【Amazon Bedrock】Amazon Titanと日本語でチャットしたい
~微調整編~
投稿日: 2024/03/11
はじめに
こんにちは、佐々木です。
前回のコラムでは、Amazon Bedrock基盤モデルのカスタマイズ方法のうち、「継続的な事前トレーニング」について扱いました。
今回は、前回に続いてもう1つのカスタマイズ方法である「微調整」について紹介いたします。
前回はこちら: 【Amazon Bedrock】Amazon Titanと日本語でチャットしたい!~継続的な事前トレーニング編~
*本コラムの内容は、2024年2月時点の情報を基に作成しています。最新情報はAWSのWebページよりご確認ください。
*生成AIモデルを利用する際の入出力データの取り扱いは、AWSサービス利用規約、モデル開発元規約や自社ルールを遵守し、細心の注意をお願いします。
カスタマイズ方針
Titan Text G1 – Liteを以下の2段階でトレーニングすることにより、最終的に「日本語の質問に日本語で回答できる状態」を目指します。
- ① 継続的な事前トレーニングを実施して、自然な日本語出力ができるようにする
- ② ①で作成したモデルをファインチューニングして、質問に回答できるようにする
ここからは、②を実現するための方法を紹介します。前回とは異なり、回答の正確さについても検証対象になります。
手順
②-1: データ準備
今回は、databricks-dolly-15k-jaというデータセットを利用します。このデータセットは、Databricks社が公開しているdatabricks-dolly-15kという大規模言語モデルのチューニング用データセットを日本語訳したもので、8つのタスクカテゴリ(Creative Writing, Closed QA, Open QA, Summarization, Information Extraction, Classification, Brainstorming, General QA)に関する計約15,000件のレコードを持っています。
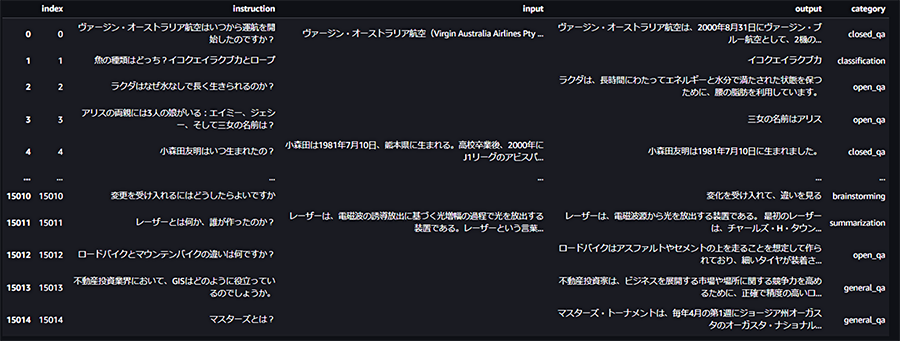
databricks-dolly-15k-jaデータセットをダウンロードした状態(タスクカテゴリは“category”列)
Amazon Bedrockで微調整を実施する場合、学習データには以下のルールがあります。継続的な事前トレーニングとはルールが異なる点に注意が必要です。
- 1つのJSONLファイルで、各JSONレコードは”prompt”フィールドおよび”completion”フィールドを持つ
- トレーニング1回あたりのレコード数上限:10,000
- (オプション) トレーニング1回あたりの検証データのレコード数上限:1,000
- 1レコードあたりの合計トークン数上限:4,096
そこで、以下のi~ivの処理を実施することで、微調整の学習データとして使える状態にします。(実装コードは割愛します。)
-
i. ダウンロードしたデータのinput列に文章が入っていない(タスクカテゴリがClassification, Brainstorming, Creative Writing, Open QA, General QA)レコードの場合は、promptフィールドはinstruction列の文章、completionフィールドはoutput列の文章とする。
-
ii. input列に文章が入っている(タスクカテゴリがClosed QA, Information Extraction, Summarization)レコードの場合は、以下の図に示すように、promptフィールドは”入力:〈instruction列の文章〉¥n知識:〈completion列の文章〉”、 completionフィールドはoutput列の文章とする。
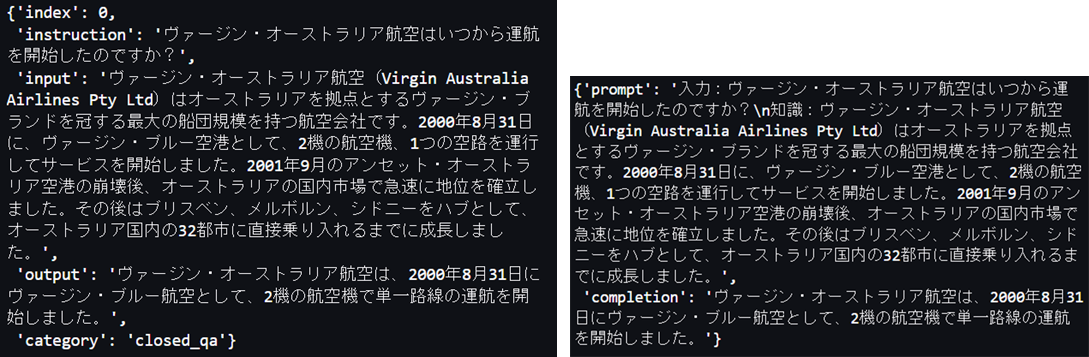
元のレコード(左)とiiの処理後のレコード(右)
-
iii. promptおよびcompletionの合計文字数が1,500文字以内のレコードを抽出する。(※前回と同様に先頭1,500文字にしてしまうと、プロンプト入力または回答が途切れた状態のデータを学習している状態になる可能性があるため、今回は除去しました。)
-
iv. iiiの抽出結果から、トレーニングデータセットとして10,000件、検証データセットとして1,000件分のレコードを抽出する。ここで、トレーニングデータセットと検証データセットに含まれるレコードは重複させない。
(例)

作成したJSONLファイルは任意のS3バケットにそれぞれアップロードします。
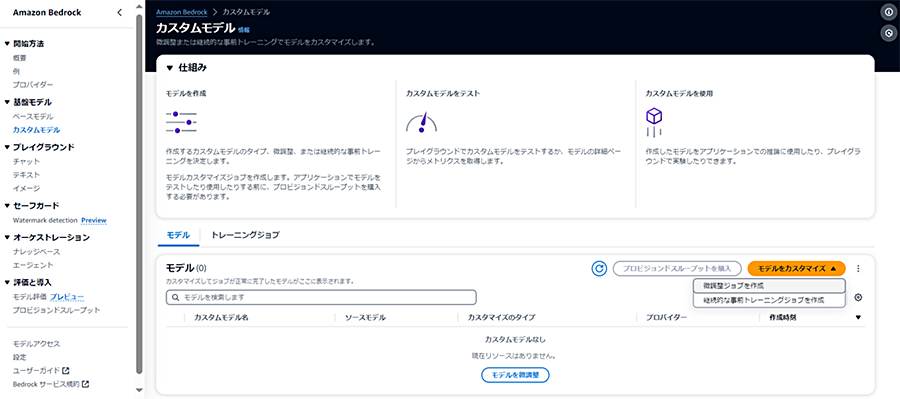
②-2: トレーニング
微調整の場合も、管理コンソールから、コーディングをすることなくAmazon Bedrockの基盤モデルをトレーニングすることができます。
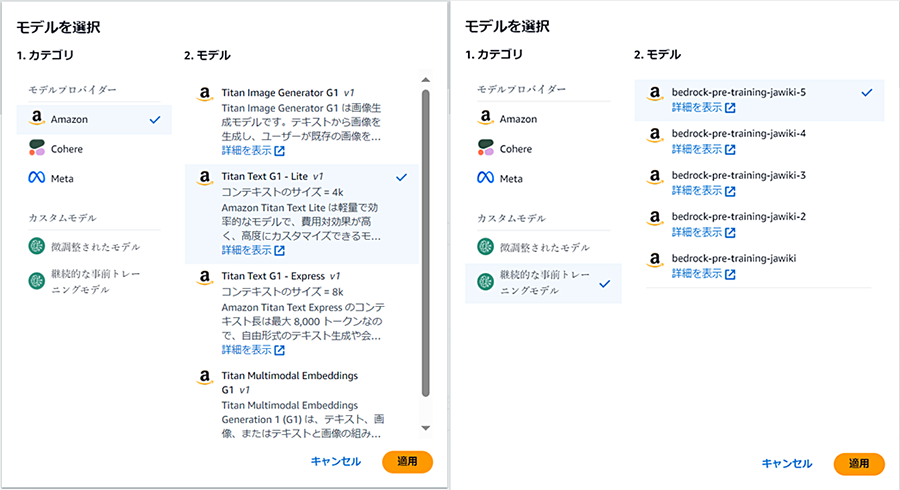
モデルはAmazon Bedrock Titanの他に、CohereのCommand, Command Light, MetaのLlama 2 13B, Llama 2 70Bが微調整に対応しています。また、すでにカスタマイズしたモデルがある場合は、それらも選択可能です。
選択したモデルによってハイパーパラメータで設定できる項目および値の範囲が異なります。本コラムの例では、Amazon Bedrock TitanまたはAmazon Bedrock Titanをカスタマイズしたモデルを選択した場合の画面です。検証データはオプションのため、データを準備していない場合は指定せずトレーニング開始します。
(例)
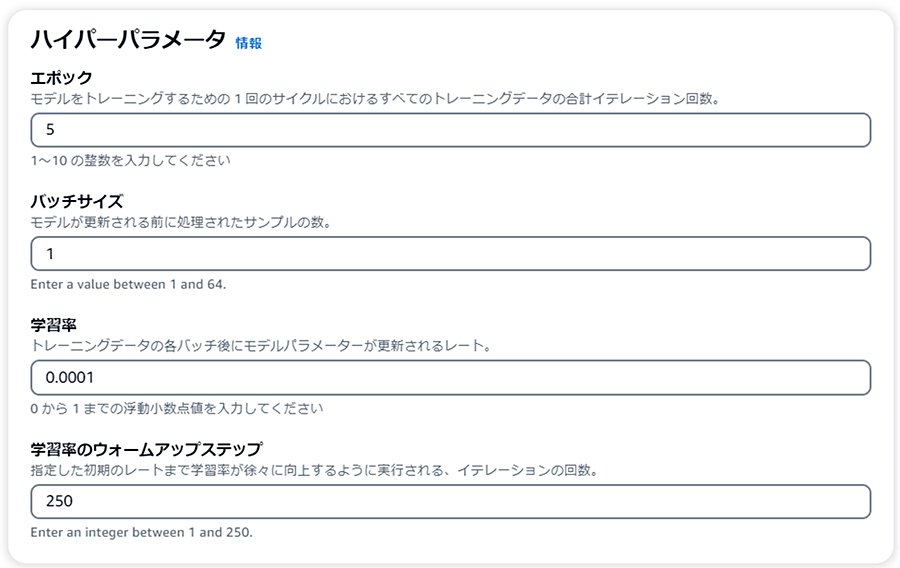
トレーニング料金は、選択したモデルおよびトレーニングされたトークンの総数によって決まります。Amazon Bedrock Titan/ Cohere Commandの場合は「トレーニングされたトークンの総数 = トレーニングデータコーパス内のトークン数 × エポック数」との記載があり、ハイパーパラメータの「エポック」に比例するため設定時には注意しましょう。(本コラム作成時点ではMeta Llama2の場合は明記されていませんが、想定外の請求を避けるため、同様と考えておく方が良いと考えます。)
https://aws.amazon.com/jp/bedrock/pricing/
トレーニングが完了すると、モデルの一覧に追加されます。
トレーニング開始から完了までにかかった時間は、ハイパーパラメータを上記の例通りに設定した場合で7時間程度、エポック数1の場合では2時間程度でした。
※ただし、ハイパーパラメータの値を画面の指示通りに設定しても、トレーニング開始後にエラーが出る事象を確認しています。その場合は、エラーメッセージの内容に従って、新規にトレーニングジョブを再作成する必要があります。
(例)

Amazon Bedrock Titan Text Liteでバッチサイズを64(画面で設定できる値の範囲内)に設定してトレーニング開始した場合のエラー画面
②-3:プロビジョンドスループットの購入
トレーニングしたモデルはオンデマンド利用に対応していないため、プロビジョンドスループットを購入する必要があります。
手順は前回コラム(継続的な事前トレーニング)の場合と同様のため割愛します。
※料金は選択したモデル、モデルユニット、契約期間によって異なります。
②-4:推論
計4通り(エポック数2通りおよび継続的な事前トレーニングの実施有無)の微調整したモデルに対して、それぞれ推論して生成された文章を比較します。
※入力プロンプトは、同じ内容がトレーニングおよび検証データセットのpromptフィールドには含まれていないことを確認しています。
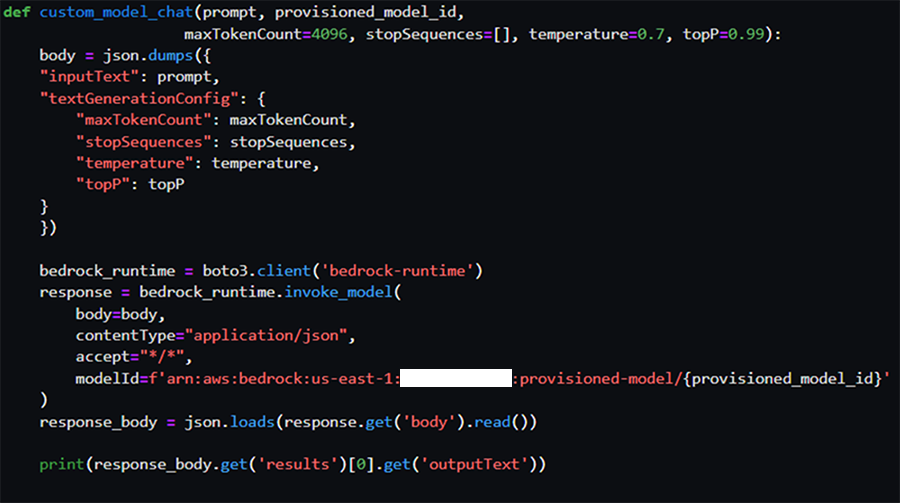
今回は結果確認用の関数custom_model_chatを実装しています。(ただし、コードの一部をマスキングまたは割愛しています。)
②-4-1:微調整のみ
まずは、Amazon Bedrock Titan Text Liteを微調整したモデルに対して、前回と同じプロンプト文章を入力した場合の推論結果です。

Open QAタスクの推論結果:エポック数1の場合(左)と5の場合(右)
何度か推論するとハルシネーションが起きることもありますが、エポック数を増やしたことによって正しく回答できる回数が増えました。
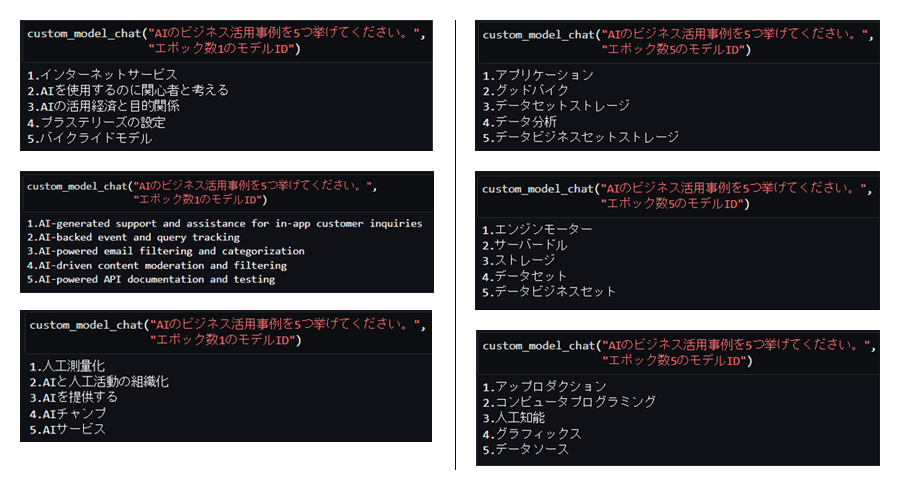
Brainstormingタスクの推論結果:エポック数1の場合(左)と5の場合(右)
5つ挙げる、という点はどちらもできていますが、トレーニングした総レコード数が少ないためか、エポック数5でトレーニングしたモデルではそもそも日本語が生成されない、という事象が発生しました。
また、回答の正確性については、エポック数5でトレーニングしたモデルでも不十分に感じます。
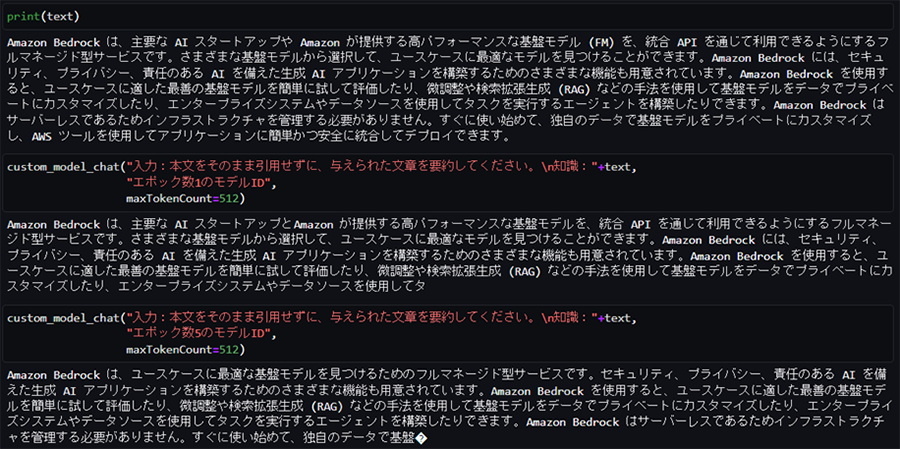
文章要約タスクの場合は、データセット準備(②-1の手順ii)に記載の通りのプロンプトでなければ全く違う意味の(かつ支離滅裂気味の)テキストが生成されました。

要約したい文章(出典:https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/what-is-bedrock.html)

Summarizationタスクの推論結果:エポック数1の場合(左)と5の場合(右)
②-4-2:継続的な事前トレーニング+微調整
次に、Amazon Bedrock Titan Text Liteを継続的な事前トレーニングさせた後に、微調整をした場合のモデルです。今回使用する事前トレーニング後のモデルは前回のコラムで作成したモデルではなく、さらに追加で400,000レコード(前回のコラムと合わせて計5回、計500,000レコード)を事前トレーニングさせたモデルに対して微調整したモデルです。
※事前トレーニングの各回のエポックは1に設定しています。

Open QA形式の推論結果:エポック数1の場合(左)と5の場合(右)
継続的な事前トレーニングではWikipediaの記事データを利用していたためか、単純な質問であっても長いテキストを生成しようとしているようです。(都合上、上図では生成されたテキストの一部をトリミングしています。)
そのため、以後は生成するトークン数の上限を設定するパラメータmaxTokenCountの値を適宜制限して推論します。

Brainstormingタスクの推論結果:エポック数1の場合(左)と5の場合(右)
微調整のみ(②-4-1)の場合と比べると具体性が上がっているようには見えますが、まだ正確であるとは言えません。また、微調整のみの場合では生じなかった事象として、5つ挙げることができていない回答が散見されました。
要約タスクにおいては、プロンプトが同じであれば、(トークン数の制限により文章が途切れていることを除けば、)微調整のみの場合の結果と大きな違いは生じませんでした。
Summarizationタスクの推論結果
結果まとめ
Amazon Bedrock基盤モデル(Amazon Titan Text Lite)の微調整を実施することによって、同モデルの継続的な事前トレーニングを実施した場合よりもチャットらしいテキストが生成されるようになりました。微調整では一回あたりのトレーニングデータが10,000件までと少ないため、トレーニング後でも英文が生成されることがありましたが、エポック数を増やしたり、継続的な事前トレーニングを実施しておくことで解決できました。
また、継続的な事前トレーニングを実施したうえで微調整を行った場合、微調整のみを実施するよりも具体性のある回答が生成されましたが、事前トレーニングの学習データの影響を受けたためか、必要以上の長文が生成されたり、指定した通りでない形式の文章が生成される、という事象が発生することがありました。
さいごに
2回にわたって、Amazon Bedrock基盤モデルのトレーニング方法および手順を紹介しました。これらの内容が、自社業務に生成AIモデルを活用する場合に、精度向上の手段としてモデルをトレーニングすることが本当に有効なのか、また、データ準備やトレーニングのコストに見合うのかを見極めるヒントになれば幸いです。
AWSでの生成AI活用に関するアイデアやご相談は、お気軽にCTCまでお寄せください。
CTCは、AWSのビジネス利活用に向けて、お客様のステージに合わせた幅広い構築・運用支援サービスを提供しています。
経験豊富なエンジニアが、ワンストップかつ柔軟にご支援します。
ぜひ、お気軽にお問い合わせください。


