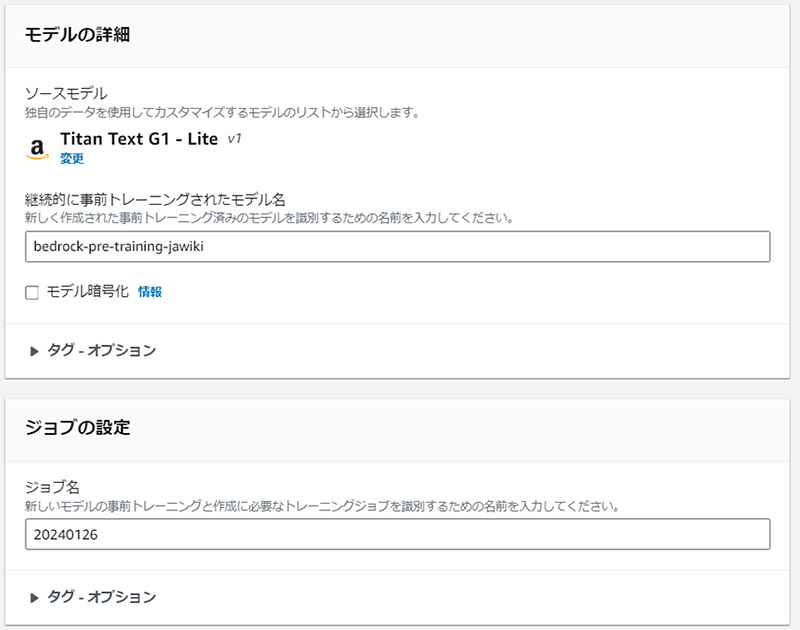
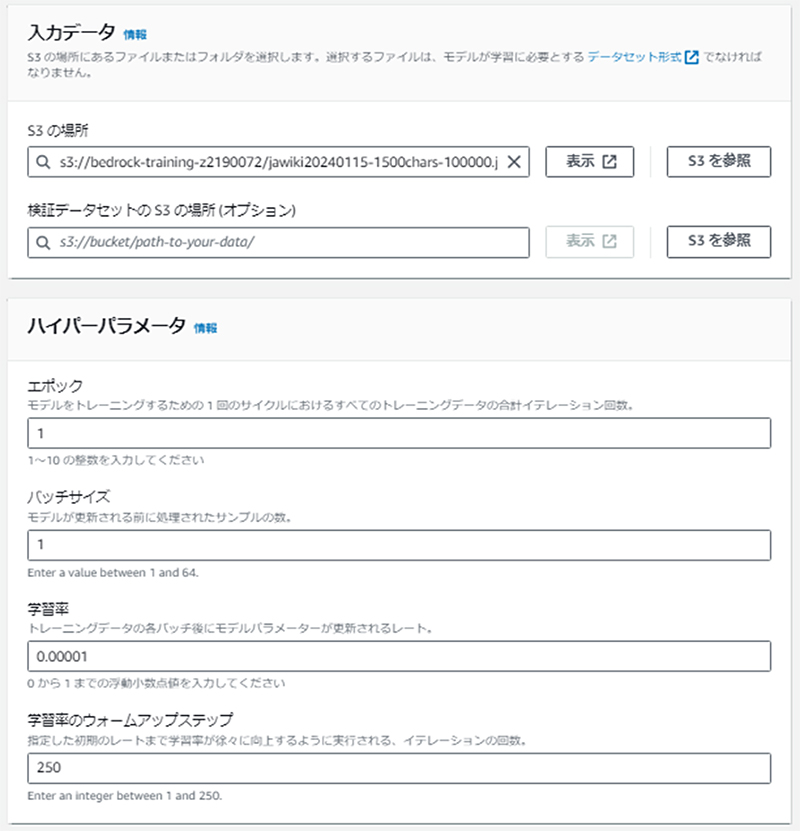
このとき、トレーニングにかかる料金はハイパーパラメータの「エポック」に比例する点に注意しましょう。Amazon Text Liteで、1レコードあたり4,000トークン、計100,000レコードをエポック数1でトレーニングする場合は、160USDになります。(※本コラム作成時点の料金による概算値)
https://aws.amazon.com/jp/bedrock/pricing/
トレーニングが完了すると、モデルの一覧に追加されます。
トレーニング開始から完了までにかかった時間は、ハイパーパラメータを上記の例通りに設定した場合で、7時間程度でした。
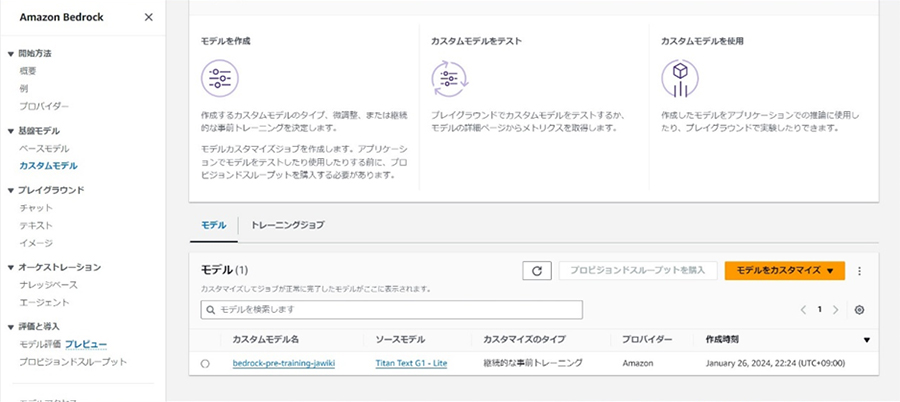
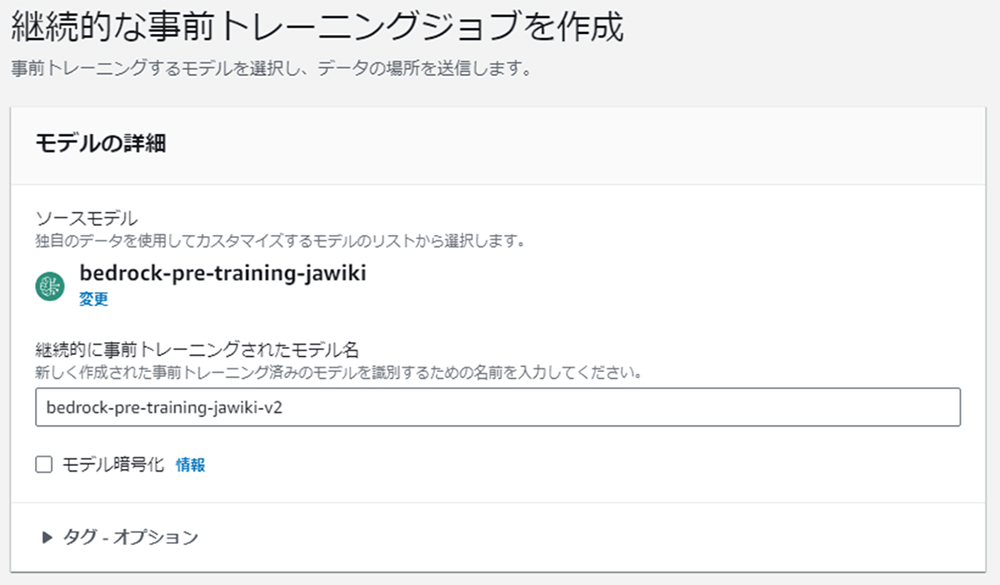
トレーニング後のモデルと新たな学習データを選択して、さらにモデルの改良を重ねることも可能です。
(例)
③ -3:プロビジョンドスループットの購入
トレーニングしたモデルを利用して推論(ここではテキスト生成、チャット)を開始するためには、プロビジョンドスループットの購入が必要です。
(例)
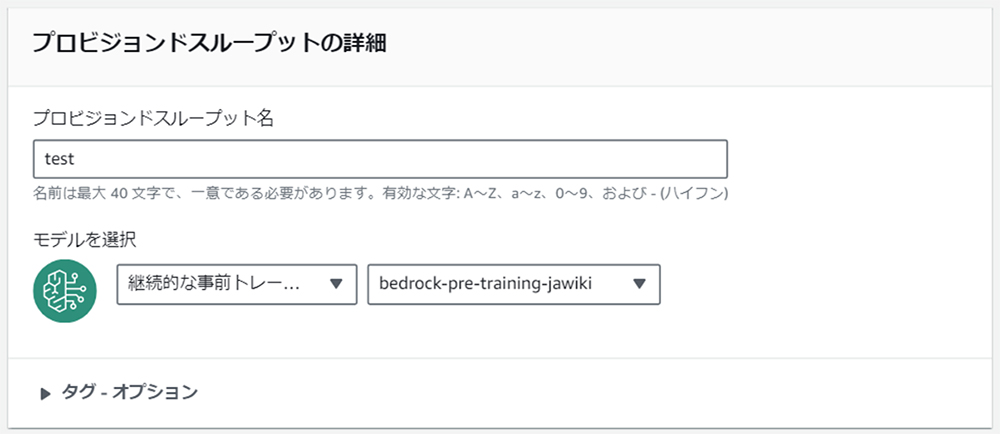
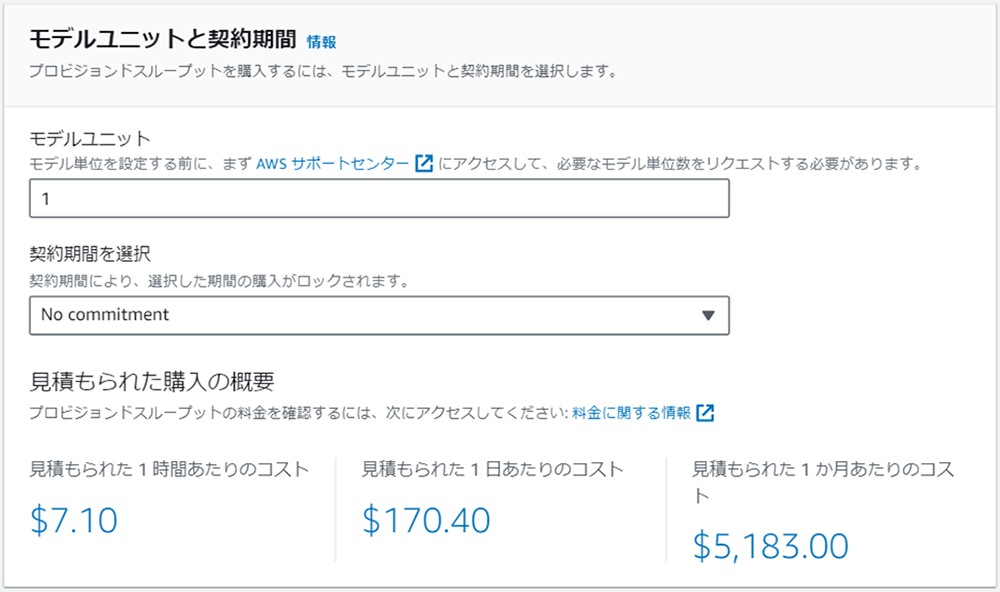
プロビジョンドスループットを購入したモデルを使う場合は、モデル、モデルユニット、契約期間によって料金が決まり、トークン数は料金に影響しません。(オンデマンド利用の場合はモデルおよび入力トークン数および出力トークン数によって料金が決まります。)
また、モデルユニットと契約期間は一度設定すると変更できません。
④ -4:推論
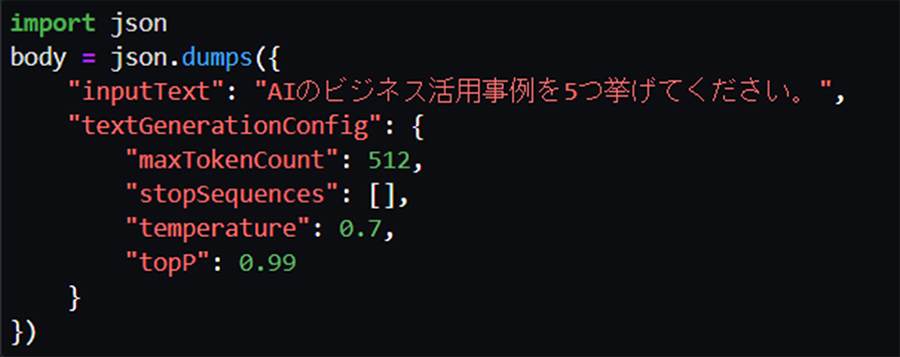
まずは、トレーニング前のモデルに、簡単な質問をしてみます。(多様な回答を生成したいので、temperatureおよびtopPはAmazon Titan Text Liteデフォルト値より大きくしています。)
先述の通り、トレーニング前のモデルでは、回答内容は合っているものの日本語出力されません。
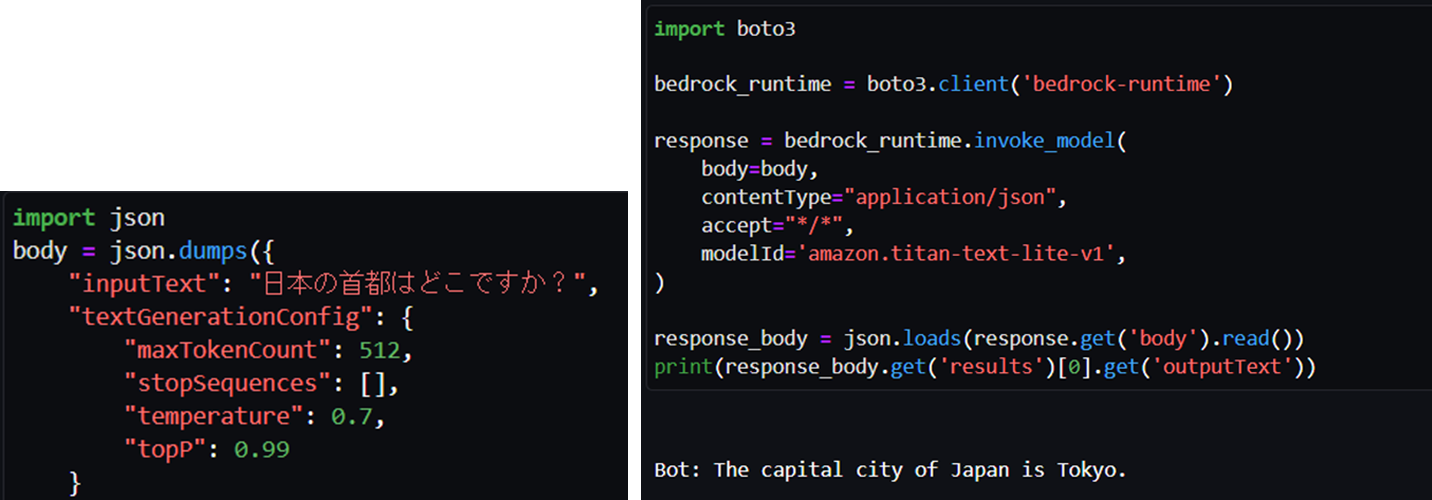
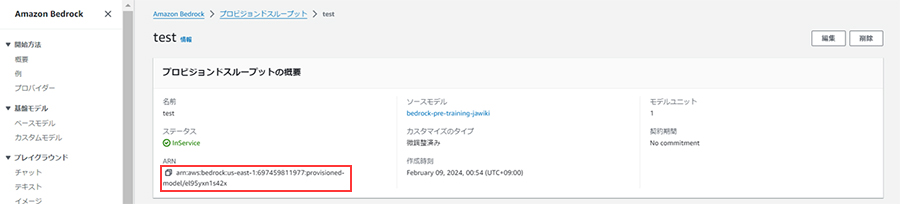
次に、トレーニング後のモデルに同じ質問およびパラメータ(上記プログラムのbody)を入力して推論させます。このとき、invoke_modelメソッドのmodelIdはモデル名ではなく、購入したプロビジョンドスループットのARN(赤枠部分)を指定します。




何回か推論を実行したところ、文章が大きく破綻せず意味を理解でき、都市名を含むようなテキストが生成される傾向にありました。(先述の通り、回答の正確さについては、今回は問わないものとします。)
また、ところどころ文体がWikipediaに影響されているようにも見えました。
続いて、冒頭のPlaygroundと同じ質問をします。先ほどの質問より、回答の自由度が高く、専門性も求められるような内容です。
トレーニング前のモデルであっても、質問意図通りの回答が出力されるまでに何回か推論を繰り返す必要がありました。また、トレーニング後のモデルの場合は無関係な文章が生成されました。



トレーニング前のAmazon Titan Text Liteが生成したテキスト



Amazon Titan Text Liteをトレーニングしたモデルが生成したテキスト
結果まとめ
カスタマイズ方針で述べた通り、今回は「自然な日本語出力ができるようにする」ことをゴールに、Amazon Bedrock基盤モデル(Amazon Titan Text Lite)の継続的な事前トレーニングを実施しました。Wikipediaの表現風になっているように見受けられる箇所はありますが、人間が読んで意味が理解できるような日本語の文章を生成することができました。
また、簡単な質問であれば(正解ではないものの)関連するような単語を含む回答を生成していましたが、難しい質問の場合は、学習データ不足のためか、関連性の低い回答が生成されました。
※継続的な事前トレーニングは正解(教師データ)を与えず、次の単語を予測するよう学習するだけなので、回答の正確性を高めたい場合はRAG(Retrieval-Augmented Generation、外部ソースから取得した情報を用いて回答する手法)によってハルシネーション(事実と異なる情報を生成すること)を抑制したり、調整(Fine-tuning)と組み合わせたりする方が有用です。
さいごに
今回はWikipediaの記事データ(言い換えると雑多なデータ)を学習させましたが、ビジネス目的では、専門用語を学習させる、特定のプログラミング言語を学習させるなどのユースケースが挙げられます。
AWSでの生成AI活用に関するアイデアやご相談は、お気軽にCTCまでお寄せください。
次回は調整編を予定しています。果たして表題の通り、日本語でチャットできるようになるのでしょうか…?
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。

クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理

