検索拡張生成にAmazon Kendraを用いた生成系AIアプリ
~ 生成系AIアプリの構築編 ~
投稿日: 2023/10/2
はじめに
こんにちは、伊藤忠テクノソリューションズ 山近です。Amazon Kendra+LangChainを利用した生成系AIアプリの構築手順がAWS Blogに上がっておりましたので、実際に構築してみました。
1.生成系AIと基盤モデルの重要性
①生成系AIと従来のAIモデルとの違い
従来のAIモデル作成では、自らでデータを収集してラベル付けし、前処理やアルゴリズム選定などのモデリングを行い、モデル作成を行うことが多かったと思います。また、この時の予測は、回帰や分類など数値情報がメインでした。
生成系AI は、会話、ストーリー、画像、動画、音楽など、新しいコンテンツやアイデアを作成できる人工知能(AI)の一種で、他のAIと同様に機械学習モデルを利用しています。生成系AIは種々のコンテンツを生成できる反面、膨大な量のデータで事前にトレーニングされた非常に大規模なモデルが必要で、これが、一般に基盤モデル (Foundation Models:FM) と呼ばれています。
②基盤モデル
仮に、学習データを集められたとしても、生成系AIモデル作成のためのボトルネックの1つに、そもそもモデルを作るのに膨大なコストがかるというのが挙げられます。有名な生成モデルであるCPT-4は1兆個を超えるパラメータを持っているそうですが、それらの最適解を見つける (イメージとしては、1兆強の多元連立方程式を解くようなもの) には、膨大な計算リソースが必要であり、とても1ユーザが捻出できる金額ではないと言われています。
そこで、世界各国のAI企業が、自らが集めた膨大なデータを使って学習したモデルを公開しており、それを必要であればそのモデルをすぐにデプロイして利用できるようにしたマネージド型サービスが、基盤モデルになります。
③AWSの基盤モデル
AWSが提供している基盤モデルに関しては、こちらに記載がありますので、参考にしてみてください。
2.構築する生成系AIアプリの構成
まず、構築する生成系AIアプリの構成の以下になります。生成系AIとしては、大規模言語モデル(Large Language Model:LLM)を用いています。
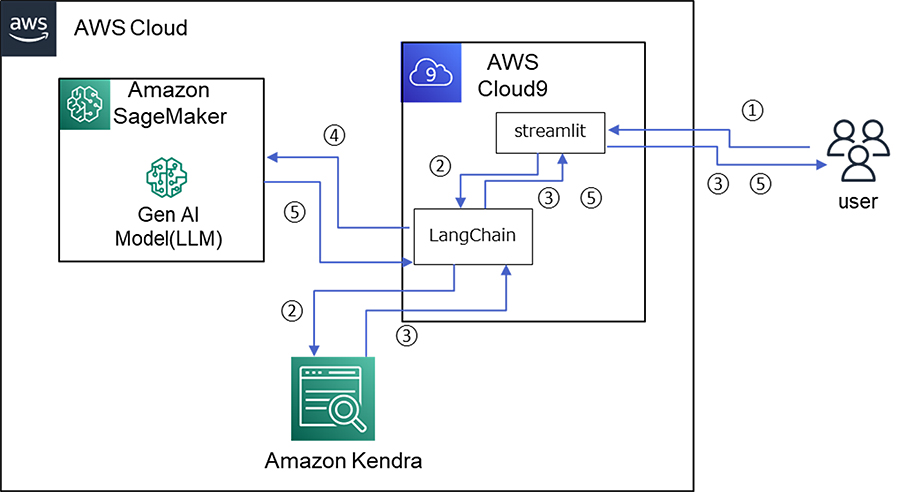
具体的な動作としては、以下になります。
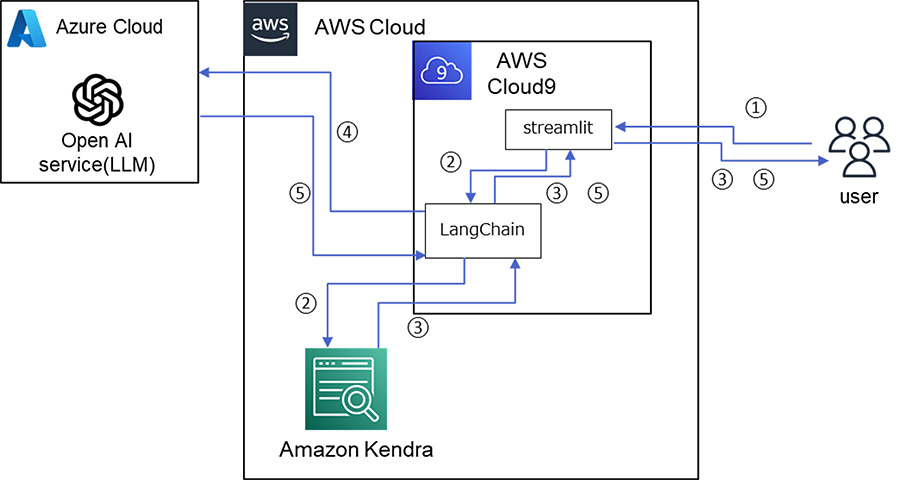
- ① ユーザが質問を入力
- ② Amazon Kendraへの検索を実施
- ③ Amazon Kendraからの検索結果(ドキュメントのリンク)を出力しユーザへ返却
- ④ Amazon Kendraからの検索結果(コンテキスト)を生成系AIモデル(LLM)に対して入力
- ⑤ 生成系AIモデル(LLM)からの結果を出力しユーザへ返却
3.検索拡張生成
ベンダー提供の事前学習済の生成系AIが用いたとしても、そのままでは利用には限界があり、例えば以下のようなものがあります。
- 情報が古い
学習時のデータと利用時にはどうしてもタイムラグが発生するため、生成系AIから戻される結果が、古い情報となることがあります。 - 過剰に類似したアウトプット
利用したモデルが過学習している場合、入力した内容をそのままアウトプットしてくることがあります。 - 回答内容の論理性の欠如
生成系AIは、人間がそうするのとは異なり、入力した内容の意味を理解しているわけではありません(単に、似たような内容を返却しているだけ)。一見、正しそうに見えても論理的に破綻している回答になることがあります。
このような限界に対して、生成系AIを実業務で利用できるようにするために強化してあげる必要があります。これには様々な手法が存在しますが、今回は、タイトルにもある検索拡張生成(Retrieval Augmented Generation:RAG)を使いました。
RAGは、あらかじめ設定した外部情報を信頼性の高い情報源として利用することで、情報が古い場合は補正したり、社内限定用語のような生成系AIで未学習な事項を補完することができます。そして、RAGを実現しているのがAmazon Kendra+LangChainという関係になります。
4.Amazon KendraとLangChain
①Amazon Kendra
RAGにおける外部情報の役割を担います。Amazon Kendraについてはこちらに記載がありますので、参考にしてみてください。
検索拡張生成にAmazon Kendraを用いた生成系AIアプリ~ Amazon Kendra紹介編 ~
②LangChain
RAGにおけるLLMと外部情報との橋渡しをしているライブラリです。詳細は以下のdocsを参考にしてみてください。
5.Amazon Kendra Indexの作成
以降では、こちらの手順のとおりに進めます。
①AWS CloudFormationによる展開

まず、外部情報であるKendraのIndexを作成します。ここで、先ほど示したブログのようにIndexを作成してももちろん構いませんが、今回は、GitHubリポジトリにkendra-docs-index.yamlというファイルが用意されているので、それを使って手間を省きたいと思います。このファイルは、AWS CloudFormationのテンプレートファイルになり、自動的にKendraのセットアップとIndex作成が行われます。
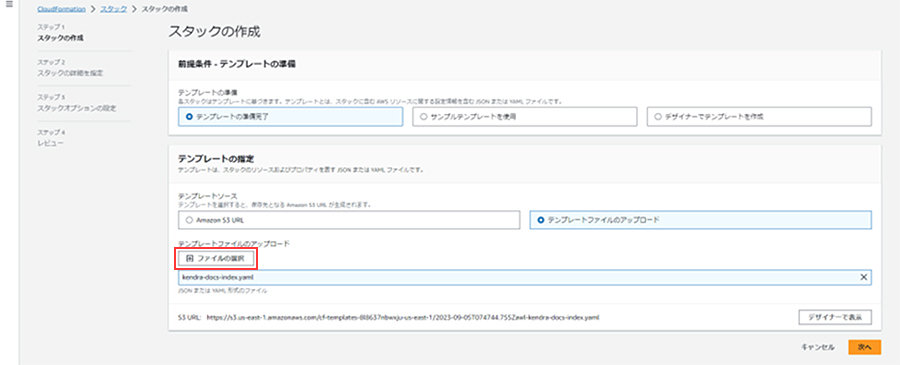
AWS CloudFormationのトップ画面から「スタックの作成」を押下します。次の画面で、kendra-docs-index.yaml をセットします。
次の画面でスタック名を入力(任意の名前)します。以降についてはそのままデフォルトで構いません。最後の画面で「送信」を押下すると処理が走り出します。
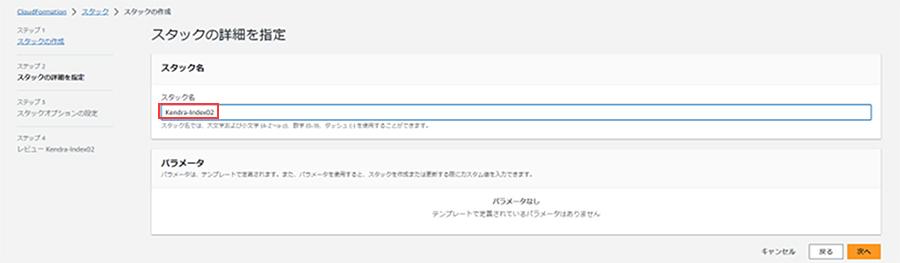
完了すると、ステータスがCREATE_COMPLETEとなります。
②Amazon KendraのIndex作成結果確認
実際にAmazon Kendraで確認すると、Index作成されています。なお、後ほどIndex IDが必要になりますので、把握しておいてください。
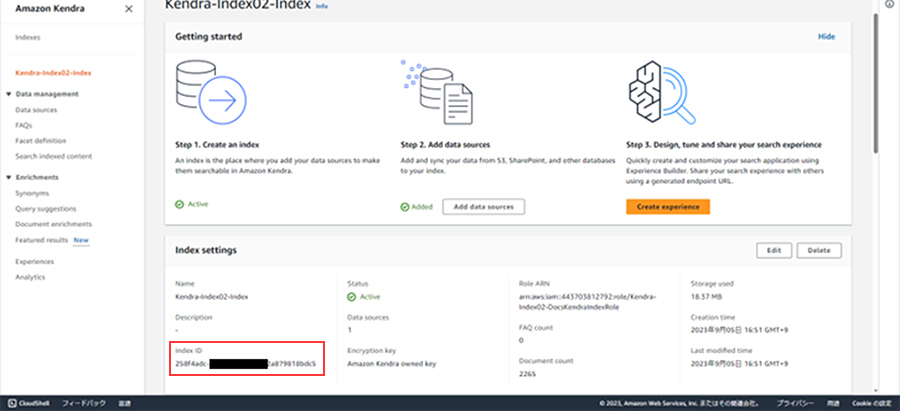
AWS CloudFormationによって、Amazon Kendraでどのような外部情報が作られたのか確認します。サイトマップXMLが指定されています。
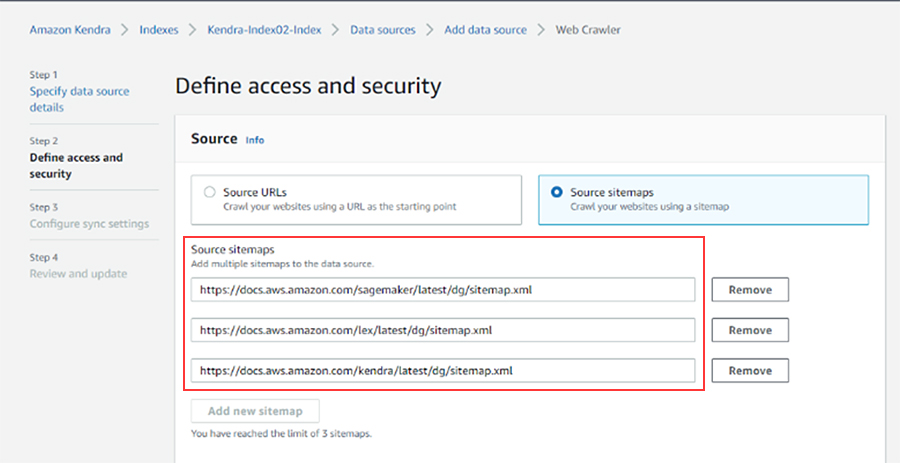
https://docs.aws.amazon.com/lex/latest/dg/sitemap.xml
https://docs.aws.amazon.com/kendra/latest/dg/sitemap.xml
https://docs.aws.amazon.com/sagemaker/latest/dg/sitemap.xml
実際にサイトマップXMLを開いてみると、Amazon Lex、Amazon Kendra、Amazon SageMakerの開発者ガイドであることがわかります。
6.生成系AIアプリの構築
次に、生成系AIアプリを構築します。先ほどのGitHubリポジトリのREADME.mdにインストール手順がありますので、その通りに進めます。
①AWS Cloud9のセットアップ
実行環境としては、EC2から構築しても問題ないですが、セットアップの手間を省くためにAWS Cloud9から構築していきます。セットアップは非常に簡単で、環境の名前だけ入力してあとはデフォルトのままで問題ありません。
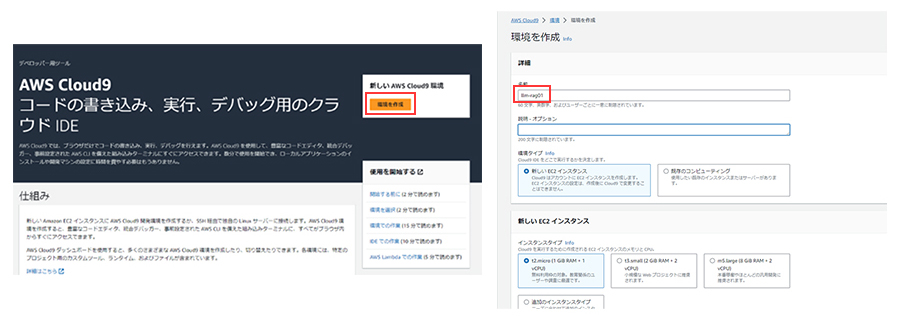
しばらくすると、環境が起動してきます。
②Python3.9へのアップデート
手順通りに進めると、Python3.9以降が必要とのエラー出力されます。そのため、AWS Cloud9環境のPythonのバージョンを3.9以降にアップデートする必要があります。実際の手順は省略させて頂きますが、以下を参考にして実施しました。
Upgrade to python > 3.9 on Cloud 9 | AWS re:Post (repost.aws)
結果的にPython3.9にアップデートできました。

③アプリ構築
改めて手順通りに進めます。pip install -r requirements.txt を実行することで、LangChainやその他アプリ構築に必要なパッケージがインストールされます。

【補足】ブラウザ経由での接続方法
このアプリはstreamlitで起動します。構築しているAWS Cloud9は、デフォルトではインバウンドルールは設定されておらず、外部からのすべての通信が拒否の状態です。そのため、ブラウザから接続して利用するには、何らかの対処が必要です。
1つの方法としては、AWS Cloud9の環境に対してstreamlitが使用するポート番号TCP:8501のみを接続許可するインバウンドルールを作成します。作成後、セキュリティグループを構築したAWS Cloud9の環境にアタッチします。
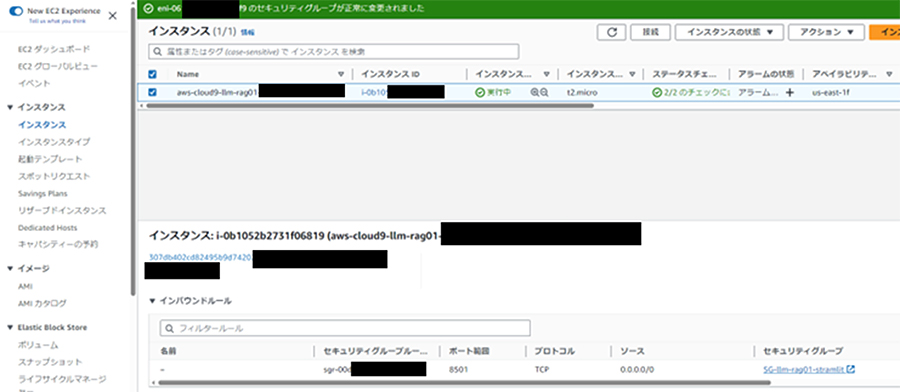
この方法は1つの例であり、また、検証用の簡易的な手順であるためセキュリティ的な配慮はできておりません。実施する場合にはセキュリティ的に十分に注意し、自己の責任で実施してください。
④動作確認
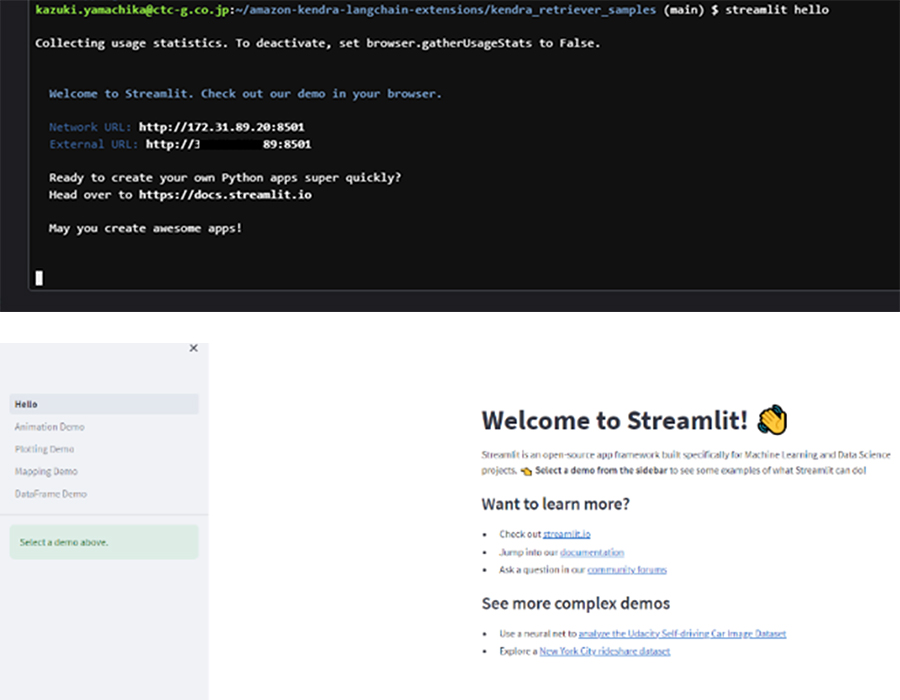
ここまでの動作確認をします。以下の起動コマンドを実行すると、接続URLが表示されます。
$ streamlit hello
表示されたURLにPC等のブラウザから接続してすると、StreamlitのWelcome画面が表示されます。
7.SageMaker JumpStartによる基盤モデルのデプロイ
①基盤モデルの選択とデプロイ
生成系AI(LLM)を展開するため、Amazon SageMakerから基盤モデルを選択していきます。
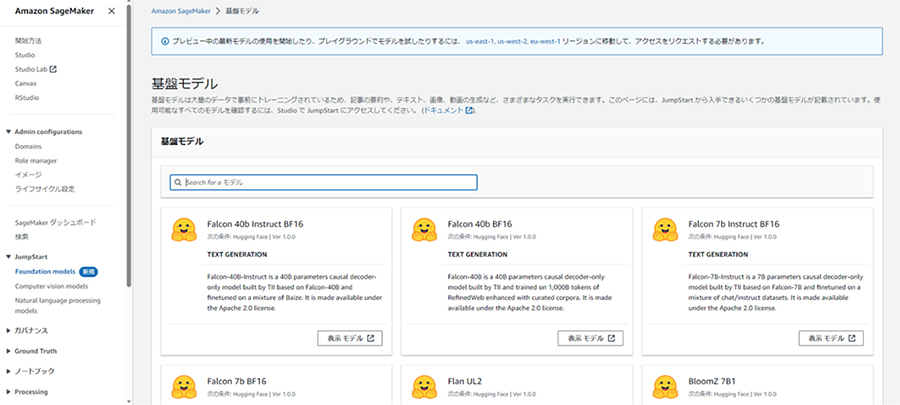
「1.生成系AIと基盤モデルの重要性」に記載したリンク先のブログでも述べられておりますが、SageMakerにある基盤モデルはSageMaker JumpStartからデプロイすることが可能です。今回はHugging Faceが提供している「Flan-T5 XL」を使ってみます。
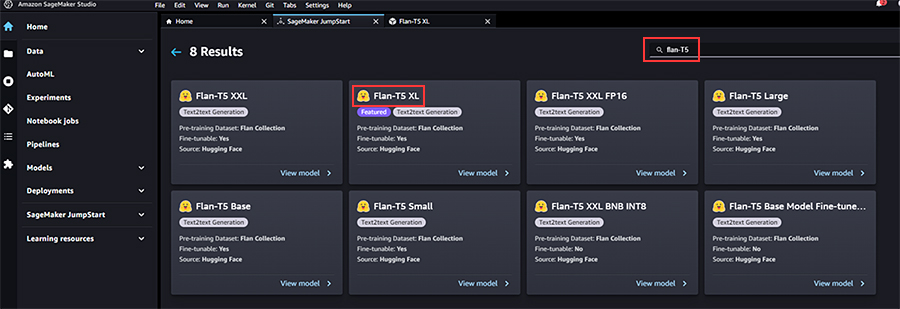
実際には、ファインチューニング等でプログラムの改修を実施していくこともあるかと思いますが、今回は、公開されている基盤モデルをそのままデプロイします。
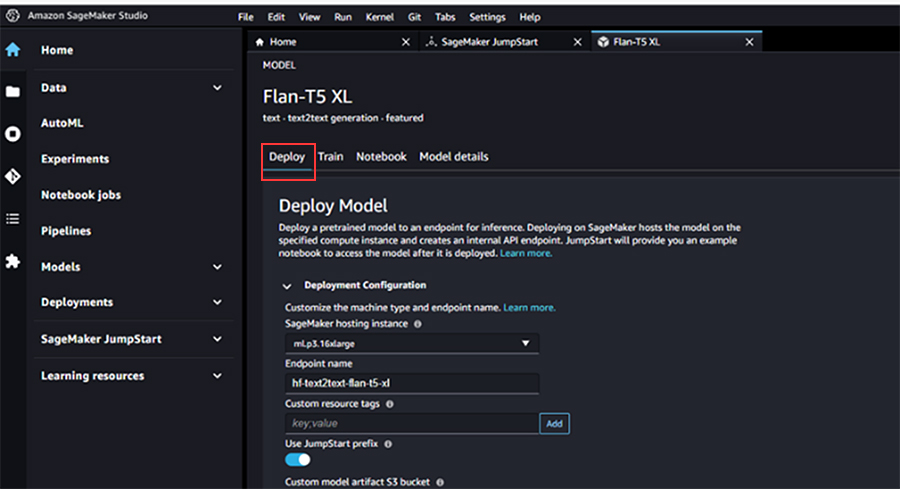
②Service Quotasによる制限緩和
生成系AIで使われるDeeplearningアルゴリズムは、大量のパラメータをその途中経過をメモリ内に保持しながら計算しなければなりません。そのため、単に応答速度の早い/遅いというよりも、計算過程のメモリオーバーフローでエラーとなってしまうことを回避するために、デプロイするインスタンスはできるだけ高性能なものを選択することをお勧めします。
今回は、Flan-T5 XLで選択できる中で最も高性能な「ml.p3.16xlarge」を選択しました。ただし、そのような高性能なインスタンスは利用が制限されている場合があります。その場合にはService Quotasから、そのリージョンにおけるAmazon SageMakerの「ml.p3.16xlarge for endpoint usage」に関するクォータを確認し、必要に応じて上限値の変更申請を実施してください。
※権限によっては実施できない場合もありますので、その場合は各アカウント管理者にご確認ください。
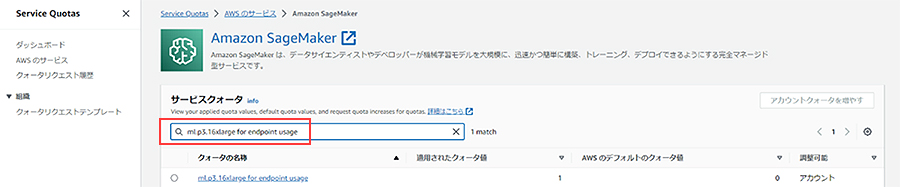
③デプロイの確認
デプロイ実施後しばらくするとエンドポイントがInServiceになります。エンドポイント名は後ほど使用しますので、控えておいてください。

以上で、構築はすべて完了です。
8.生成系AIアプリの実行
①アプリの起動
手順に戻り、AWS Cloud9で環境変数のexportを行ってください。設定するのは、AWSリージョン、KendraのIndex ID、デプロイした基盤モデルのエンドポイント名です。
export AWS_REGION=ap-northeast-1
export KENDRA_INDEX_ID=258f4adc-a909-xxx-xxxx-2a879818bdc5
export FLAN_XL_ENDPOINT=jumpstart-dft-hf-text2text-flan-t5-xl
アプリを起動してみます。手順のように、streamlitに引数を入れて実行します。
$ streamlit run app.py flanxl

そして表示されたURLにブラウザで接続してみると、構築した生成系AIアプリに接続できました。
②動作確認
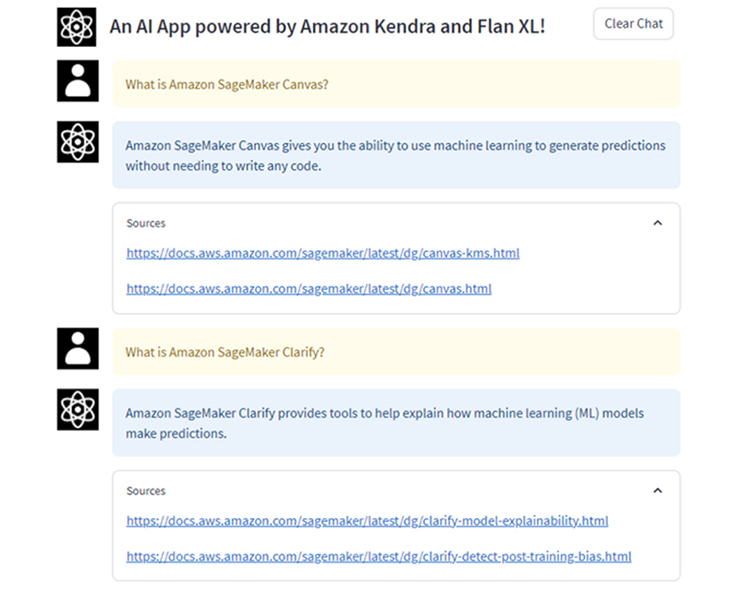
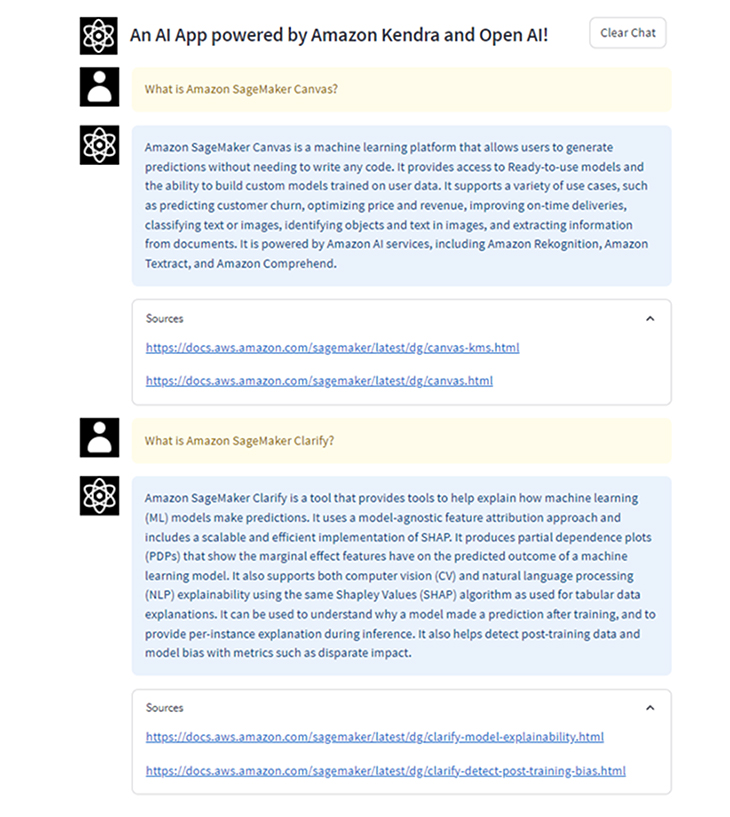
実際に動作確認してみます。まず、以下の2つの質問を実施します。
What is Amazon SageMaker Canvas?
What is Amazon SageMaker Clarify?
良さそうな回答が返ってきており、ソースのURLが表示されます。
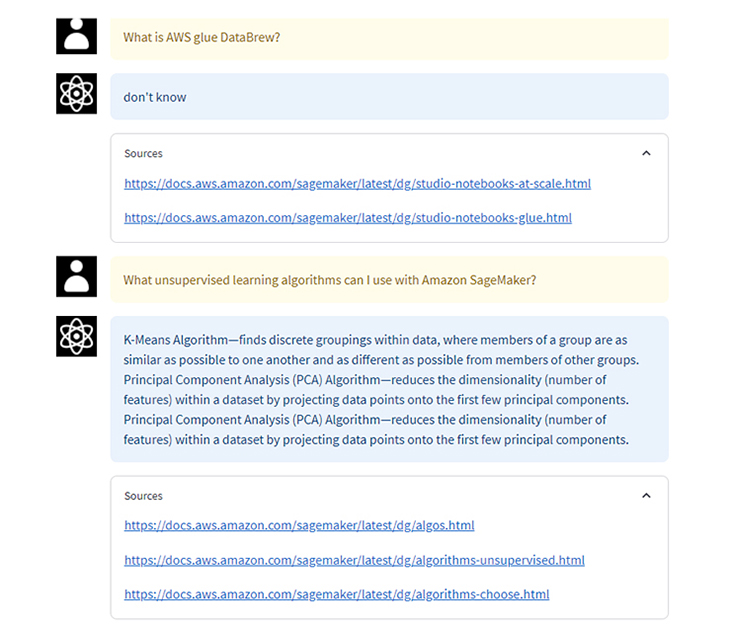
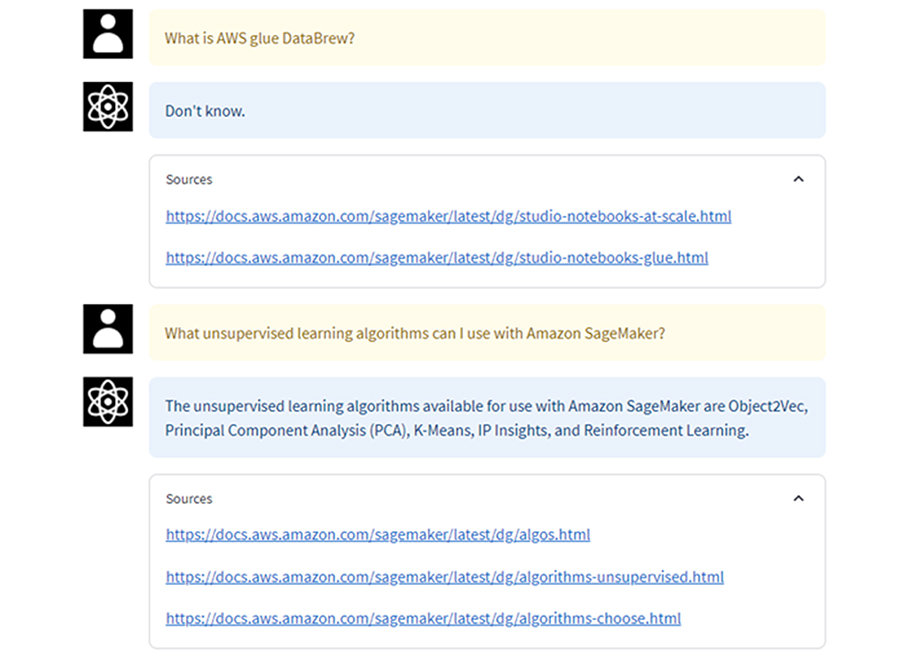
次に、作成したAmazon KendraのIndexにはソースとして存在しないと思われる質問や複雑な質問も実施してみます。
What is AWS glue DataBrew?
What unsupervised learning algorithms can I use with Amazon SageMaker?
わからないとの回答が返ってきたり、中途半端な回答が返ってきました。ただ、参照ソースのURLは正しいそうなので、Amazon Kendraの検索は正しく動いています。
9.Open AIのAPIを使う場合
①アーキテクチャ
SageMakerの基盤モデルを使う以外にも、Open AIが公開しているAPIに接続して、その結果を使う方法もあります。その場合のアーキテクチャは以下のようになります。
②OpenAI API Keyの取得
OpenAIのAPIを利用する場合には、別途、契約等が必要です。必要に応じて、各自でこちらから実施してみてください。
③アプリの起動
手続きが終わると、API Keyが発行されます。そのKeyをAWS Cloud9で環境変数に設定して、streamlitで引数を変更して起動してください。
export OPENAI_API_KEY=XXXXXXXXZ3YgXXXXXXXkFJwBbk4End8NUT2ocCfuoi
※内容は加工してあります。
$ streamlit run app.py openai
起動した画面のタイトルが、「・・・Amazon Kendra and Open AI!」に変更されたことがわかります。

④動作確認
この内容で同じ質問を投げかけてみます。動作結果は以下にようになり、先ほどの基盤モデルでの結果と異なっているのが分かります。
⑤結果比較
Open AIのAPIを利用した場合の方が、意図した回答内容になっているように見えます。ただ、実際には基盤モデルを何のチューニングもせずにそのまま使うということはなく、利用する要件に沿ってファインチューニングをすることで、基盤モデルを活用する方が求めている要件に近づく可能性は十分に考えられます。
コストに関してはどちらも従量課金ですが、少し異なります。Open AIのAPIは入力に対して返却されるテキスト量に応じた課金となり、また、AWS基盤モデルに関してはエンドポイントを起動している時間に応じた課金となります。一概にどちらが高い/安いとは言えません。
10.まとめ
アプリ構築から動作確認まで実施してきましたが、これですべての種類の生成系AIアプリ構築が作れるわけでは決してありません。ただ、このような簡易なアプリ構築を通じていろいろ試行錯誤することで、生成系AIとその周辺知識に関する理解が深まるはずです。是非、試してみてください。
なお、AWSにおける基盤モデルについてはAmazon Bedrockというサービスが発表されており、おそらく、こちらを使った完全なマネージド型サービスが拡充していくと予測されます。
基盤モデル API サービス – Amazon Bedrock – AWS
動作検証等ができましたら、改めて、続報を記載していきたいと思います。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。

クラウドエコシステム100 for AWS
ビジネス要求の高い機能を「すぐに使える」 ソリューションパッケージとしてご提供します!
-

基幹システム
移行 -

遠隔地
バックアップ -

災害対策(DR)
-

セキュリティ
-

リモートワーク
-

デジタル
マーケティング -

コンタクト
センター -

マルチCDN
-

コスト管理
-

統合システム
運用管理

