検索拡張生成にAmazon Kendraを用いた生成系AIアプリ
~ Amazon Kendra紹介編 ~
投稿日: 2023/10/2
はじめに
こんにちは、高橋です。
当社に在籍するMachine Learningカテゴリの2023 Japan AWS Top Engineersである山近氏と今はやりの生成系AIに関して何か試してみたいよねと話していたところ、Amazon Kendraを活用した、生成系AIアプリケーションを作成してみようとなりました。そこで今回は、私の方でそもそもAmazon Kendraとは何かと実際の利用方法についてご紹介し、次回は山近氏からAmazon Kendra用いた生成系AIアプリケーションの実装についてご紹介します。
1.そもそもAmazon Kendraとは?
Amazon Kendraは機械学習を活用した検索システムサービスです。Amazon Kendraを使用するとソースとしてインターネット上のデータは勿論、自社で保有するデータも対象にすることで、独自の検索システムを作成することができます。また、API経由でAmazon Kendraにアクセスすることでさまざまなアプリケーションに組み込むことが可能です。
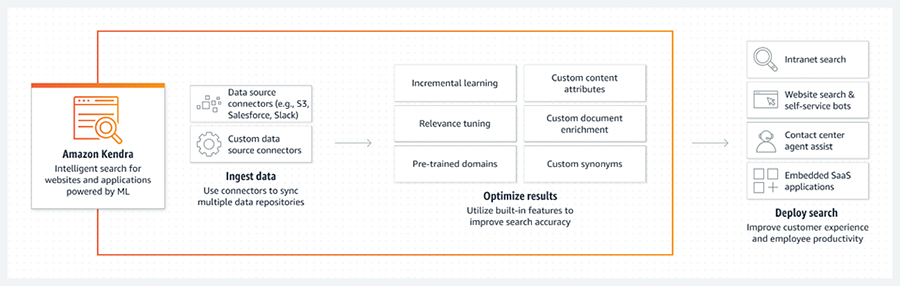
Amazon Kendraは開発者版とエンタープライズ版が提供されているので、開発者版で試した後に、エンタープライズ版で実装していくのがいいと思います。
| 開発者版 | エンタープライズ版 | |
|---|---|---|
| 1日あたりの検索上限 | 4000 | 8000 |
| データソース数 | 5 | 50 |
| アベイラビリティーゾーン | 1 | 3 |
| 無料枠 | 750 時間(最初の30日) | なし |
| 1時間あたりの料金 | 1.125 USD/時間 | 1.4 USD/時間 |
| コネクタ料金 | 0.35 USD/時間 |
|---|---|
| スキャンされたコネクタ使用ドキュメント | ドキュメントごとに 0.000001 USD |
2.Amazon Kendraが対応しているデータソース
Amazon Kendraは現時点(2023/7/31)で下記の様な多種・多様なデータソースをサポートしており、非常に強力な独自検索システムを簡単に作成することが可能です。
- PDFファイル
- HTMLファイル
- XMLファイル
- XSLT(Extensible Stylesheet Language Transformation)ファイル
- Markdown(MD)ファイル
- CSVファイル
- Excel(エクセル)ファイル
- JSONファイル
- リッチ テキスト形式(RTF)ファイル
- PPT(パワーポイント)ファイル
- Wordファイル
- プレーンテキスト(平文文書)ファイルAdobe Experience Manager
- Alfresco
- Amazon S3 buckets
- Amazon RDS
- Amazon FSx
- Amazon Kendra Web Crawler
- Amazon WorkDocs
- Box
- Confluence
- Custom data sources
- Dropbox
- GitHub
- Gmail
- Google Workspace Drives
- Jira
- Microsoft Exchange
- Microsoft OneDrive
- Microsoft SharePoint
- Microsoft Teams
- Microsoft Yammer
- Quip
- Salesforce
- ServiceNow
- Slack
- Zendesk
3.Amazon Kendraの設定し、利用してみる
ここからはAmazon Kendraを実際に設定してみたいと思います。
(1)Indexの作成
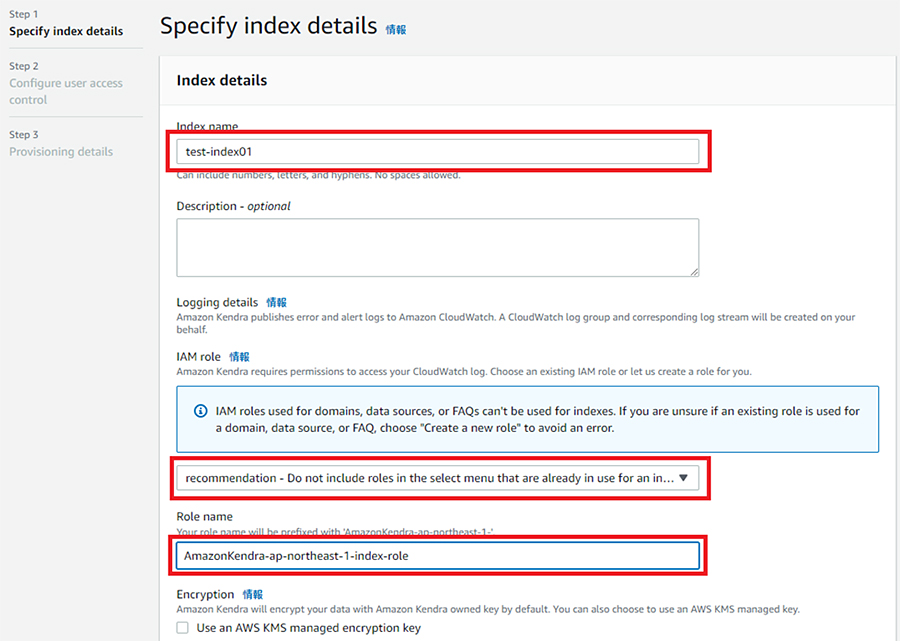
Amazon Kendraの利用はIndex作成から始まります。Amazon Kendraのページに移動し、「Create an Index」をクリックします。

最低限Index nameとIAM role(recommendationを選択し、任意の名前を入力)を作成し、必要に応じてKMSでの暗号化とTag設定を行い、「Next」をクリックします。
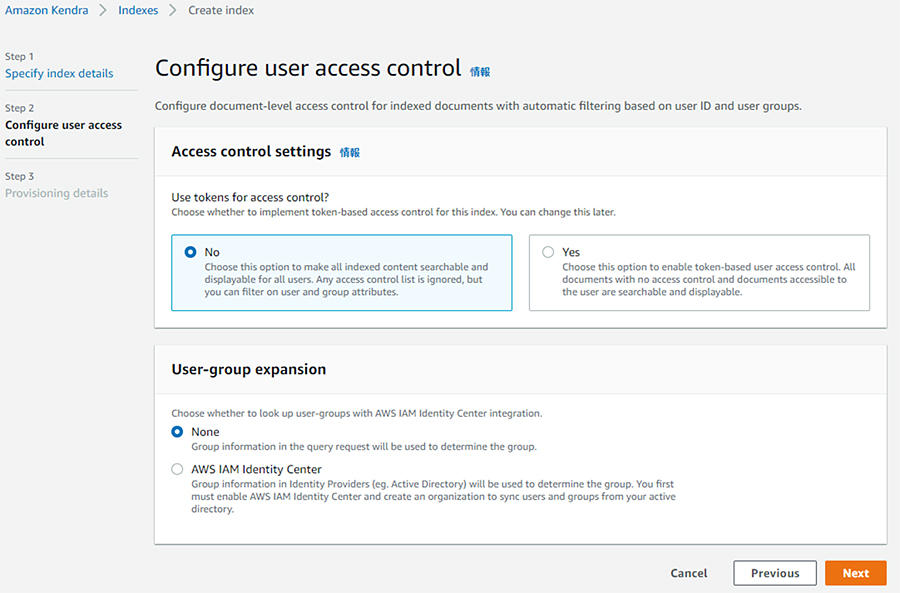
アクセスコントロールの設定を行います。今回はデフォルトの状態のまま何も設定せずに「Next」をクリックします。
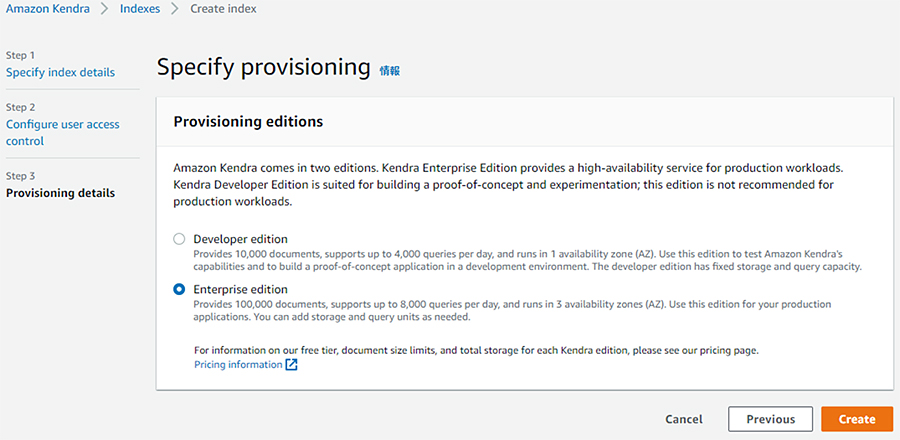
エディションを選択します。今回は Enterprise Edition を選択しますが、検証の場合はDeveloper Editionで問題ありません。
暫く待つと(今回は30分程度)Indexの作成が完了します。
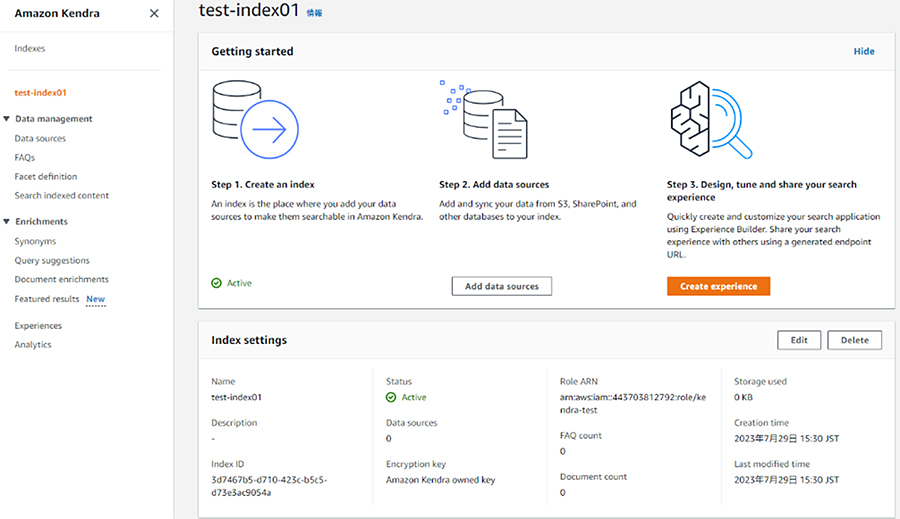
(2)データソースの追加
続いて検索対象となるデータソースを追加します。今回はデータソースとして、S3上のバケットと当社のAWS関連のページを追加したいと思います。
ソースの追加は先程の画面で「add data source」をクリックします。
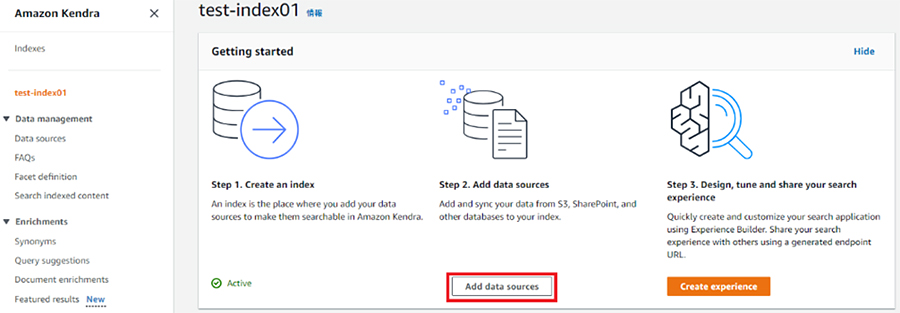
今回はS3バケット上に既にデータを保存しており、そこのデータを検索対象としたいので、Amazon S3 connectorの「Add conector」をクリックします。
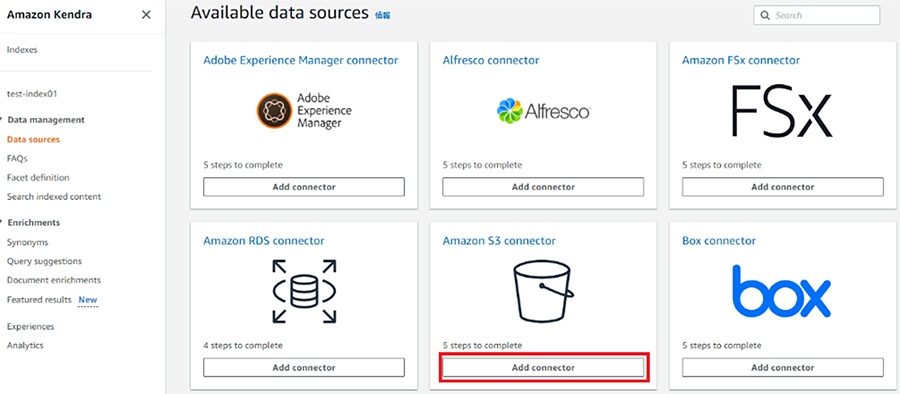
Data Souce nameに任意の名前を入力し、Default Languageで「Japanese(ja)」を選択し、「Next」をクリックします。
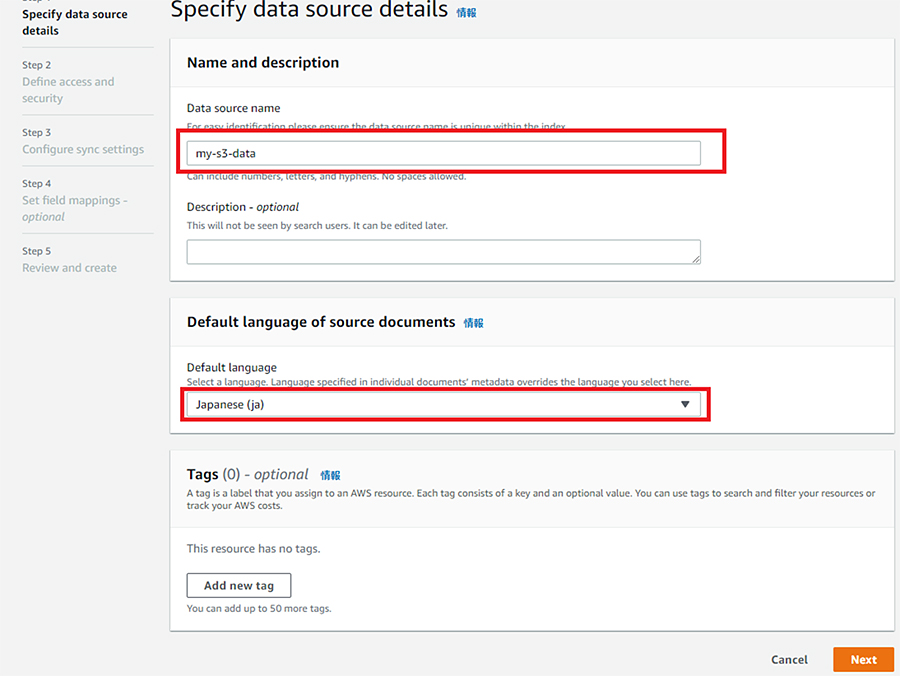
IAM roleで「recommendation」を選択し、Role nameに任意のロール名を入力し、「Next」をクリックします。
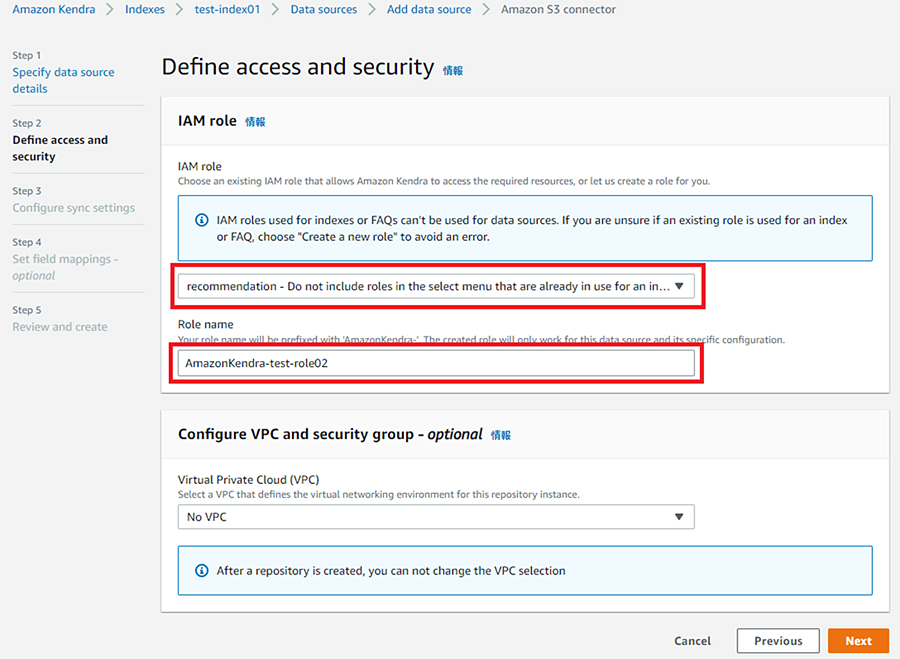
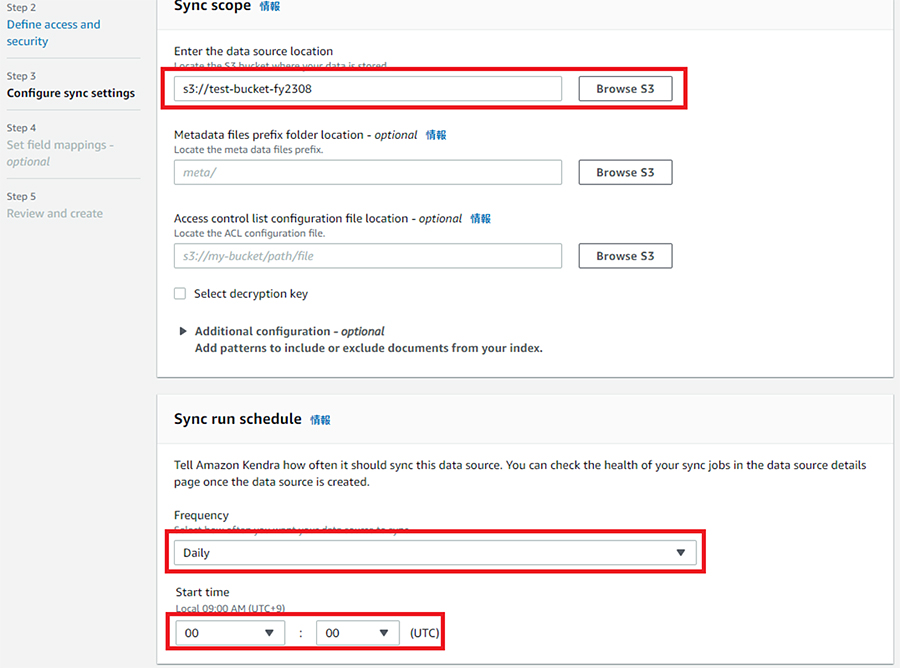
Browse S3をクリックし、データが保存されているS3バケットを選択し、FrequencyでS3からデータを自動で取得する頻度と時間を選択し、「Next」をクリックします。
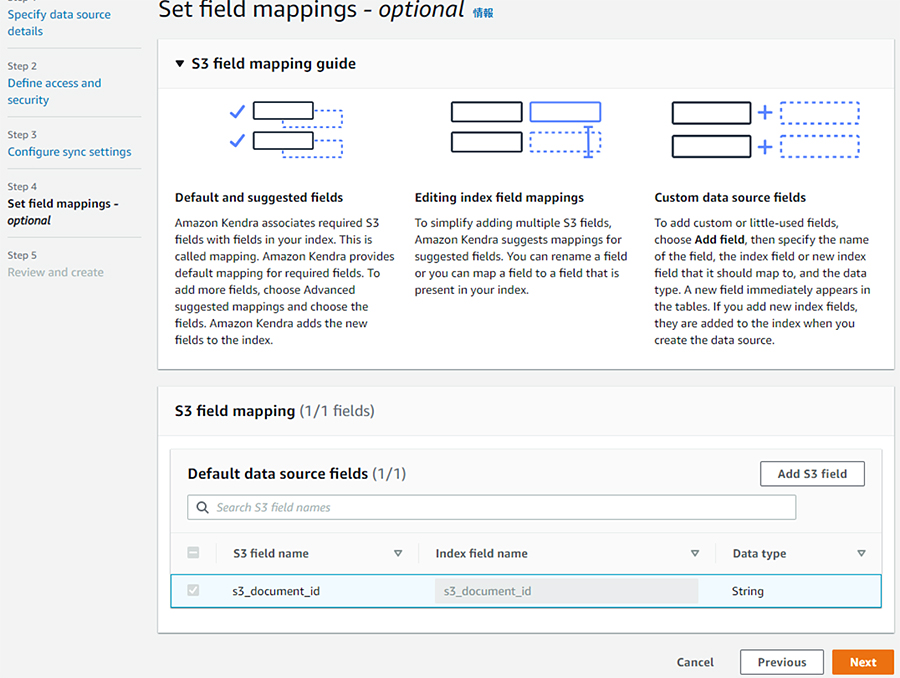
フィールドマッピングの設定を行います。今回はデフォルトの状態のまま「Next」をクリックします。
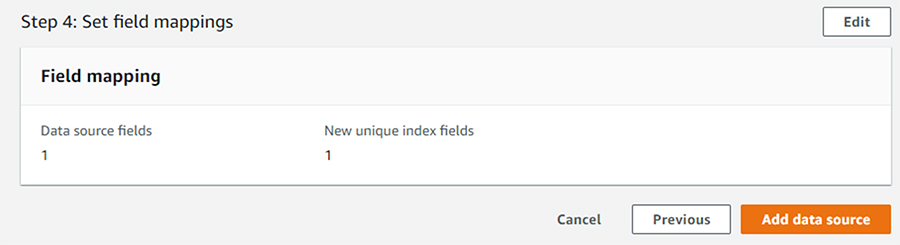
確認画面で設定内容を確認し、「Add data source」をクリックし、データソースの追加を行います。
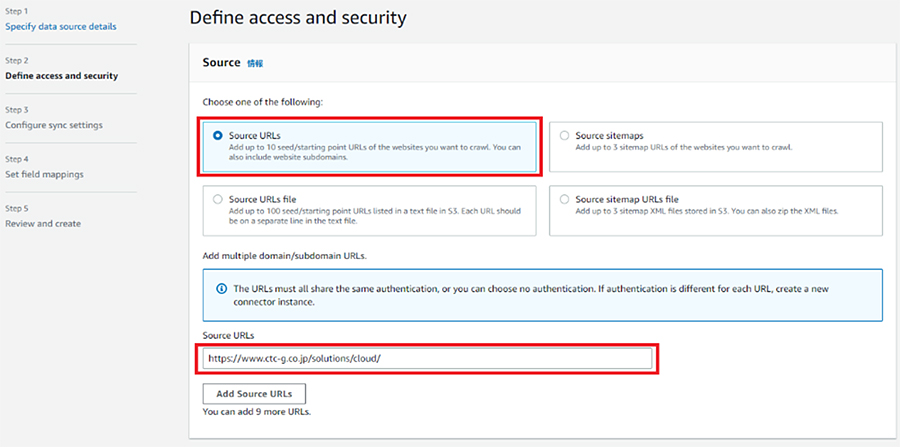
続いて当社の製品及びブログをデータソースに加えたいので、Add data sourceの中のWeb Crawlerの「Add connector」をクリックし、ソースとして「Source URLs」を選択し、URLを入力して、自社のページを検索対象に追加します。
追加の結果は各データソースのSync historyに表示されます。
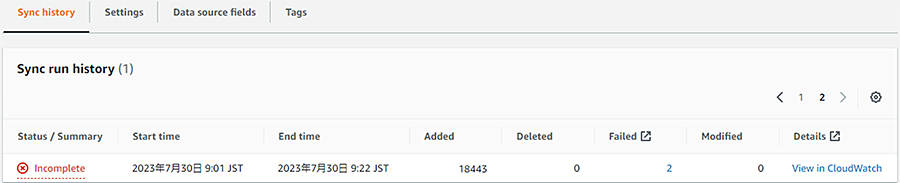
取り込みの失敗がある場合、Failed欄が数字のリンクになっており、それをクリックするとCloudWatch Insightのページに飛び、クエリを実行すると何に失敗したか確認することができます。
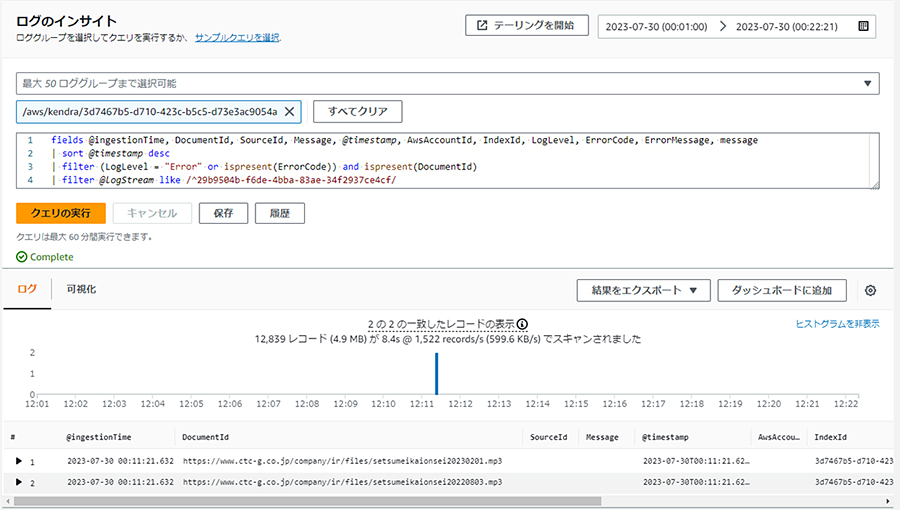
上記の結果から取り込みに失敗したのは音声データのページであることが確認できました。
(3) 検索機能の確認
データソースの追加が完了したら、実際に検索ができるか確認を行います。検索は作成したインデックスの画面で左のメニューから「Search indexed content」をクリックして検索画面を開きます。
検索の言語はデフォルトでは英語となっているので、右のセッティングメニュー(スパナのアイコン)をクリックし、言語を「Japanese(ja)」を選択し、設定を保存します。
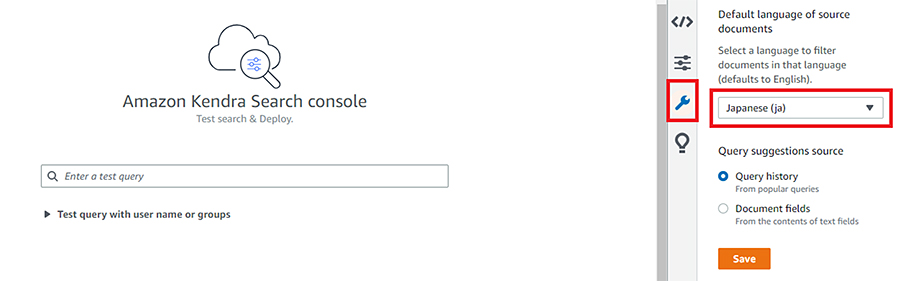
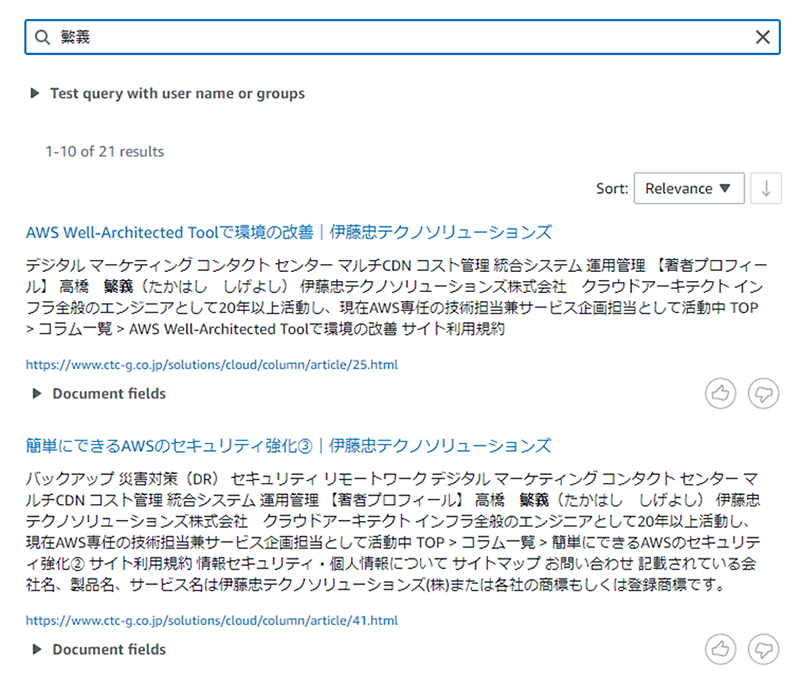
言語を日本語にした後、検索のBoxに検索したい文字を入力すると、データソース内の検索結果が表示されます。
作製した検索機能は簡単にユーザやアプリケーションに共有することが可能です。ただしユーザに対してはIAM Identity Centerに登録されたユーザでなければならないので、ご注意ください。
4.さいごに
ここまで見て頂いたように、Amazon Kendraを使用すると簡単に独自の検索エンジンを作成することができます。自部署や社内のナレッジを共有し、簡単に見つけられる仕組みを導入したいとお考えの方は是非こちらのサービスを利用してみてください。
また、次回はAmazon Kendraを用いた生成系AIのアプリケーションの作成について、山近氏よりご紹介させていただきますので、お楽しみにお待ちください。
検索拡張生成にAmazon Kendraを用いた生成系AIアプリ~ 生成系AIアプリの構築編 ~
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。



クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理

