Amazon AthenaでApache Icebergを使用してみた(その2)
投稿日: 2024/03/11
はじめに
こんにちは、稲守です。
前回の記事では、Apache Icebergについて5つの特徴を順番に紹介しました。前回は概要だけでしたので実際どのように使えるのかが伝わりづらかったと思います。
今回は実際にAmazon Athenaを使用してIcebergテーブルを実際に触ってどんな使用感になるのか体感してみましょう。Icebergテーブルに対しAthenaでデータレイクに対し、DELETEやUPDATE を含むACIDトランザクション操作をしたり、タイムトラベルが実現できたりするのをみると便利そうだなと感じてもらえると思います。
やってみる
Icebergの特徴をAmazon Athenaで順番に操作して確認してみます。
① SQLによるデータ更新
まずは、Icebergテーブルのデータを配置するため、S3バケットを作成します。今回は、使用するS3バケットとして"s3://ctc-iceberg-demo-2024"を作成します。
Amazon Athenaのクエリエディタからデータベースを作成します。
CREATE DATABASE iceberg_database;
データベースを作成したら、クエリエディタの左側のデータベースから作成したデータベースの"iceberg_databse"に切り替えます。
いよいよIcebergテーブルを作成してみましょう。
CREATE TABLE sales (
id int,
sales_at timestamp,
product_name string,
unit_price int,
quantity int
)
LOCATION 's3://ctc-iceberg-demo-2024/iceberg_database/sales/'
TBLPROPERTIES ('table_type' ='ICEBERG');
作成したらS3バケットを見てみます。
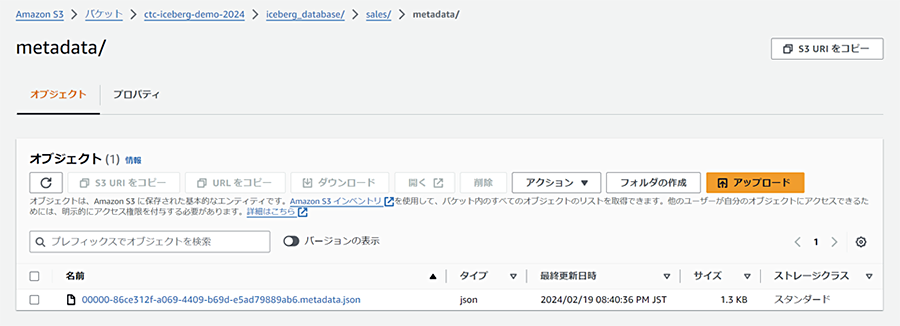
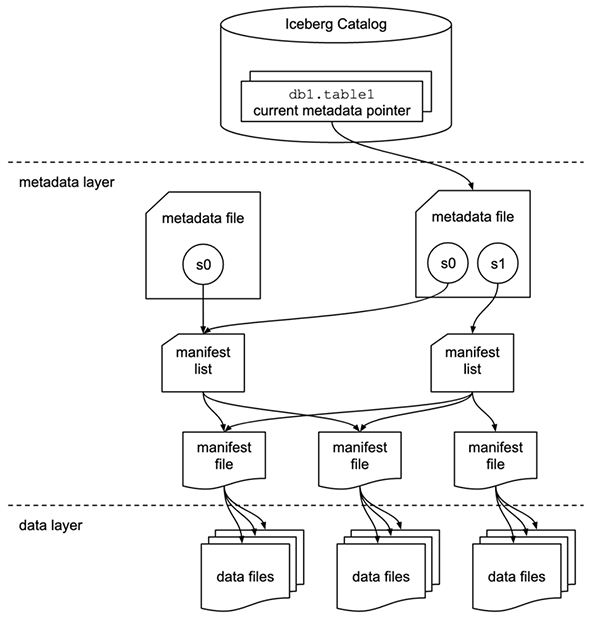
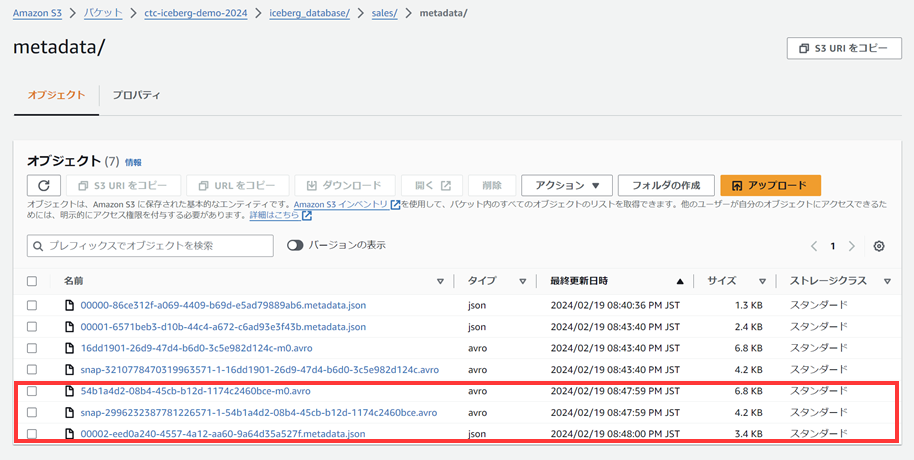
指定したフォルダ以下にmetadata/というフォルダができて、JSONファイル一つ作成されています。metadata/フォルダ以下に以下の図にあるメタデータレイヤーのファイル群(メタデータファイル、マニフェストファイル、マニフェストリスト)が格納されます。まだデータを挿入していないため、マニフェストファイルやマニフェストリストはありません。
次にデータを挿入してみましょう。
INSERT INTO sales VALUES (1, timestamp'2024-02-01 09:00:00', 'Apple', 200, 2);
テーブルを確認すると、データが入っていることが確認できます。
SELECT * FROM sales ORDER BY 1;

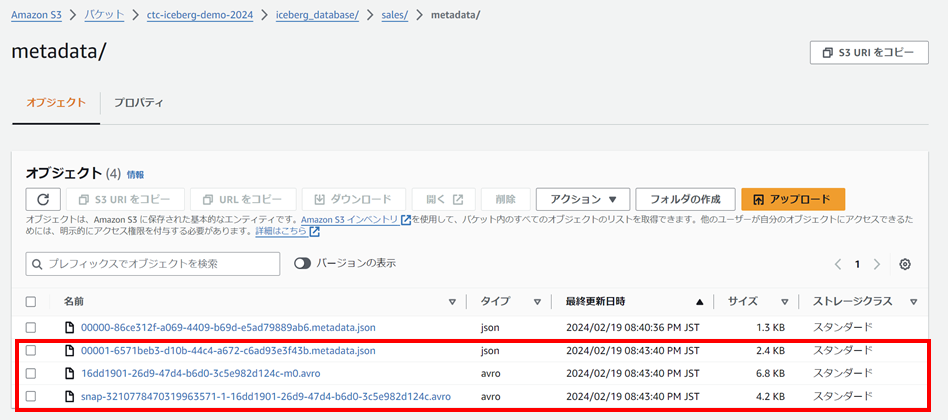
S3ではどうなっているでしょうか。
metadata/フォルダに新しいファイルが3つ作成されています(最初のファイルを入れて4つのファイルが存在しています)。
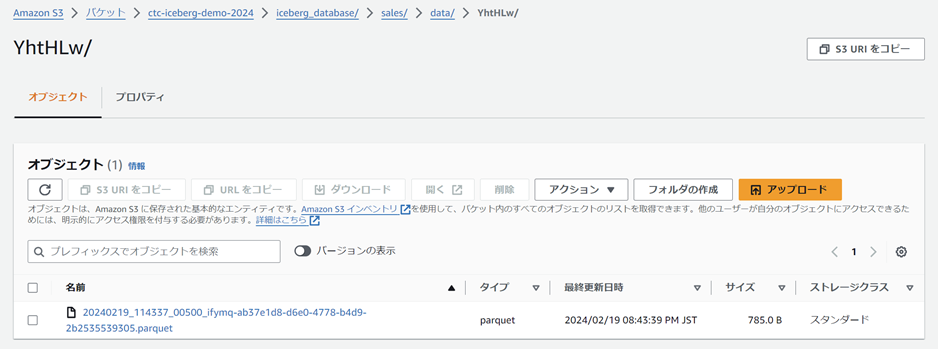
またdata/フォルダにもファイルができています。data/フォルダ以下がデータレイヤーにあるデータファイルの実体です。
続けて、行を追加してみましょう。
INSERT INTO sales VALUES
(2, timestamp'2024-02-02 10:00:00', 'Strawberry', 500, 1),
(3, timestamp'2024-02-03 11:00:00', 'Orange', 300, 3),
(4, timestamp'2024-02-04 12:00:00', 'Grape', 400, 2);
SELECT * FROM sales ORDER BY 1;
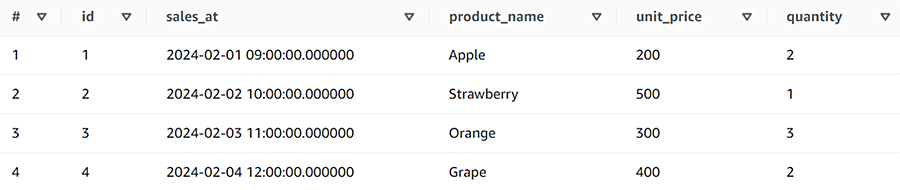
S3を確認すると、さらに3つのファイルが作成されています。
またデータフォルダにも新しいファイルが作成されています。以下の画像ではファイルが一つだけしかないように見えますが先ほどのデータファイルとはプレフィックスが異なります。
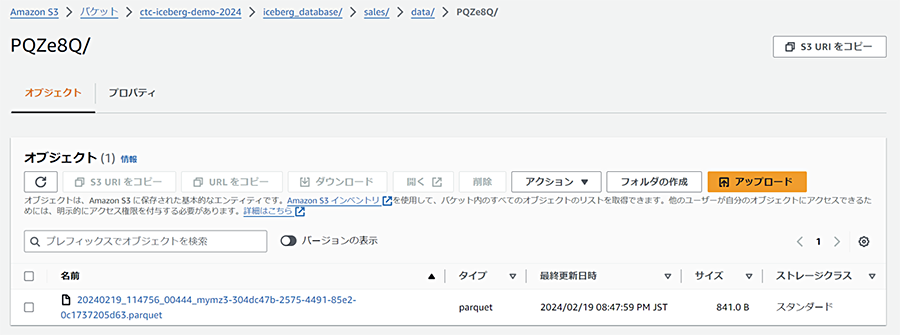
このようにトランザクションの度にメタデータが更新され、そのメタデータから参照されているデータファイルが追加されていることがわかります。
削除も試して見ましょう。
DELETE FROM sales WHERE id = 3;
結果を確認します。
SELECT * FROM sales ORDER BY 1;
DELETE文で指定したid=3の行が削除されています。

UPDATEも試して見ましょう。
UPDATE sales SET unit_price = 480
where id = 2;
結果を確認します。
SELECT * FROM sales ORDER BY 1;
id=2の行のunit_priceが480に更新されています。

このように、INSERT INTO文やDELETE文、UPDATE文によって、DML操作が出来ることが確認できました。
② スキーマ進化
Icebergの特徴の2つ目であるスキーマ進化について試して見ましょう。
作成したsalesテーブルに合計金額のカラムを追加したくなったとします。
ALTER TABLE文でカラムを追加します。
ALTER TABLE sales ADD COLUMNS (
total_amount int
);
結果を確認します。
SELECT * FROM sales ORDER BY 1;
テーブルをみるとtotal_amountカラムが追加されていることが確認できます。当然ながらまだ値は入っていません。

ここに単価×数量で合計金額をセットしましょう。
UPDATE sales set
total_amount = unit_price * quantity;
結果を確認します。
SELECT * FROM sales ORDER BY 1;
total_amountに合計金額が入ったことが確認できました。

一度作成したテーブルでもこのようにカラムを追加することができます。前回のエントリでも取り上げたように、カラムの削除や型の変更、名称変更や並べ替えも出来ます。
なお、型の変更は現在のところ以下の操作のみサポートされています。
- 整数から大きな整数
- 浮動小数点から倍精度浮動小数点
- 10 進数型の精度を上げる
③ 隠しパーティション
次にパーティションを持つテーブルを作成してみましょう。Icebergテーブルでは、パーティションのための列を特別に作る必要はありません。テーブルの列を使用してパーティションを設定できます。またパーティション変換変数を使用して、タイムスタンプ型から日付や月、年のパーティションとすることも自在です。指定できる変換関数は前回のエントリを参照してください。以下では、sales_at列に対して日付によるパーティション関数(day())を指定した例です。
CREATE TABLE sales_partition (
id int,
sales_at timestamp,
product_name string,
unit_price int,
quantity int
)
PARTITIONED BY (day(sales_at))
LOCATION 's3://ctc-iceberg-demo-2024/iceberg_database/sales_partition/'
TBLPROPERTIES ('table_type' ='ICEBERG');
このパーティションを持つテーブルにデータを入れてみましょう。
INSERT INTO sales_partition VALUES
(1, timestamp'2024-02-01 09:00:00', 'Apple', 200, 2),
(2, timestamp'2024-02-02 10:00:00', 'Strawberry', 500, 1),
(3, timestamp'2024-02-03 11:00:00', 'Orange', 300, 3),
(4, timestamp'2024-02-04 12:00:00', 'Grape', 400, 2),
(5, timestamp'2024-02-04 12:00:00', 'Lemon', 100, 5);
結果を確認します。
SELECT * FROM sales_partition ORDER BY 1;
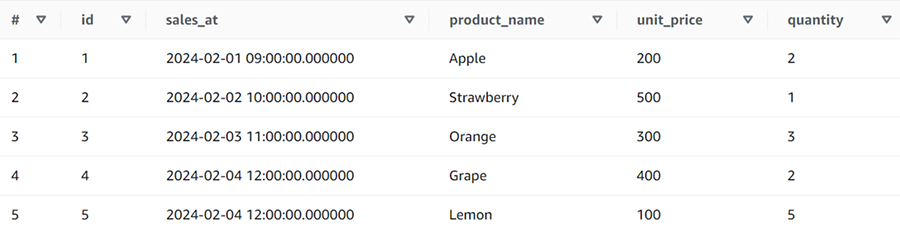
パーティション毎のメタ情報は、"テーブル名$partitions"を参照することによってわかります。
SELECT * FROM "sales_partition$partitions" ORDER BY 1;

画像が小さくて見づらいですが、パーティションに入っている各カラム(id、sales_at、product_nameなど)の値の最小、最大、Nullカウントなどがdataカラムに入っています。この情報をもとにどのパーティションのファイルをスキャンすればよいかわかるわけです。
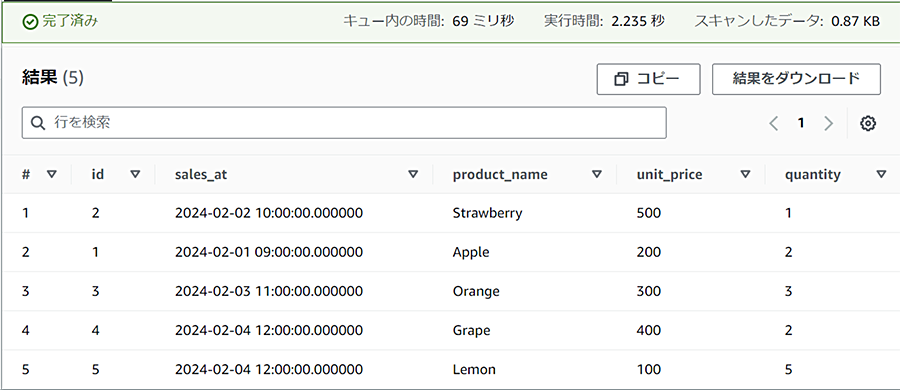
まず全件スキャンされるような場合を確認してみます。
SELECT * FROM sales_partition
WHERE id > 0;
スキャンしたデータは0.87KBとなります。
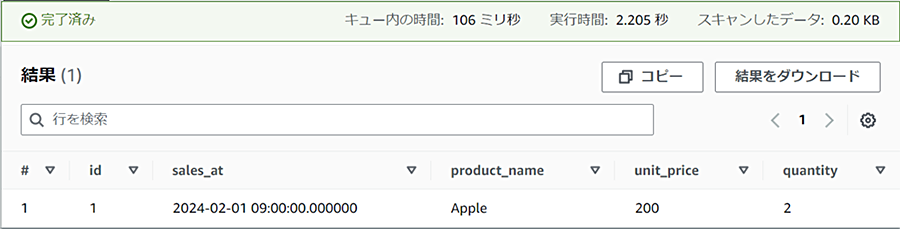
ここでid=1として検索するとどうなるでしょうか。パーティションを使用してスキャン量が少なくなることを期待したいです。
SELECT * FROM sales_partition
WHERE id = 1;
結果は期待通りスキャンしたデータは0.20KBとなりました。これは、id=1のデータが入っているパーティションは、"sales_at_day=2024-02-01"のパーティションだけが対象であることがわかるため、最小限のファイルのみスキャンされたわけです。
なお、AthenaではIcebergテーブルのパーティション進化は2024年2月現在未対応です。
④ タイムトラベルとロールバック
最初に作成したsalesテーブルを使用して、タイムトラベルクエリを試してみます。
まず現在の状態を確認します。
SELECT * FROM sales;
total_amount列を追加し、合計金額で更新していました。

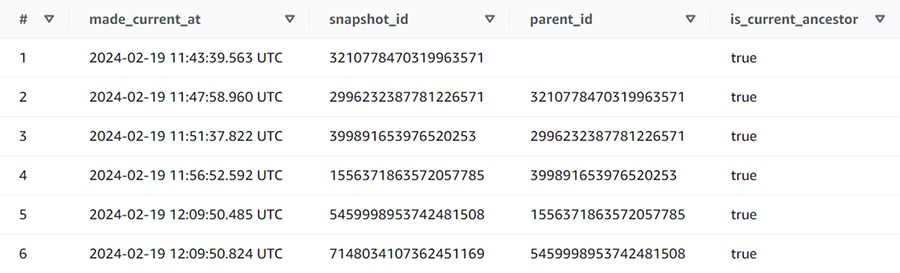
そこでテーブルの履歴を確認します。以下のビュー(テーブル名$history)を参照すると、テーブルの変更履歴が確認できます。
SELECT * FROM "sales$history";
ここでタイムスタンプを指定してタイムトラベルクエリを実行します(タイムスタンプを指定する場合には、タイムゾーン付きの時間指定となることに注意してください)。
SELECT * FROM sales FOR TIMESTAMP AS OF timestamp'2024-02-19 12:00:00 UTC';
total_amount列が定義前の状態に戻っていることが確認できます。

このように、データセットを元の状態に戻すことができるため、機械学習などで学習した当時のデータに戻したい場合でも、柔軟に対応することができます。
⑤ データ圧縮
タイムトラベルで見たように、データの更新をしていくと、スナップショットのデータがだんだん溜まり、クエリの効率が低下したり、追加の計算コストが発生するようになったりします。 AthenaではOPTIMIZE処理とVACUUM処理の2つが用意されています。
まずはスナップショットの有効期限切れと孤立ファイルの削除を行うVACUUM処理をしてみます。
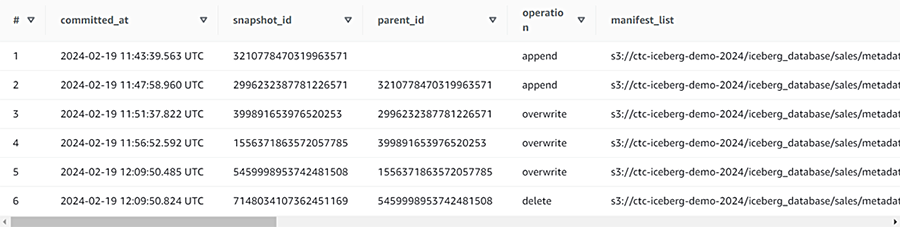
まず現在のスナップショットの状況を確認します。
SELECT * FROM "sales$snapshots";
スナップショットが6つ存在しています。
次にスナップショットの有効期限を設定します。デフォルト値は5日間(432,000 秒)ですが、動作検証のためにあえて短い値(1時間(3,600秒))で設定します。
ALTER TABLE sales SET TBLPROPERTIES (
'vacuum_max_snapshot_age_seconds'='3600',
);
VACUUMを実行します。
VACUUM sales;
スナップショットの状態を確認します。
SELECT * FROM "sales$snapshots";
最新のスナップショットだけになったことが確認できました。

次にOPTIMIZE圧縮アクションを試して見ます。
OPTIMIZEでは、関連する削除ファイルのサイズと数に基づいて、データファイルをより最適化されたレイアウトに書き換えます。
まずは現在のファイル状態を確認します。削除ファイルがあるためファイルが2つに分かれています。
SELECT * from "sales$files";

OPTIMIZE処理を実行します。
OPTIMIZE sales REWRITE DATA USING BIN_PACK;
SELECT * from "sales$files";
結果を確認するとファイルが一つになっていることが確認できました。

最後に
前回と今回で、オープンなテーブルフォーマットであるApache Icebergの概要とAthenaでの使用感について紹介しました。Icebergテーブルを使用するとAthenaだけでも豊富なデータ操作ができることが伝わったのではないでしょうか。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。
クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理
