


Hadoopは、大量のデータを効率よく処理するための仕組みとして考え出されたオープンソースのソフトウェアです。背景には、ブログやSNS、スマートデバイスが普及し、これまで以上に企業が扱うデータが増えたことがあります。大容量データを複数のサーバに分散配置することで、全体の処理にかかる時間を短くしようという思想が根底にあります。
Hadoopが誕生した背景とは

Hadoop Worldでのセッションの様子(2013年 ニューヨーク)
開発者のダグ・カッティング氏はGoogleが開発した分散処理のフレームワークである「MapReduce」と、分散ファイルシステムである「Google File System(GFS)」の二つの技術に触発され、Hadoopを開発しました。このためHadoopはこの二つの技術の性質を大きく受け継いでいます。データを大量に保持しているインターネット企業を中心として利用が進み、今では世界中に利用者やユーザー企業がいます。Hadoopに関する新しい情報発信、共有のため「Hadoop World」も毎年開催されており、利用者間での情報交換の場として盛り上がりを見せています。
カッティング氏が開発したのがオープンソースとして提供されているApache Hadoopです。Apache Hadoopがベースとなり、今では様々な企業が商用のディストリビューションの提供を行っています。
技術的な面から見たHadoopの特徴
次は、技術的な側面からHadoopの特徴について見てみましょう。Hadoopは分散ファイルシステムである「Hadoop Distributed File System(HDFS)」と、分散処理のフレームワークである「MapReduce」の二つから構成されています。
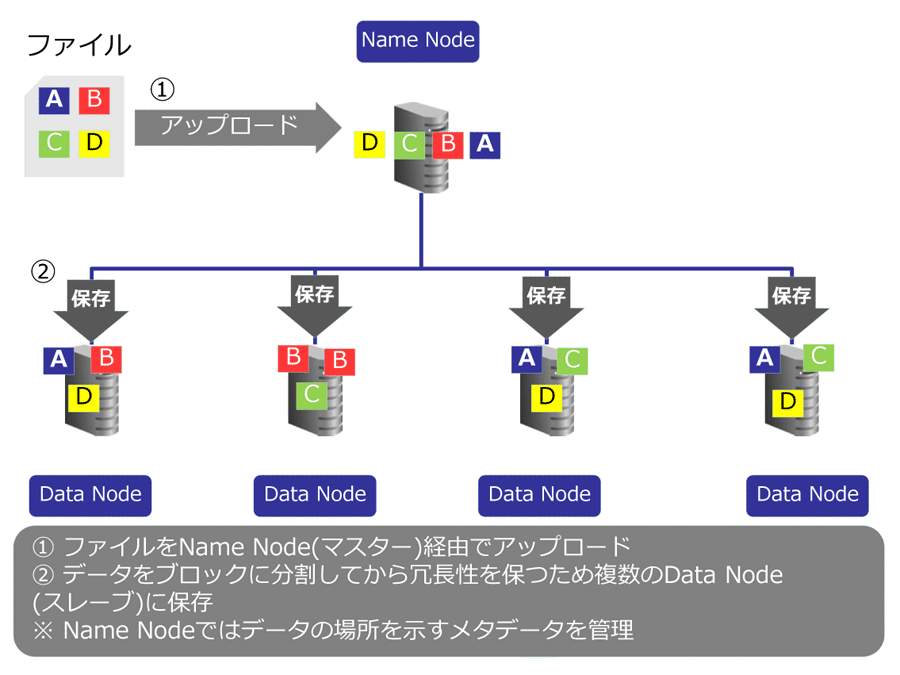
HDFSアーキテクチャ説明図
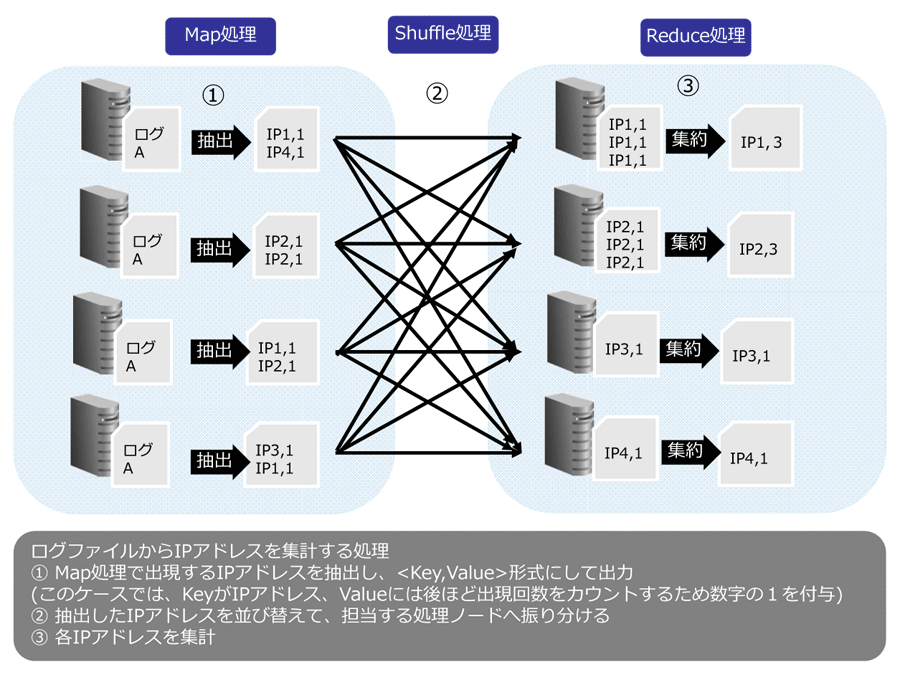
MapReduceアーキテクチャ説明図
データを複数のサーバで分散処理するHadoopは、冗長化の面からも有効です。Hadoopはデフォルトの設定で同一のデータを3つ以上のサーバに書き込むように設計されていることから、単一のサーバに障害が発生して、障害発生ノードにアクセスできなくなったとしても、他のノードからデータを読み込むことで可用性を担保しています。
MapReduceの命名は「Map」タスクと「Reduce」タスクの二つの処理を行うことに由来しています。大まかなイメージとしては、「Map」タスクでは、クラスタ内のデータの中から該当するものを抽出、変換処理を実施し、「Reduce」タスクで抽出した情報を集約して一つの答えとして出力します。これを応用することで、分割、集計、突合、抽出、結合といった様々な処理に活用できます。
このようにHadoopは大量のデータを大規模に集計、解析するようなケースでは非常に力を発揮します。反面、トランザクションを保証しているわけではない、ピンポイントでの更新処理は得意としていません。データベースが得意とするような処理には向きませんので、使いどころには注意する必要があります。
Hadoopはどのように活用されるのか
ではどのような領域でHadoopが活用できるのか、活用シーンの一例を図にまとめてみました。
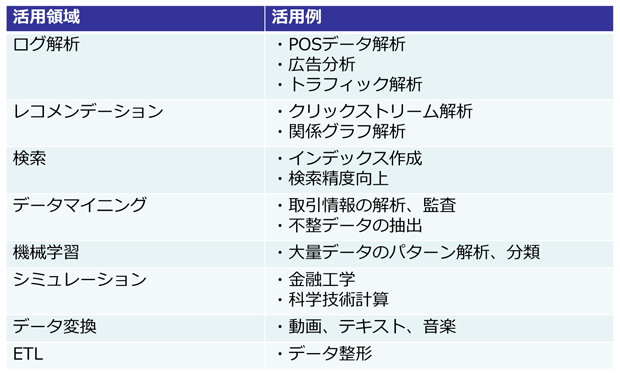
Hadoop活用シーン
大量データを処理して現状の分析を進める、あるいはデータの変換、整形を行うという分野で活用されています。また最近では企業が従来の営業活動で蓄積した社内データに加えて、SNSを始めとする外部のデータと掛け合わせて、顧客の趣向や行動を予測し製品開発やサービスに役立てるといった分野での研究が盛んに行われています。
CTCでは特に、大量データのログを効率よく保管、処理するための仕組みとしてHadoopを活用したログ解析基盤ソリューションを提供しています。Hadoopのスケールアウトの仕組みを利用するため、どこまでデータ量が増えるか分からないようなケースでもスモールスタートすることができ、初期コストを抑えることも可能です。
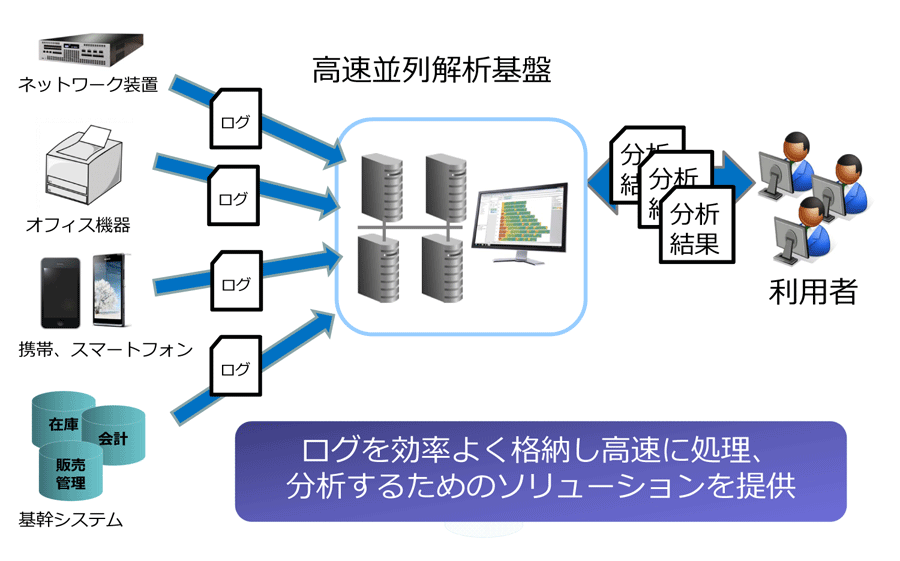
CTC ログ解析ソリューション概要
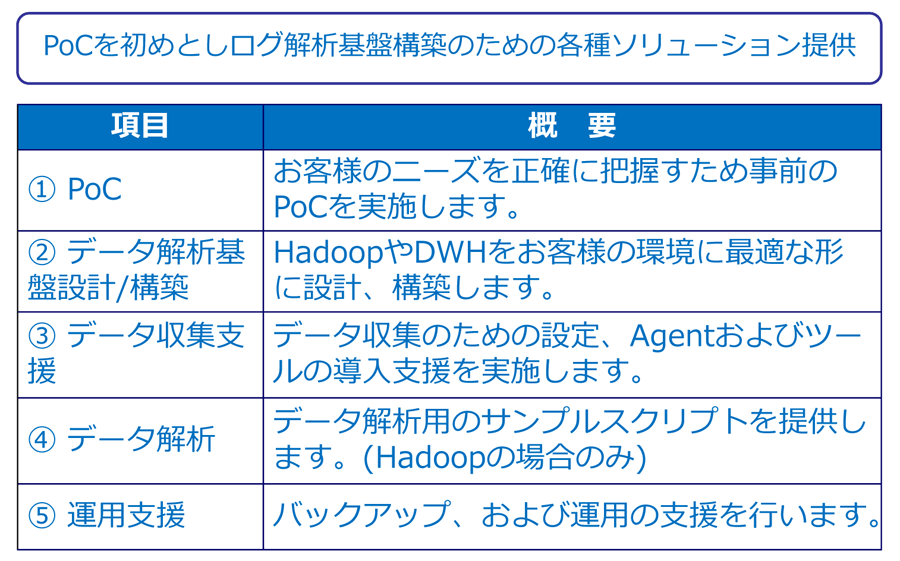
ログ解析ソリューション メニュー
著者紹介

保守・運用サービス事業グループ
ソフトウェアサービス本部
ITソリューションサービス部
小林 範昭