コラム:経営に役立つクラウド活用
データ駆動経営を支えるITシステム
デジタル技術の発展に伴い、企業内に蓄積された様々なデータを分析し、意思決定やアクションにつなげていく「データ駆動経営」に各社が注目している。その実現のためには、社内のさまざまな部門で担当者がデータをすぐに活用できる仕組みが必要不可欠になってくる。こうした環境を整えるためには何が必要なのだろうか。Google™のクラウドサービス「Google Cloud Platform™」を使った構成例も含めて解説する。
はじめに
「競争を勝ち抜くためのデータ駆動ビジネス」、「21世紀の石油はデータ」などの言葉をビジネス誌などでよく見るようになった。これらの言葉に共通するテーマは、「データ」を「活用」することだが、その仕組みをどれだけ具体的にイメージできるだろうか。データ活用という言葉があまりにも広い範囲に使われ、ほとんどの人が「なんとなく理解しているが、特定の業界の話ではないか」「マーケティング主導のバズワードではないか」という認識ではないだろうか。
「データ」を「活用」するということ
データを活用するには大きく分けて2つのアプローチがある。旧来の「目標達成型」アプローチと「データ駆動型」アプローチだ。「目標達成型」アプローチは、目的を明確にして厳密に要件を定義した上でデータを取集し、要件に最適化した蓄積・分析のためのシステムを導入する、すでにどの企業も実施している馴染みの深いアプローチだ。DWH(データウェアハウス)が代表的な仕組みだ。
一方、「データ駆動型」はテクノロジの進化で取れるようになった新しいアプローチだ。「データ駆動型」アプローチではデータから得られた知見からアクションを起こす。「目標達成型」アプローチで要件に必要ないからと捨てていたデータや、IoTデータのような単純だが大量の生データを丸ごと保存しておき、知見を得るための材料とする。データ駆動型におけるデータ利用者は蓄積された膨大な生データから、必要なデータを自由に選び出し、整形したうえでデータを組み合わせて統計的分析を行う。分析の結果導き出された予測は、現実の企業活動に直接反映される。そしてその活動の結果もまた測定され、新たなデータとしてフィードバックされる。例えばWebサービス企業ではユーザのマウスクリック、ページの滞在時間などの膨大なデータを記録し、サービスの改善に役立てている。ほかにも建設機械に、車両の状態や稼働状況をチェックするセンサーやGPS装置が取り付けられ、各車両のデータを通信衛星回線や携帯電話回線を通じてサーバに自動的に送信集積し、保守に役立てる例もある。
「データ駆動型」アプローチによって実現する社会は、経産省が発表したデータ駆動型社会の在り方についての報告が参考になる。ここでCPS(Cyber Physical System)という用語がある。実世界(Physical)とサイバー空間(Cyber)との相互連関(System)が、社会のあらゆる領域に実装され、さまざまなデータを収集し、そのデータを解析し、現実世界へフィードバックしていくサイクルは大きな社会的価値を生み出していくとしている。
Figure 1 社会全体がCPSにより変革される「データ駆動型社会」
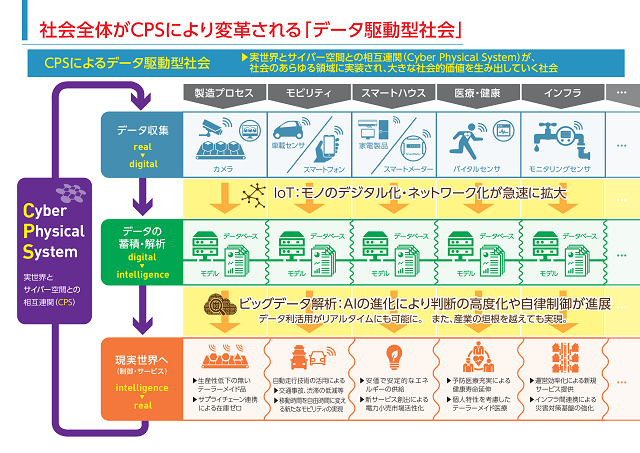
出展:情報経済小委員会 中間取りまとめ(経済産業省)
http://www.meti.go.jp/shingikai/sankoshin/shomu_ryutsu/joho_keizai/pdf/report01_02_00.pdf
データレイクは多種多様なデータの保存場所
「データ駆動型」を実現するための前提として、解析者が多種類かつ大量のデータに自由にアクセスできる必要がある。その実現方法はどのようなものになるだろうか。その答えはデータレイクというデータを蓄積する基盤(プラットフォーム)を整備することだ。比較的価値が明確な構造化データを蓄積するDWHと異なり、構造化データに加え構造化されていない画像やログデータ、長期にわたるセンサーデータ、ユーザの操作データなどを、加工することなく保存できる大容量ファイルストレージがデータレイクだ。データレイクは、あらかじめ使用するデータセットが限定されていたDWHに対し、データ利用者が自由に分析するデータを選べる環境を提供している点が大きな違いといえる。さまざまなデータソースから、川のようにデータが流れ出し、データレイクに注ぎ込むイメージだ。
データレイク環境の構成
データレイク環境の構成は、大きく4つのコンポーネントに分けられる。
- データを作り出すデータソース
- データを保存するデータレイク
- データを整形加工するETLツール
- データを分析するDWH
の4つだ。
Figure 2 データレイク環境に必要なコンポーネント
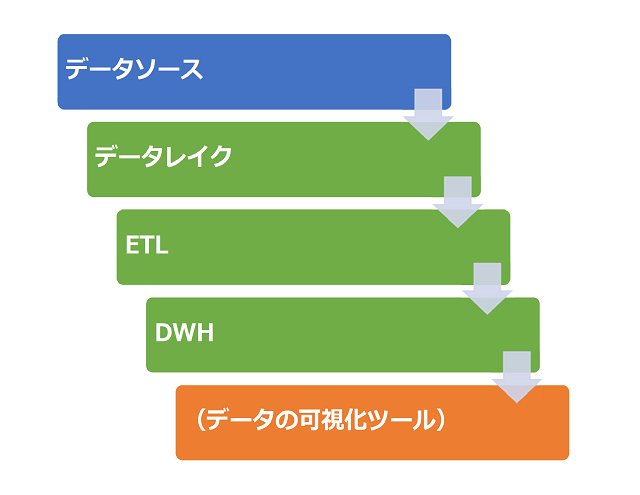
データソースは、ロギングデータやセンサーからの測定値に相当する。ここで発生したデータは恣意的な加工を行わず、生データが望ましい。生データを分析する際の整形加工は、後述のETLツールで行う。
データレイクは生データの保存を行う。一般にフォルダ等で階層化したオブジェクトストレージで構成する場合が多い。もちろん、野放図にデータを保存すればデータレイク(湖)もゴミであふれた沼になってしまう。それを防ぐためにフォルダの分割方法、ファイル内容のメタ情報、ファイル命名規則など、一定の規則は必要だ。
ETLツールは、分析に使用する生データを選択し、DWHで利用可能な形へ生データを整形し、最終的にDWHへ投入を行う。データ利用者は用途に合わせてETLツールで生データを選び、整形加工しDWHに投入して利用することが可能だ。データ利用者はETLツールの画面を通じてデータレイクを扱うため、操作性が重要になる。例えば、データ利用者が容易にデータレイクにあるデータ種類のインデックスを検索し、加工のためのちょっとしたスクリプトを簡単に書ける必要がある。
DWHは、SQLなどの検索式で検索可能な巨大データベースだ。大規模なデータセットを登録可能なストレージ、大量のデータを分散処理で高速に処理できる処理能力、それらがリーズナブルな価格で利用可能なことが必要だ。
このようなデータレイク環境だが、ハードウェアを購入し、オンプレミスで構築するよりも、クラウドサービスで構築することがお勧めだ。なぜならデータレイクの機能上の必然として、ストレージに保存するデータは増えこそすれども、減ることはないからだ。クラウドサービスはスケールアウトすることが機能に盛り込まれているため、規模の小さなデータからスモールスタートして、データ量の増加に合わせてスケールアップしていくことが可能だ。弊社で取り扱っているGoogle Cloud Platform(以下、GCP™)はGoogleの提供しているパブリッククラウドサービスだが、データレイク環境の構築に最適なので紹介する。GCPは限られたリソースでも、高度なセキュリティとスケーラビリティを備えたインフラストラクチャ上で、アプリケーションのスピーディーな開発と安価なコストでの運用が実現できる。ここでGCPのサービスの一つのBigQuery™を紹介する。
BigQueryは
- SQL等の検索式で検索可能
- 分散処理で通常のデータベースが処理できないような規模のデータを高速検索できる
- スキャンしたデータ総量で課金される
- オートスケールし、インフラを意識しないで利用が可能
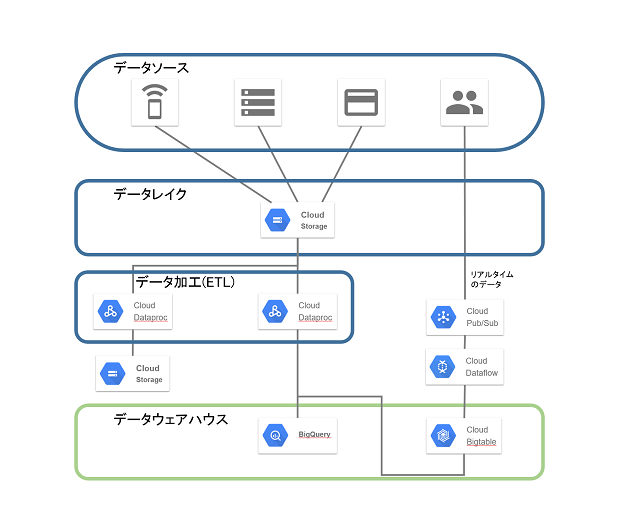
といった特色があり、ユーザーからの評価が高い。 そのBigQueryを中心にデータレイク環境を構築した場合の構成例を以下に示す。
Figure 3 GCPを使ったデータレイクの構成例
人の知恵を活用する
データ駆動経営は、簡単に言えば、企業内の様々なデータを活用しCPSで解析し改善サイクルを回せば、生産性向上の正のフィードバックで大変儲かります、ということ。その前提としてデータレイクに大量のデータを保存し、自由にデータを取り出せる環境が必要で、その各要素がクラウドのインフラにより実現可能なのはここまでで説明してきた。
では取り出したデータを活用するには何をすればいいのだろうか。
具体的には、データの分析を専門とするデータサイエンティストと業務知識を持った人間との共同作業により、膨大なデータから有用な情報の組み合わせを見つけ出し、因果関係のモデルを見出す。そして現実のビジネスに反映させるためのシステム化に進むことになる。
ここで因果関係の発見が重要だが、さまざまな統計的分析手法をデータに適用するアプリケーションは各社から提供されているが、「説明変数」という事象を変化させる因果関係の主要因を確実に言い当てることはできない。相関関係があることは、データ同士がお互いに連動していることから説明できるが、それが必ずしも因果関係を持つというわけではないからだ。例えば、あるショップで、訪問回数と訪問当たりの購入額をグラフにしてみると、訪問回数が増えるほど購入額が増えていた。この場合、訪問回数と購入額には相関関係が見出せる。だが、訪問回数を単純に増やすことが購入額を増やす因果関係であると単純に言えるのだろうか。仕入れが優秀で、魅力的な商品の取り扱いを増やした結果、購入額が増加した可能性もあり、因果関係がない場合も考えられる。
ではどうやって正しい因果関係を見つけるのか。現実的には人間の経験や知恵を活かして説明変数による因果関係の仮説を実際の環境で試し、その変化をデータで確認することで因果関係を特定する。様々なデータを使った試行錯誤と、システム化した後の改善にデータレイクは役に立つだろう。
このことからわかるようにデータと人間の知恵の両輪があって初めてデータの活用が可能となり、データ駆動経営が実現できる。まずはGCPでデータレイクをスモールスタートして、データと人間の知恵が織りなす可能性を試してみてほしい。
参考資料
平成29年度我が国におけるデータ駆動型社会に係る基盤整備
実世界とサイバー空間との相互連関(Cyber Physical System)が、社会のあらゆる領域に実装され、大きな社会的価値を生み出していく社会
データ・レイクとは何か? ガートナーが解説する企業導入・活用のポイント
https://www.sbbit.jp/article/cont1/32365
データ駆動(データドリブン)型:インテリジェンス時代の重要な意思決定
著者紹介
伊藤忠テクノソリューションズ株式会社
流通・EPビジネス企画室
クラウドインテグレーションビジネス推進部
北川 暢夫
Amazon Web Services(AWS)、Google Cloud Platform(GCP)などのパブリッククラウドを使って、マルチクラウド環境を含めたシステム構築を行っている。
以下のパブリッククラウドの認定資格を保有する。
・Google Cloud Certified - Professional Cloud Architect
・AWS Certified Solution Architect - Professional
・Microsoft Certified Solutions Export : Cloud Platform and Infrastructure
※ Google、Google Cloud Platform、GCP および BigQuery は、Google LLC の商標または登録商標です。
記載内容は掲載当時の情報です。最新情報と異なる場合がありますのでご了承ください。